调查

- 没有使用 Kubernetes 管理业务应用?
- 没有使用 Service Mesh 进行服务治理?
主要是做一个小调查,在生产环境没有使用 Kubernetes 进行容器应用编排,没有使用 Service Mesh 进行服务流量治理?
服务网格架构

随着云原生和微服务的发展,服务网格应运而生,我们通常将以服务网格为核心的架构称为云原生微服务架构。

云原生微服务架构具有以下四个特性:具备弹性计算资源;具备原生微服务基础能力;服务网格统一流量调度;解决多语言 RPC 治理和升级问题。此外,服务网格的落地能够更好地实现微服务的安全管控和稳定性治理。然而,服务网格同样不是银弹,并不能解决所有问题。云原生微服务架构下,Sidecar 增加了系统与运维的复杂性,部分社区实现性能表现不佳还会带来显著的微服务通信时延,组件多语言 SDK 的问题仍然存在且十分严重,缺乏传统微服务与现代服务网格应用过渡态等问题,传统微服务面临的问题举例如下所示:
- 框架学习成本与门槛高、各个框架服务治理功能不全、支持语言单一,不具有语言无关性。比如,百度内部常用的微服务框架有 BRPC(C++)、Spring Cloud 生态(Java)、RAL 框架(PHP)、GDP(Golang) 等。业务模块大量使用 C++、Java、Golang、PHP 等语言进行开发,业务模块之间通信除了使用 HTTP、GRPC 协议进行通信外,还有大量的私有协议,如 baidu_std、streaming_rpc、nshead 等。
- 开发框架 SDK 侵入性强、升级困难与成本高、版本统一困难。SDK 与业务进程耦合,SDK 版本升级或者服务治理策略调整成本高,需要推动业务配合。
- 服务应用可观测性不足,业务缺乏整体模块调用关系链和流量视图,故障问题定位效率低。

我们知道一项新技术的发展基本都是会符合技术成熟度曲线(The Hype Cycle)规律的,服务网格也不例外。科技诞生的促动期->过高期望的峰值->泡沫化的底谷期->稳步爬升的光明期->实质生产的高峰期。
