
前一段时间刚接触 Python,为了学习 Python 基础语法,我使用 Python 爬取了北京的网站租房信息,一周前北京的出租房屋还有将近 1.4 万套,然而最近一两天重新爬取数据,发现出租房屋变成了 8 千套,想必大家都可能想到最近发生在什么?好的,废话少说,我们一起来研究研究 Python 爬虫、数据分析等技术,找出地区、放假、出租面积、建筑年代、楼层等因素对出租价格有何影响?
主要分为以下步骤:爬取数据、过滤数据、数据分析、总结。
数据抓取
以北京链家网站作为爬取目标,将 8 月 24 日与 8 月 31 日两次的数据来分析最近一周北京链家房屋出租发生什么情况?
我们爬取某个网站的主要思路:分析网站网页规律 -> 网站反爬机制 -> 根据需求 -> 编码实现。
对于这个网站,基本没有反爬机制,所以我先爬取了这个网站的首页,再抓取每个区域 url,跟主 url 拼接成这个区域的 url,然后循环爬取,依次爬取每个区域的租房信息。在爬取每个区域的房屋信息时,爬取到最大的页码,(如果数据量大于100,如果想要爬取所有该地区的信息,可能需要我们降低维度,比如房租价格),找到了最大的页码,依次爬取每个页面信息的租房信息。
爬取代码如下:
import requests
import time
import re
from lxml import etree
# 获取某市区域的所有链接
def get_areas(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
resposne = requests.get(url, headers=headers)
content = etree.HTML(resposne.text)
areas = content.xpath("//dd[@data-index = '0']//div[@class='option-list']/a/text()")
areas_link = content.xpath("//dd[@data-index = '0']//div[@class='option-list']/a/@href")
for i in range(1,len(areas)):
area = areas[i]
area_link = areas_link[i]
link = url + area_link.split("/")[-2]
print("正在爬取"+link)
get_pages(area, link)
#通过获取某一区域的页数,来拼接某一页的链接