服务网格概念最早从 2017 年被提出,2018 年正式爆发,进入服务网格技术元年,之后随着众多云厂商纷纷入局,2022-2023 年服务网格也达到了准成熟度曲线的期望顶峰点,开始进入准成熟期。如果要总结现在服务网格的话,那就是技术日趋成熟,生态逐步完善,市场更加理性,回归价值本身。
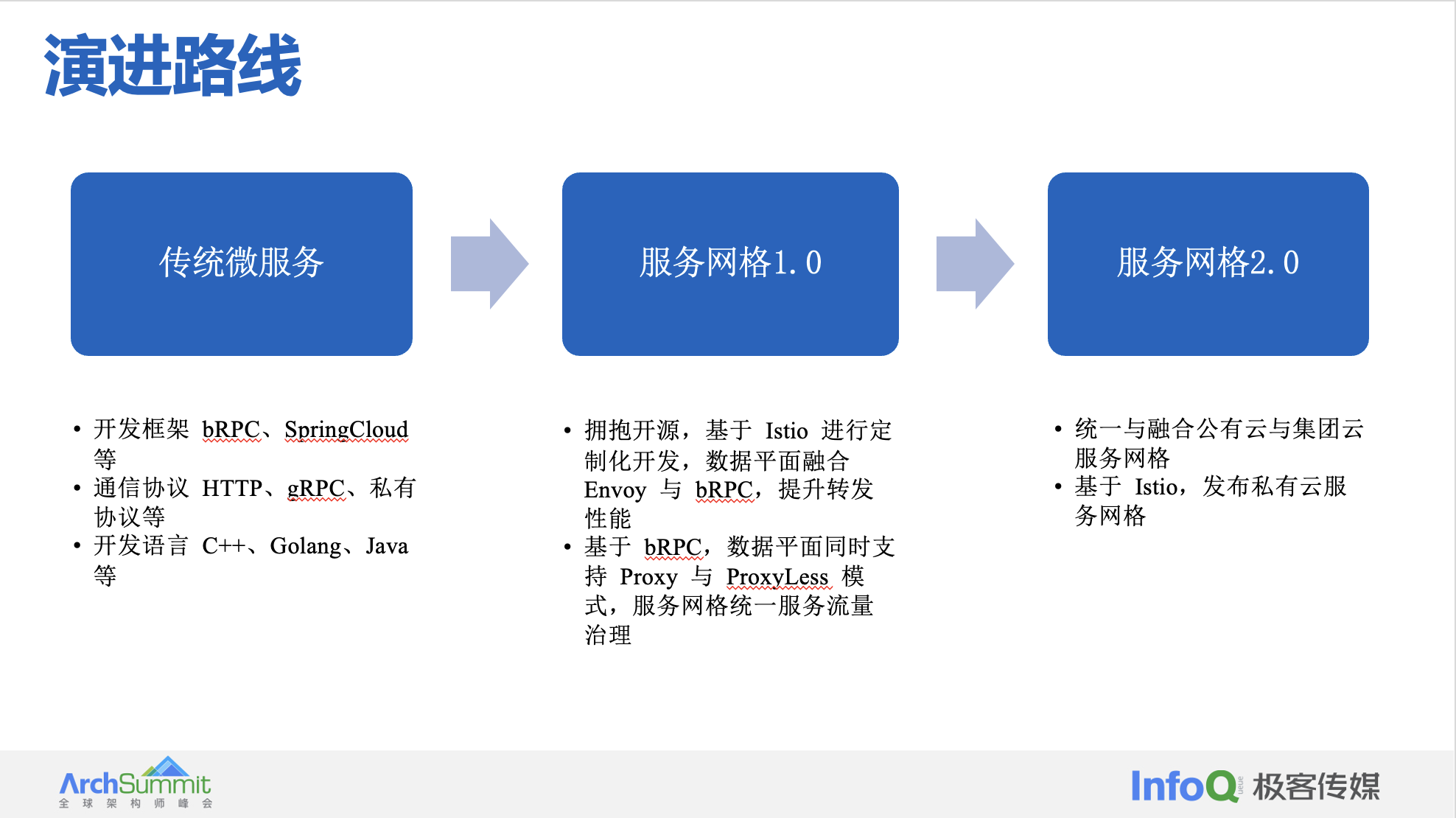
演进路线

从之前百度服务网格相关对外分享来说,内部大规模落地 Service Mesh 主要是适配与协同内部 PAAS、服务开发框架、RPC、服务发现系统等平台,进行深度定制开发,魔改 istio 源码(兼容内部基础设施),从而提供一种 极致性能、低成本、零改造 突出 Service Mesh 红利的服务网格解决方案。目前百度服务网格落地实践主要经历过传统微服务、1.0 时代、2.0 时代,如下所示:
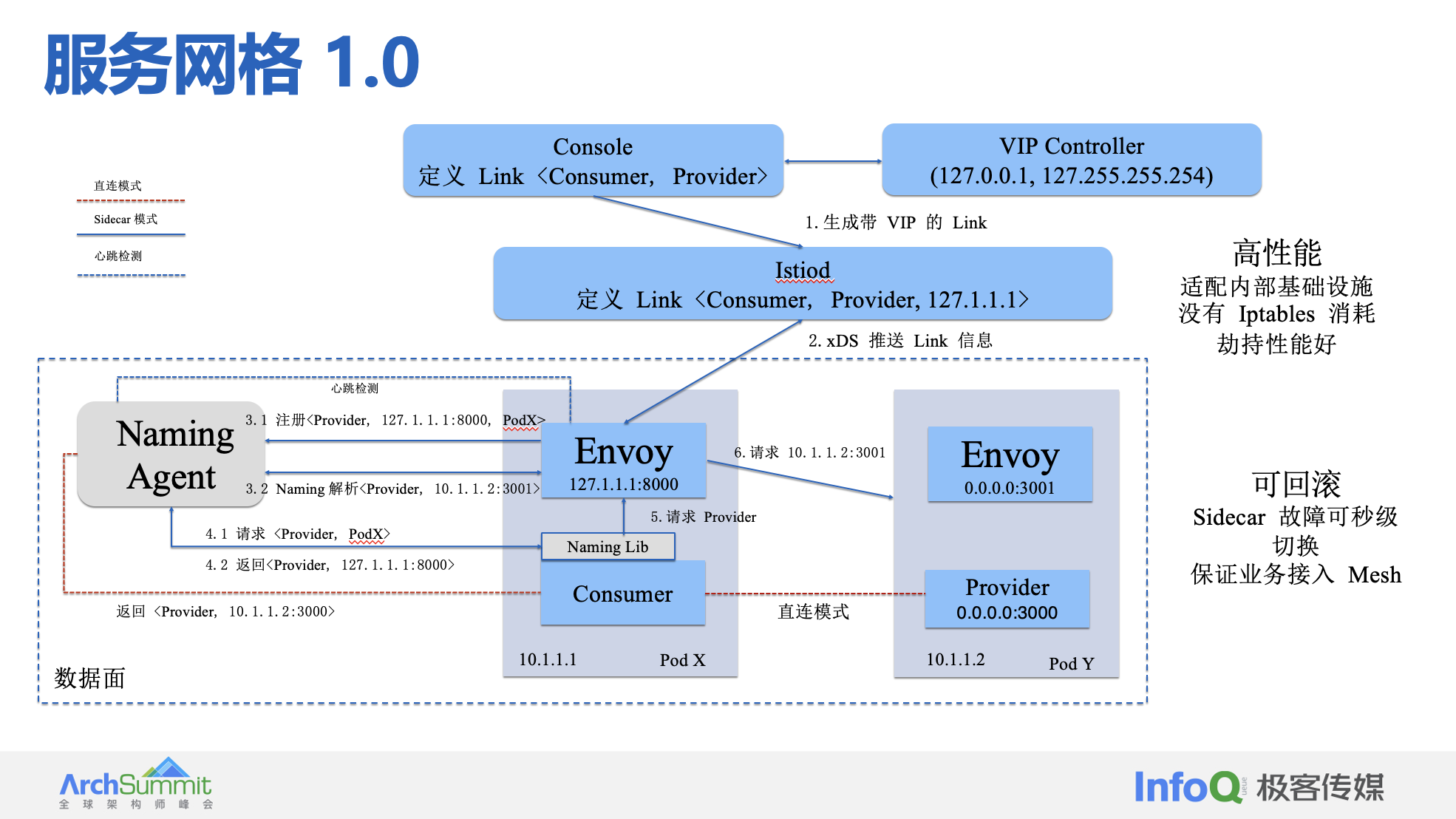
1.0 时代如下所示:

2.0 时代如下所示:

产品架构
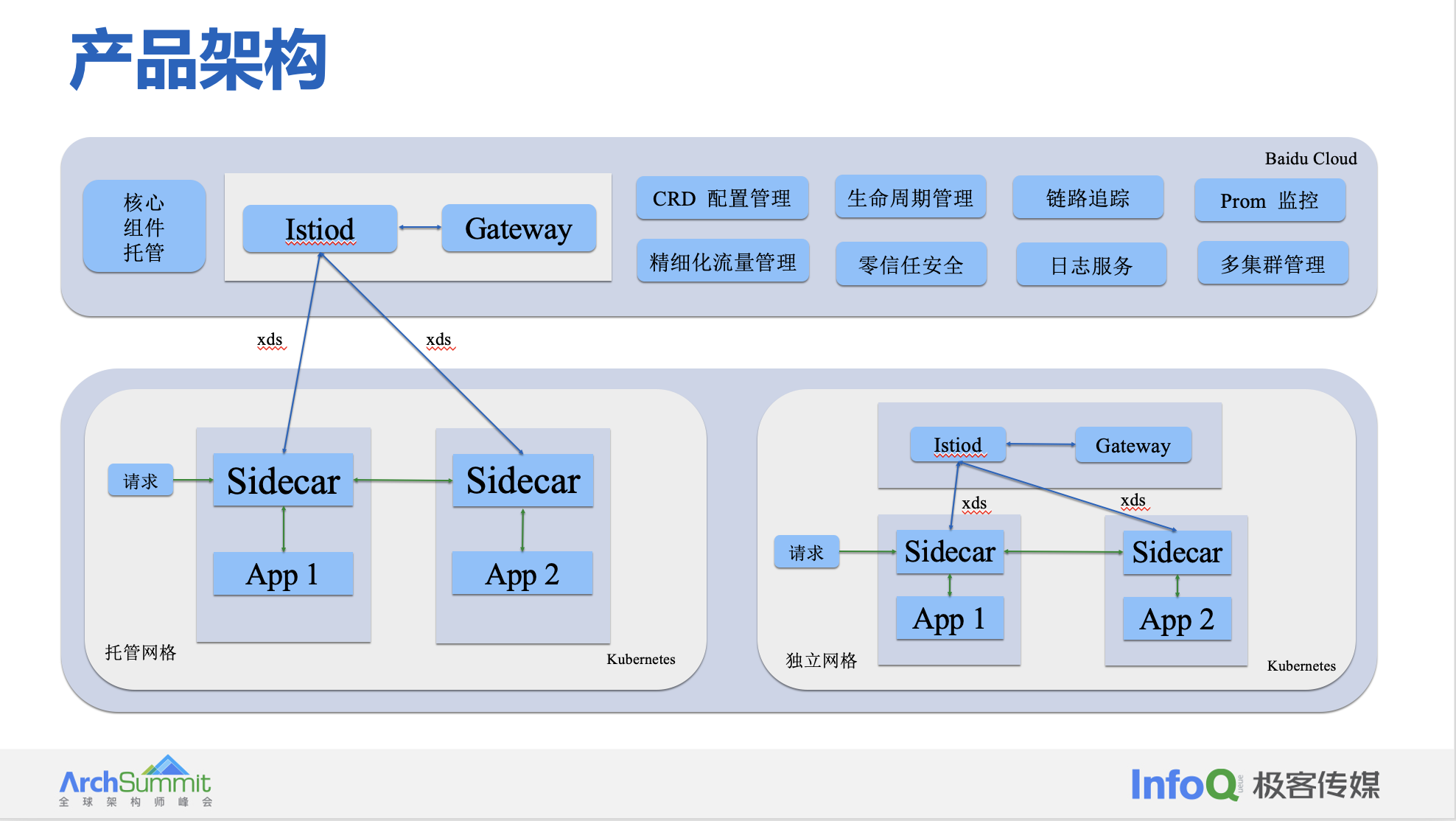
我们面对标准化与私有化场景,这种内部定制化产品对外其实很难去推广与落地的。因此,我们需要提供一种既能支撑内部对于接入 Mesh 高性能、低成本的要求,也可以满足对外公有云与私有化 Mesh 落地需求,突出 Mesh 优势的服务网格产品。在支撑内部业务接入 Mesh 的同时,将内部 Mesh 落地的许多总结与经验赋能于外部公有云与私有化客户。后续在融合的过程中主要关注于以下几点:稳定性、扩展性、易用性、功能丰富度以及性能。
运维管理
控制平面
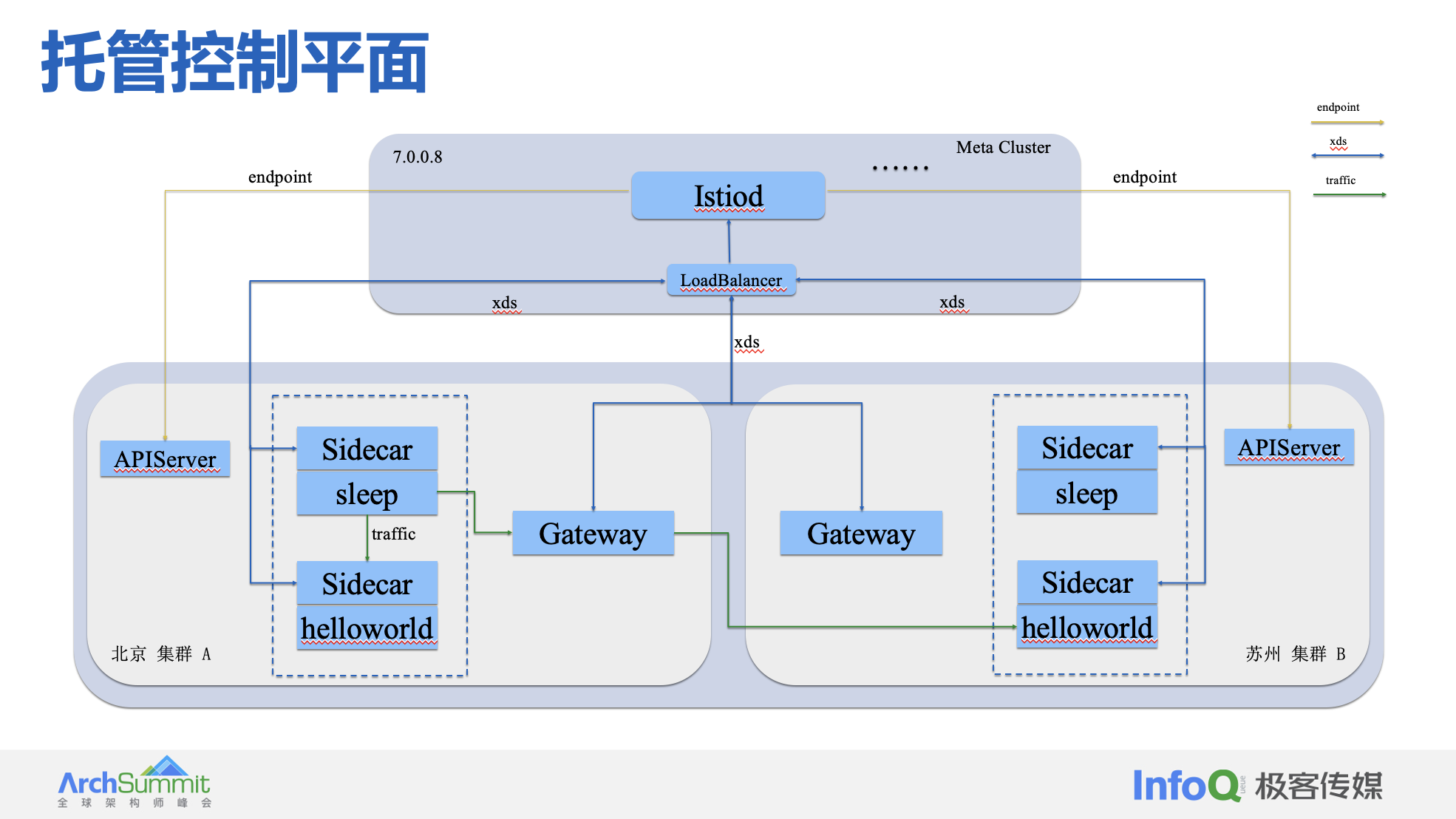
我们知道在 istio 标准的架构中,istiod 与 istio crd 等相关的 config 配置需要与业务集群部署在一起,而往往使用 Mesh 的操作人员可能不太熟悉 Mesh。一旦出现问题,我们很难去定位问题,我们作为基础设施提供方,往往需要用户集群相关权限,运维压力较大。其实,我们完全可以不向用户暴露 Istiod,业务使用方只需关注是否选择注入 Sidecar 即可,因此我们设计了完全兼容开源社区托管控制平面这种产品形态,可提供低运维、可操作、易用性等优势。给用户提供专业性控制平面运维,极力提升用户控制平面的稳定性。
全托管版本中,在用户集群不会有任何控制面相关组件,所有组件都由平台托管。如果对 istio 有很多个性化的需求场景,比如说公司内部的私有协议,要进行深度研究与定制化,同时对 istio 也有足够的理解和技术投入,可以考虑独立网格。如果业务方对 istio 缺乏运维人力,希望更高效快速的接入 istio,又或者希望由平台来提供高可用的控制面,那么应该选择托管版本。
多实例

我们知道 Kubernetes 社区 Multi-Tenancy Working Group 定义 3 种 Kubernetes 多租户模型,Namespace as a Service (NaaS)、Cluster as a Service (CaaS)、Control Planes as a service (CPaaS),这些模型侧重于不同的场景。 第一种是 Namespaces as a Service,这种模型是多个租户共享一个 Kubernetes 集群,每个租户被限定在自己的 Namespace 下,借用原生的 Namespace 的隔离性来实现租户负载的隔离租户一般只能使用 Namespace 级别的资源,不能使用集群级别的资源,它的 API 兼容性比较受限。

后两种模型分别是 Clusters as a Service 以及 Control planes as a Service, 这两者都属于租户间做物理集群隔离的方案。每个租户都有独立的 Master,这个 Master 可能会通过 Cluster API 或 Virtual Cluster 等项目完成它的生命周期管理。Master 是独占的物理资源,因此每个租户都会有一套独立的控制面组件,包括 API Server、Controller Manager 以及自己的 Scheduler,每个组件还可能会有多个副本。在这种方案之下,租户之间是互相不影响的。