def get_pages(area,area_link):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
resposne = requests.get(area_link, headers=headers)
if re.findall("page-data=\'{\"totalPage\":(\d+),\"curPage\"", resposne.text).__len__()>0:
pages = int(re.findall("page-data=\'{\"totalPage\":(\d+),\"curPage\"", resposne.text)[0])
else:
pages = 0
print("这个区域有" + str(pages) + "页")
for page in range(1,pages+1):
url = area_link+'/pg/' + str(page)
print("开始抓取" + url +"的信息")
get_house_info(area,url)
#获取某一区域某一页的详细房租信息
def get_house_info(area, url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
time.sleep(2)
try:
resposne = requests.get(url, headers=headers)
content = etree.HTML(resposne.text)
title_list = content.xpath("//div[@class='where']/a/span/text()")
if len(title_list)>0:
for i in range(len(title_list)):
title = content.xpath("//div[@class='where']/a/span/text()")[i]
room_type = content.xpath("//div[@class='where']/span[1]/span/text()")[i]
square = re.findall("(\d+)",content.xpath("//div[@class='where']/span[2]/text()")[i])[0]
position = content.xpath("//div[@class='where']/span[3]/text()")[i].replace(" ", "")
try:
detail_place = re.findall("([\u4E00-\u9FA5]+)租房", content.xpath("//div[@class='other']/div/a/text()")[i])[0]
except Exception as e:
detail_place = ""
floor =re.findall("([\u4E00-\u9FA5]+)\(", content.xpath("//div[@class='other']/div/text()[1]")[i])[0]
total_floor = re.findall("(\d+)",content.xpath("//div[@class='other']/div/text()[1]")[i])[0]
try:
house_year = re.findall("(\d+)",content.xpath("//div[@class='other']/div/text()[2]")[i])[0]
except Exception as e:
house_year = ""
price = content.xpath("//div[@class='col-3']/div/span/text()")[i]
with open('data/LianJiaBeijing.txt','a',encoding='utf-8') as f:
print(area + ',' + title + ',' + room_type + ',' + square + ',' + position + ',' + detail_place + ',' + floor + ',' + total_floor + ',' + price + ',' + house_year)
f.write(area + ',' + title + ',' + room_type + ',' + square + ',' +position+','+ detail_place+','+floor+','+total_floor+','+price+','+house_year+'\n')
except Exception as e:
print('网络出现异常')
time.sleep(3)
return get_house_info(area, url)
def main():
#地址为北京链家租房
url = 'https://bj.lianjia.com/zufang/'
#爬取数据
get_areas(url)
if __name__ == '__main__':