Istio 依托于 kubernetes namespace 多租户隔离能力,可实现 “soft-multitenancy”,即单一 Kubernetes 控制平面和多个 Istio 控制平面与多个服务网格相结合,每个租户都有自己的一个控制平面和一个服务网格实例。
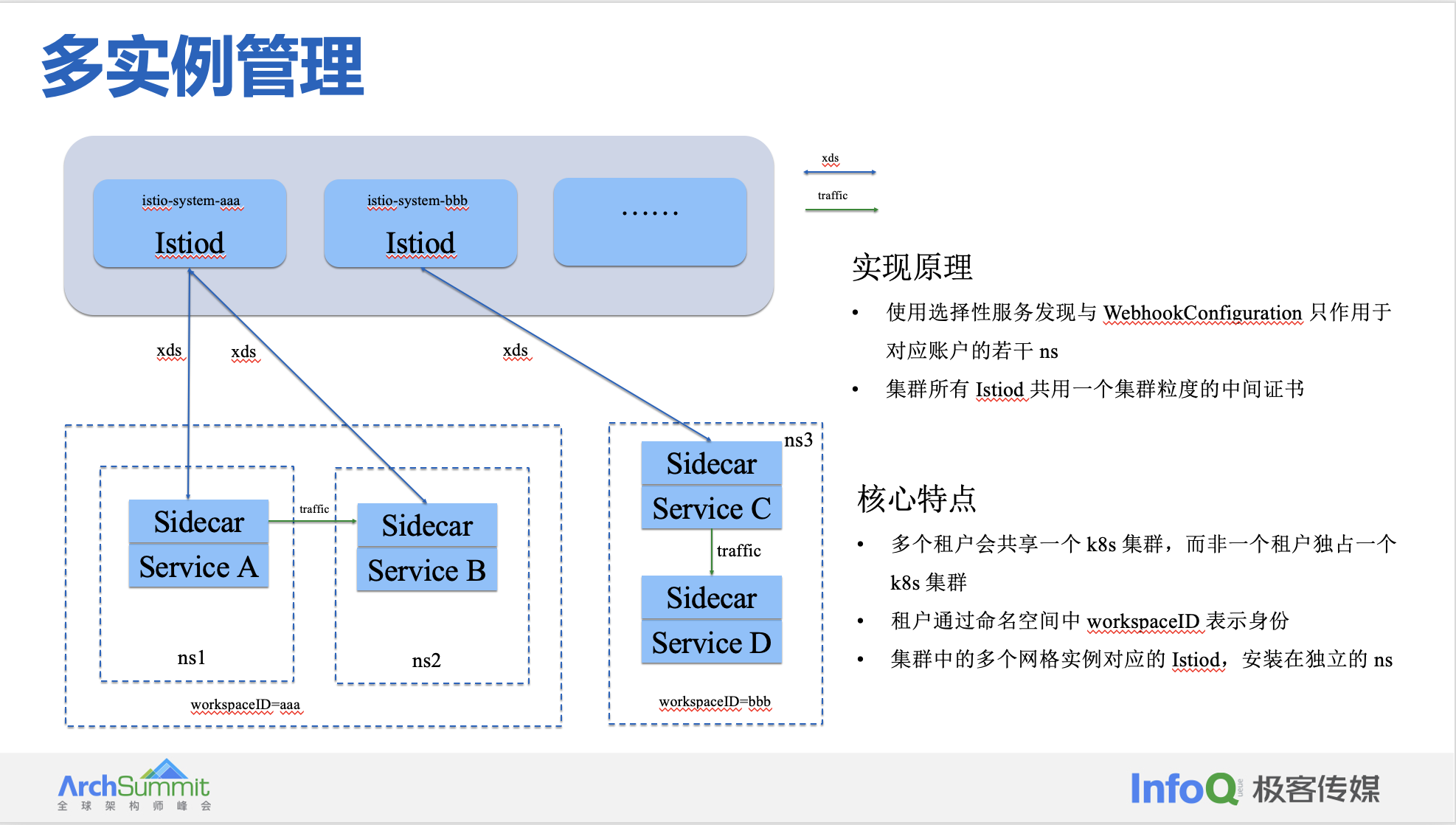
- 多个租户会共享一个 k8s 集群,而非一个租户独占一个 k8s 集群
- 租户通过命名空间中 workspaceID 表示身份
- 集群所有 Istiod 共用一个集群粒度的中间证书
- 集群中的多个网格实例对应的 Istiod,安装在独立的 ns
- 使用选择性服务发现与 WebhookConfiguration 只作用于对应账户的若干 ns
云原生网关

随着容器化技术和云原生应用的逐渐普及,在 Kubernetes 重塑运维体系的云原生时代。曾经炙手可热的 SpringCloud Gateway/Kong/Nginx 等在其网关位置上开始显得力不从心,它们欠缺容器服务发现的能力,在可观测性、安全等方面都需要二次开发与集成,这些关键短板都阻碍着网关的技术发展。此时,云原生网关应运而生,云原生网关不仅集齐了他们的优点,而且功能更丰富、性能更强劲、稳定性更可靠。nginx 缺乏统一的管控平面,配置变更时流量有损。
作为新一代网络代理软件,Envoy 原生具备了非常丰富的特性,能够满足大部分业务场景流量治理的需求,具有如下优势:
- 原生功能丰富:相较于 Nginx、HAProxy 提供流量代理所需的基本功能(更多高级功能通常需要通过扩展插件方式实现或购买商业版,Envoy 本身基于 C++ 已经实现了相当多代理所需高级功能,如高级负载均衡、熔断、限流、故障注入、流量复制等。更为丰富的功能不仅让 Envoy 天生就可以用于多种场景,原生 C++ 的实现相较于经过扩展的实现方式性能优势更为明显。
- 易观察:相比于 Nginx、HAProxy 等传统代理软件,Envoy 具备更好的可观察性,包括灵活可定制的日志,丰富的指标监控,原生的多种分布式跟踪协议支持等等。
- 自主可控:Envoy 的社区完全开放,不存在对应的商业版本,所以不用担心部分高级功能会被锁死在类似开源对应的商业版当中。同时,Envoy 社区非常活跃,在 Envoy 使用过程中的问题或者新的功能需求向社区提出后都可以得到很快的反馈。
- 动态配置:xDS 协议的提出使得 Envoy 几乎所有的配置都可以动态的下发、加载和生效,而无需重新加载进程。并且 xDS 协议已经成为了构建通用数据面接口协议(UDPA)的基础。
- 易扩展:Envoy 提供了 L4/L7 Filter 机制,可以让开发者在不侵入 Envoy 主干的前提下在各个层级对 Envoy 进行扩展和增强。不止于此,Envoy 的 WebAssembly 多语言扩展沙箱,可以支持使用 C++、Golang、JS 等语言扩展能力。
- 多协议:Envoy 支持代理多种 L7 协议数据,包括 HTTP,Kafka,gRPC,Dubbo,MongoDB 等等。因为 Envoy 所有的协议解析和治理都是使用 Filter 来实现的,此类多协议治理能力其实也是构建在 Envoy 强大可扩展性上的,基本上每一种协议代理能力都对应一个 L4 Filter。
blb-nginx 与 Envoy 测试对比如下所示:
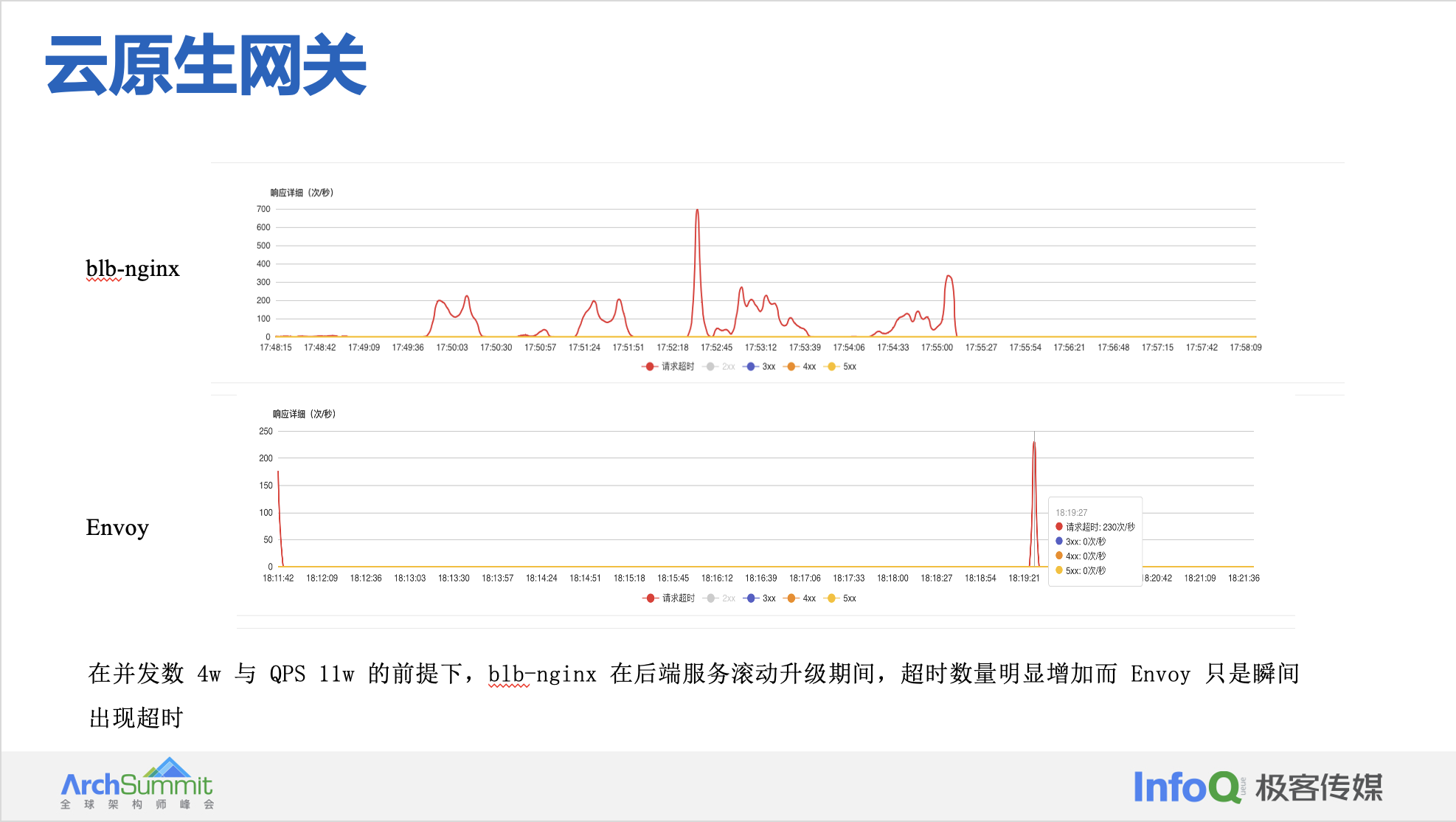
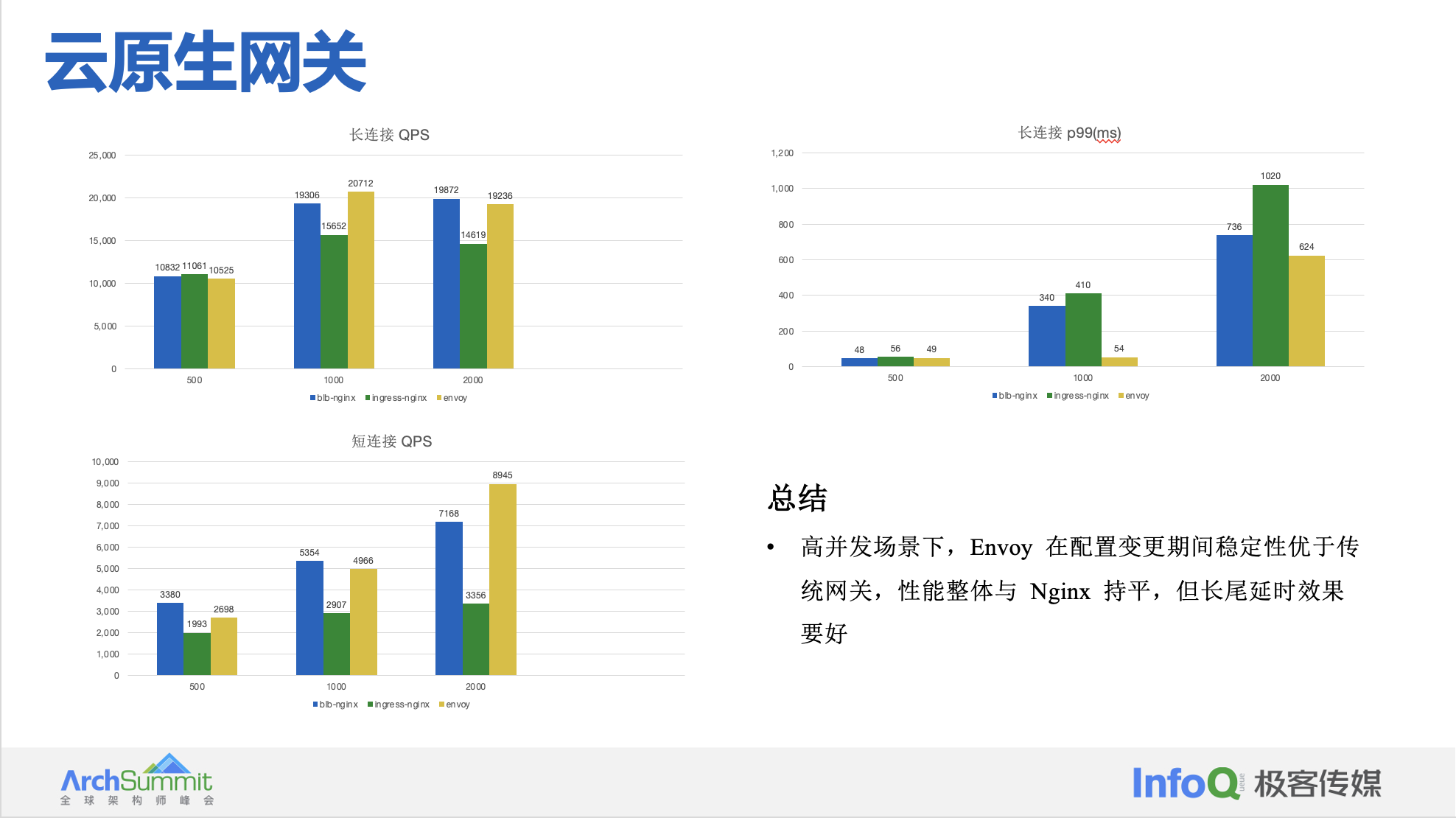
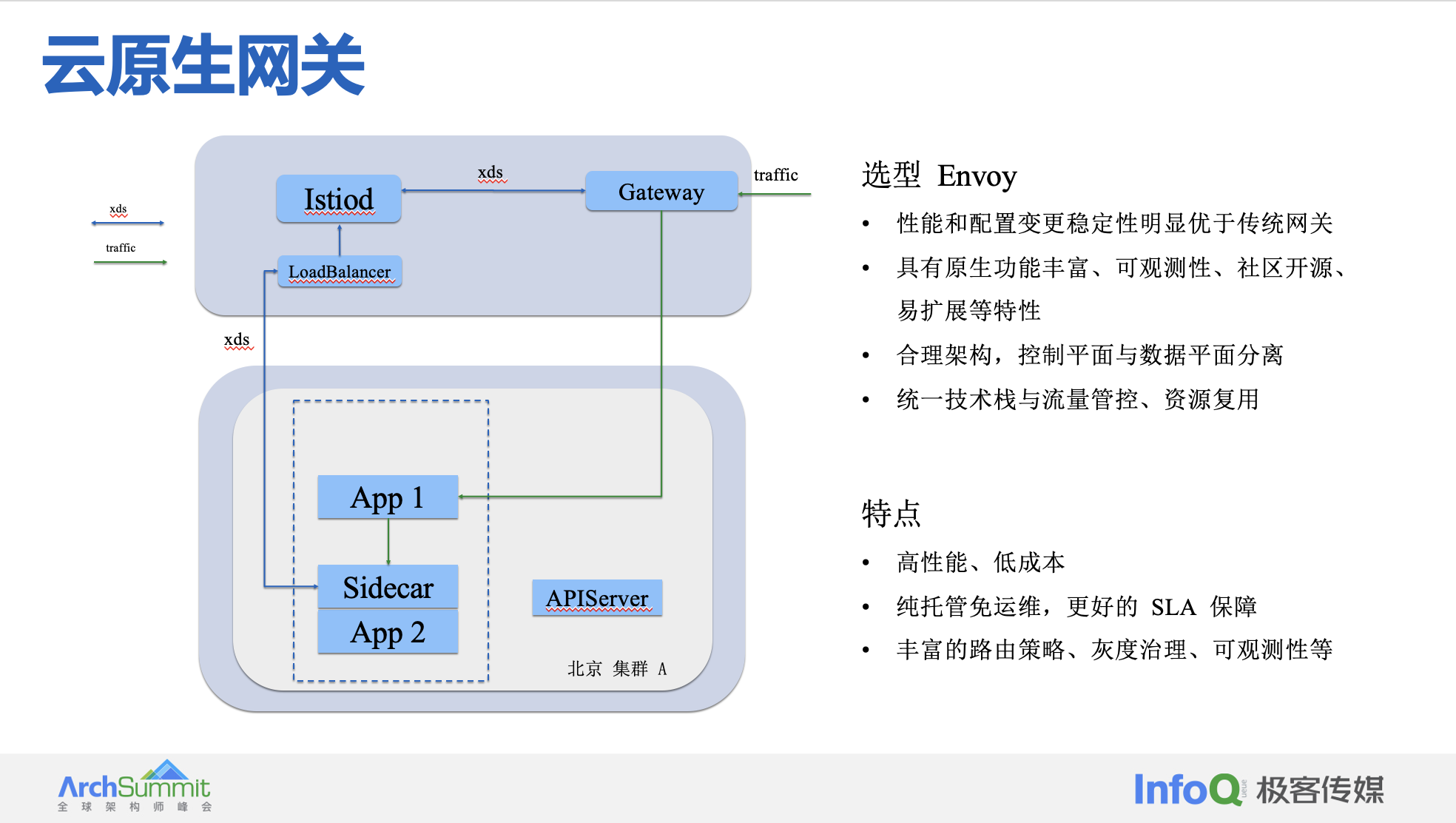
选型 Envoy:
- 性能和配置变更稳定性明显优于传统网关
- 合理架构,控制平面与数据平面分离
- 具有原生功能丰富、可观测性、社区开源、易扩展等特性
- 统一技术栈与流量管控、资源复用