main()
数据过滤
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import pandas as pd
with open("data\LianJiaBeijing.txt",encoding='utf-8') as f:
df = pd.read_csv(f,sep=",",header=None,encoding='utf-8',
names=['area','title','room_type','square','position','detail_place','floor','total_floor','price','house_year'])
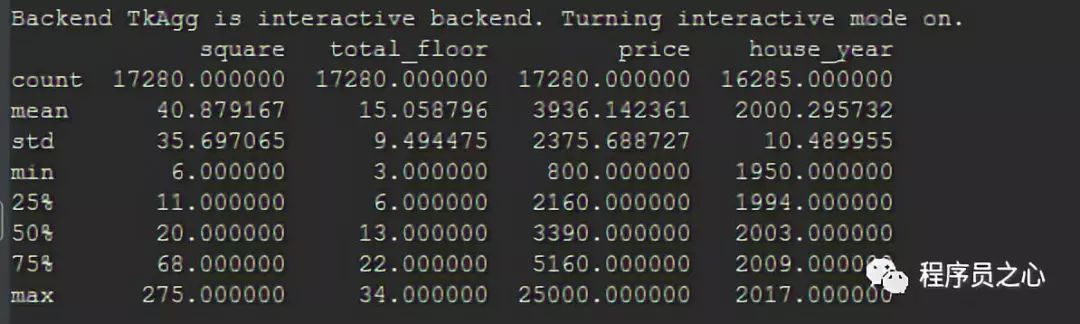
print(df.describe())
8 月 24 日数据如下所示:
数据分析
2018 年 08 月 24 日,主要图表如下所示:
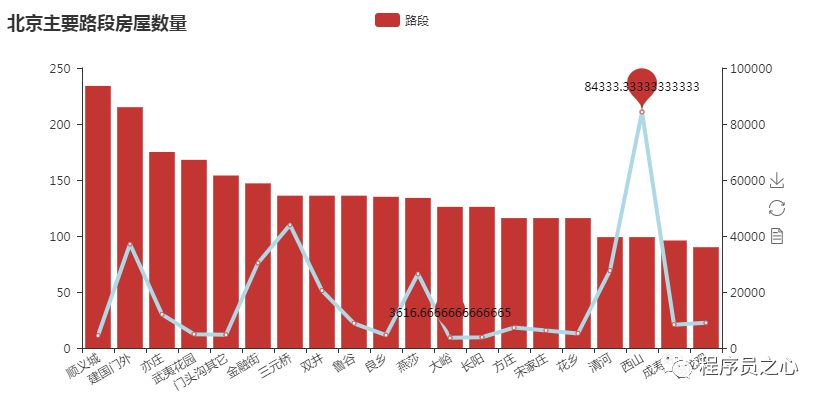
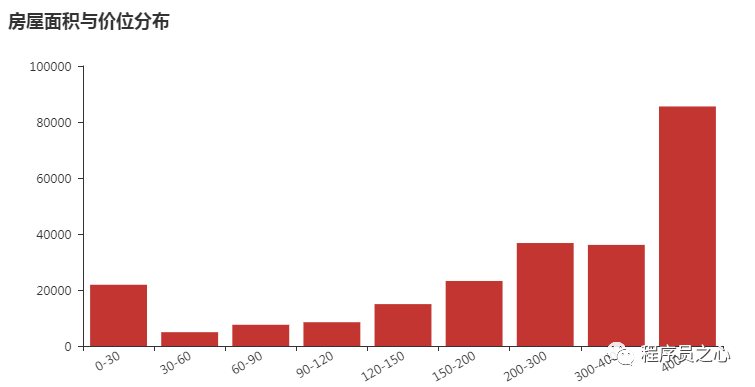
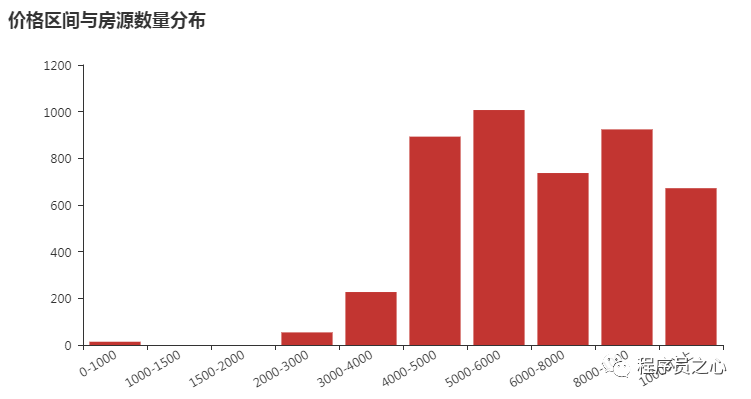
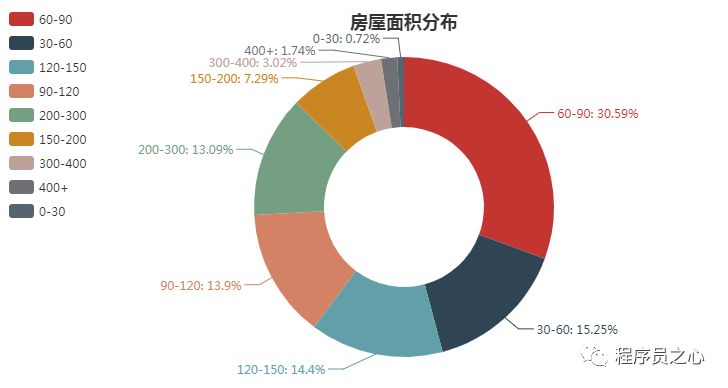 2018 年 08 月 31 日,主要图表如下所示:
2018 年 08 月 31 日,主要图表如下所示:
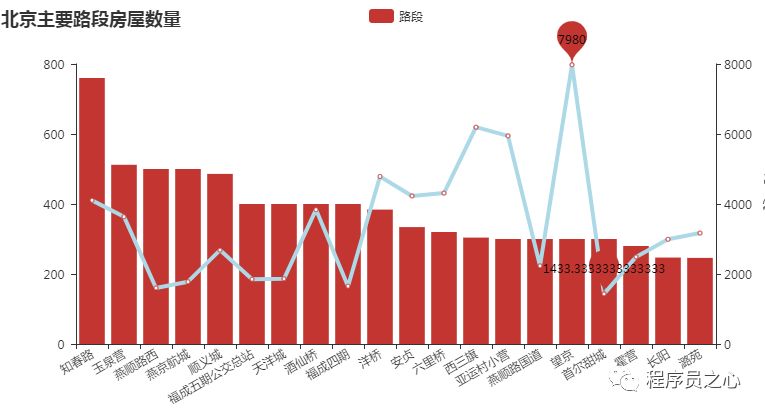
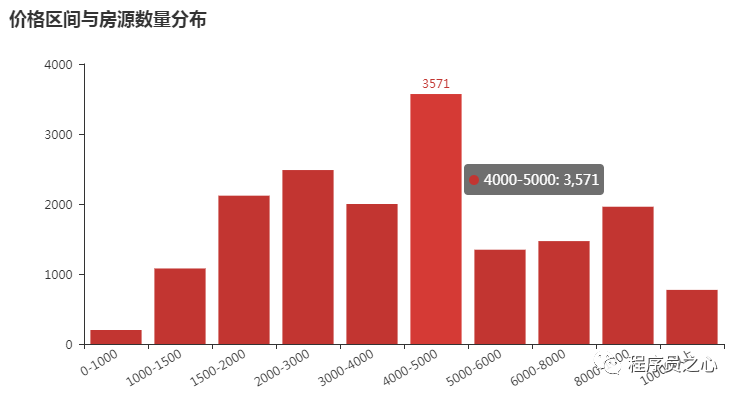
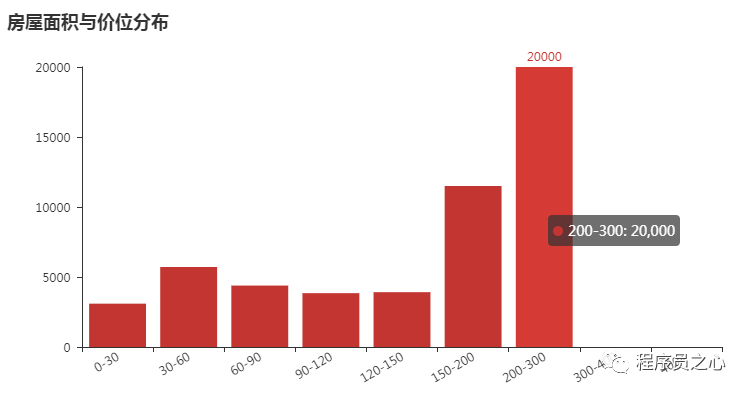
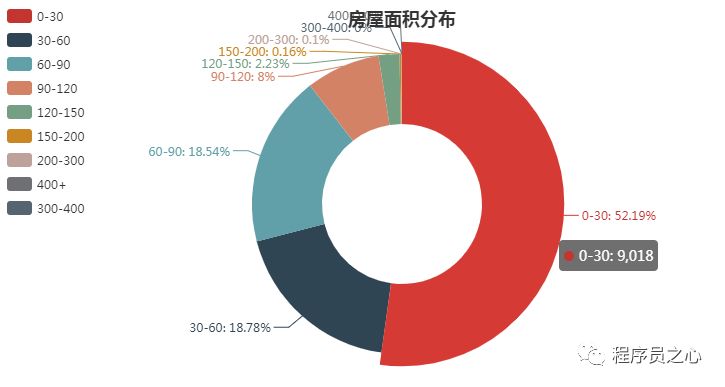
每个地区的区域分布规律(2023 年 08 月 24 日):
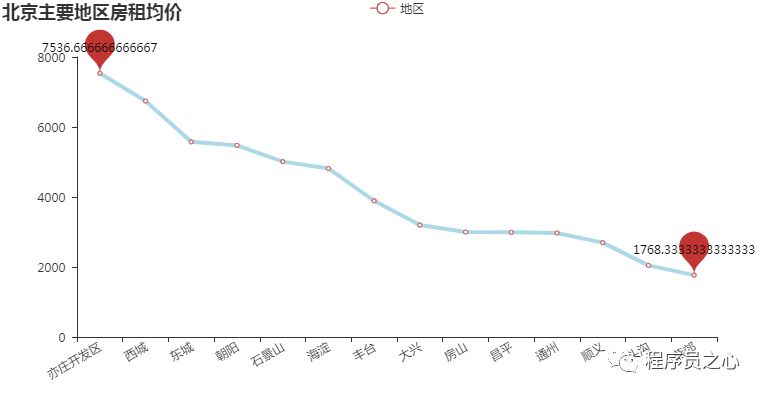 每个地区的区域分布规律(2023 年 08 月 31 日):
每个地区的区域分布规律(2023 年 08 月 31 日):
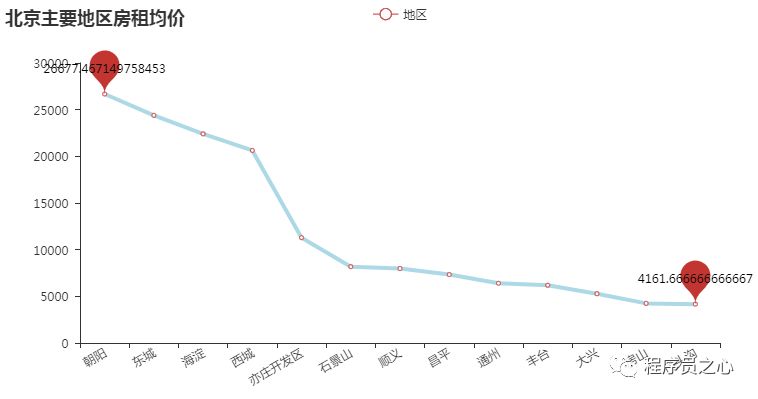
总结
至此,数据的抓取、过滤、分析基本完成,对于我们分析房屋出租有参考意义,由于数据集自身有很多的脏数据,数据集过少,影响因素过多,数据集来源具有不可靠性,所以上述结果与实际情况可能有所出入,但是总体情况还是可以参考的。看到了这些,你有什么想法呢?