性能对于网络代理软件来说是一个非常重要的指标。Envoy 在原生具备丰富特性的同时,也有着非常优秀、足以媲美 Nginx 与 HAProxy 的性能表现。难能可贵的是,除了基本路由代理功能外,众多其他功能由于原生 C++ 实现,相较于 Nginx、HAProxy 等通过扩展脚本实现主要功能的方式,性能优势更为明显。
性能优化
延迟加载

服务网格在引入 sidecar 代理之后原本的单次服务调用基础上又增加了两跳带来了额外的延迟,当请求链路较长时这种延迟则更加严重,尤其是延迟敏感的业务。虽然 sidecar 代理的已经足够快了,但是仍未满足业务对延迟永不满足的追求。由于 sidecar 的引入,额外的资源占用不可避免,尤其是大规模部署的云端以及资源受限的边缘场景。处于成本控制和环境限制的考虑,数据面的资源占用也成为选择服务网格的重要指标。我们对 Istio 的性能短板做了持续的优化,这主要包括两方面,控制平面与数据平面。控制平面主要做了一些参数调优、xds 按需下发、选择性服务发现等。数据平面主要是 TLS 加速、优化 Envoy 与融合 bRPC、eBPF 加速内核协议栈等。

我们知道在社区 istio 版本中,xDS 是 istio 控制面和数据面 envoy 之间的通信协议,可以简单的把 xDS 理解为网格内的服务发现数据和治理规则的集合,xDS 数据量的大小和网格规模是正相关的。在社区 Istio 中,控制平面默认会给 Envoy 下发所有的 istio config 配置。如果集群规模大,会严重影响 xds 配置计算与下发,容易导致控制平面资源消耗过大,处理时间变长。对此我们进行了优化,通过手动或者自动定义 Sidecar 配置减少 XDS 配置项,实现按需下发,减少 istiod 控制平面计算时间与降低 Envoy 资源消耗。
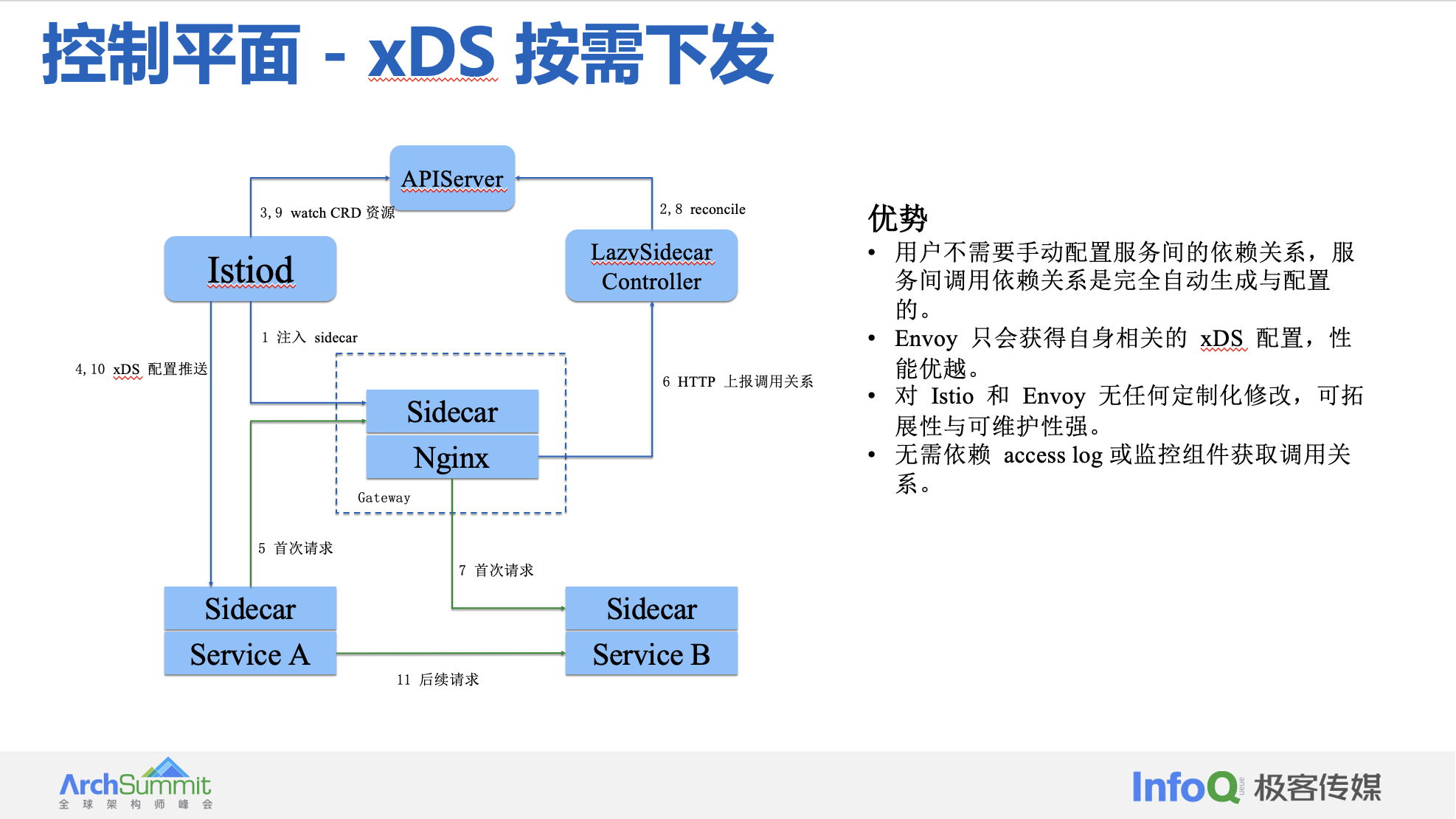
主要实现步骤如下所示:
- 为注入 sidecar(envoy) 的工作负载创建初始 Sidecar CRD(通过LazySidecar CRD 调谐实现),并对 EnvoyFilter CRD 进行 patch,使 VirtualOutbound Listener 的默认七层协议路由指向 LazySidecar Gateway,四层协议路由到 Passthrough Cluster;
- 当 Workload1 首次请求 Service2 时,根据 envoy 的配置信息重定向到 LazySidecar Gateway;
- LazySidcar Gateway 由注入了 sidecar 的 Nginx 实现,并配置 Lua 脚本。当收到请求时,Lua 脚本会解析源(Workload1)和目的(Service2)信息,并通多 HTTP 调用传递到 LazySidecar Controller;
- LazySidecar Controller 负责接收调用链信息,并更新 LazySidecar CRD;
- LazySidecar CRD 更新后会调谐 Sidecar CRD,并更新到 Istiod 配置;
- Istiod 将最新配置信息推送到 Workload1 的 envoy,使 Workload 1 感知到 Service2,同时 EnvoyFilter CRD 自动增加 Service2 相关的 Listener;
- 当 Workload1 第二次请求 Service2 时,会根据 envoy 的配置信息直接访问到 Service2。
上述实现方式有如下优势:
- 用户不需要手动配置服务间的依赖关系,服务间依赖关系是允许动态增加的。
- 用户操作较简单,只关注 LazySidecar CRD 即可。
- envoy 只会获得自身需要的 xDS,性能最优。
- 该方案对 istio 和 envoy 没有任何修改,可拓展性与可维护性较强。
- 无需依赖 access log 或监控组件获取调用关系。
另一种是社区提供的选择性服务发现功能,默认情况下,数据平面的 Sidecar 中保存数据平面集群中任意命名空间内所有服务的相关信息(即使该命名空间内的工作负载并未注入Sidecar。同时,控制平面也会监视网格中来自所有命名空间内的服务,任何与服务相关的变更都会引起控制平面向所有Sidecar推送相关配置。可以使用选择性服务发现范围配置功能,根据数据平面集群内命名空间的标签来制定若干标签选择器。标签选择器保证控制平面只需要发现和处理指定命名空间下的应用服务。Sidecar 配置内将仅保留被选中命名空间内的服务信息,未被选中的命名空间内的服务发生改变,将不会引起 Sidecar 的配置推送。
TLS 加速
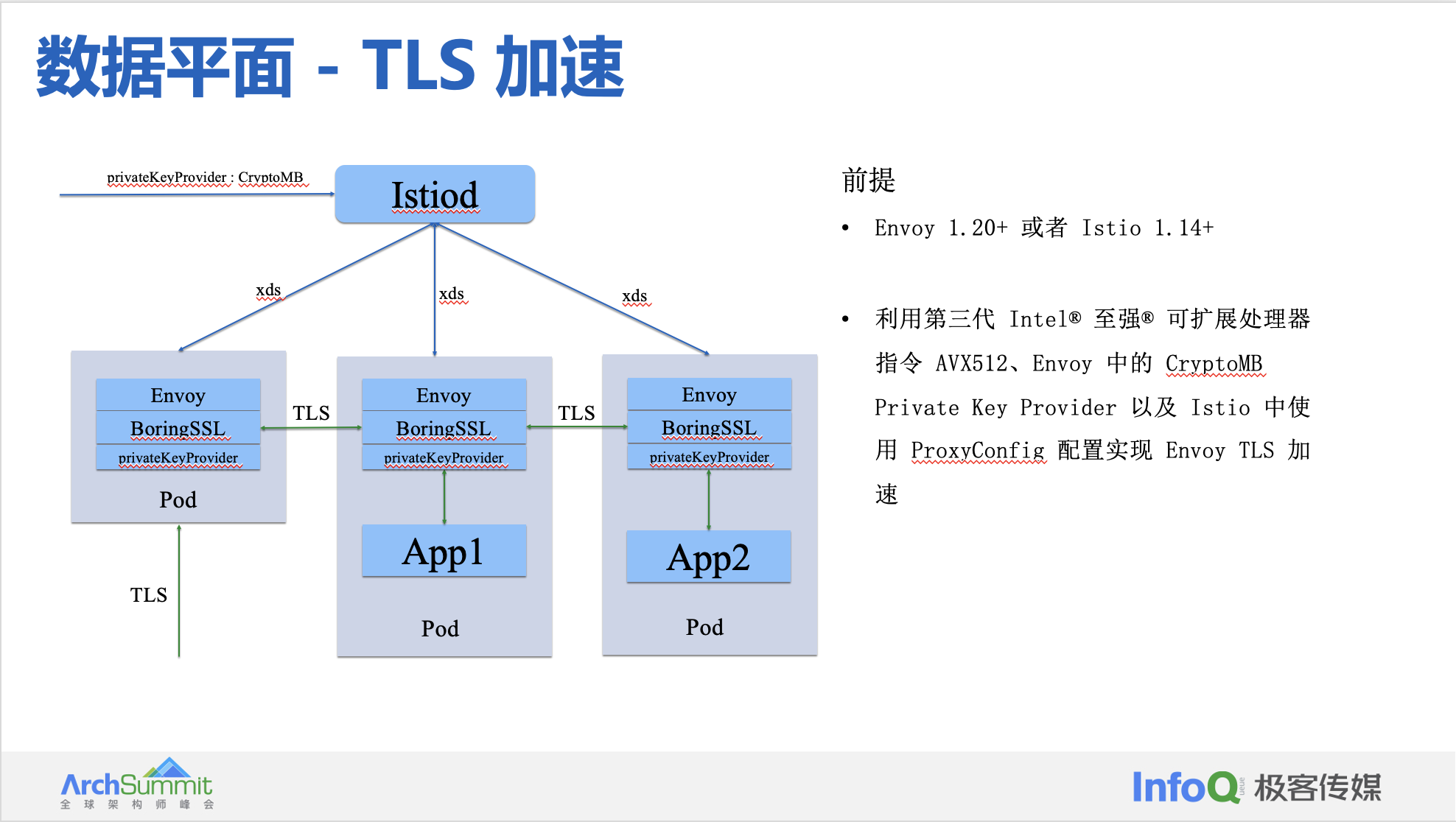
为了提升网络传输的安全性,HTTPS 已经开始逐步取代HTTP,而两种协议最关键的不同在于HTTPS多了一层 SSL (Secure Sockets Layer 安全套接层)或 TLS (Transport Layer Security 安全传输层协议)对传输数据进行加密处理。但TLS在提升传输安全性的同时,其握手阶段执行的非对称加解密操作也增加了对CPU计算资源的消耗,尤其作为入口流量网关需要处理大量的HTTPS请求,将使之在大规模的微服务场景下可能会成为一个性能瓶颈。我们主要结合 Sidecar 与 Intel Xeon 三代处理器的 AVX-512(Advanced Vector Extensions 512) Multi-Buffer 加解密技术,实现对 TLS 过程的加速处理。
Intel 有两种用于加解密的技术,可以加速 TLS 的处理过程:
- QAT。全称是 QuickAssist Technology。它主要包含了加解密和压缩解压缩的功能。QAT 本身提供了对应的驱动程序和底层的 Library。QAT 功能是通过额外的 PCI 设备提供给用户使用的(在 Intel 最新的四代芯片中会把QAT的能力直接嵌入到CPU当中)。
- Multi-Buffer。这种技术的原理是使用 AVX-512 指令同时处理多个独立的缓冲区,即可以在一个执行周期内同时执行多个加解密的操作,加解密的执行效率便会得到成倍的提升。Multi-Buffer 技术不需要额外的硬件,只需要 CPU 包含特定的指令集即可。在 2021 年发布的 Ice Lake 处理器中已经包含了最新的 AVX-512 指令集。
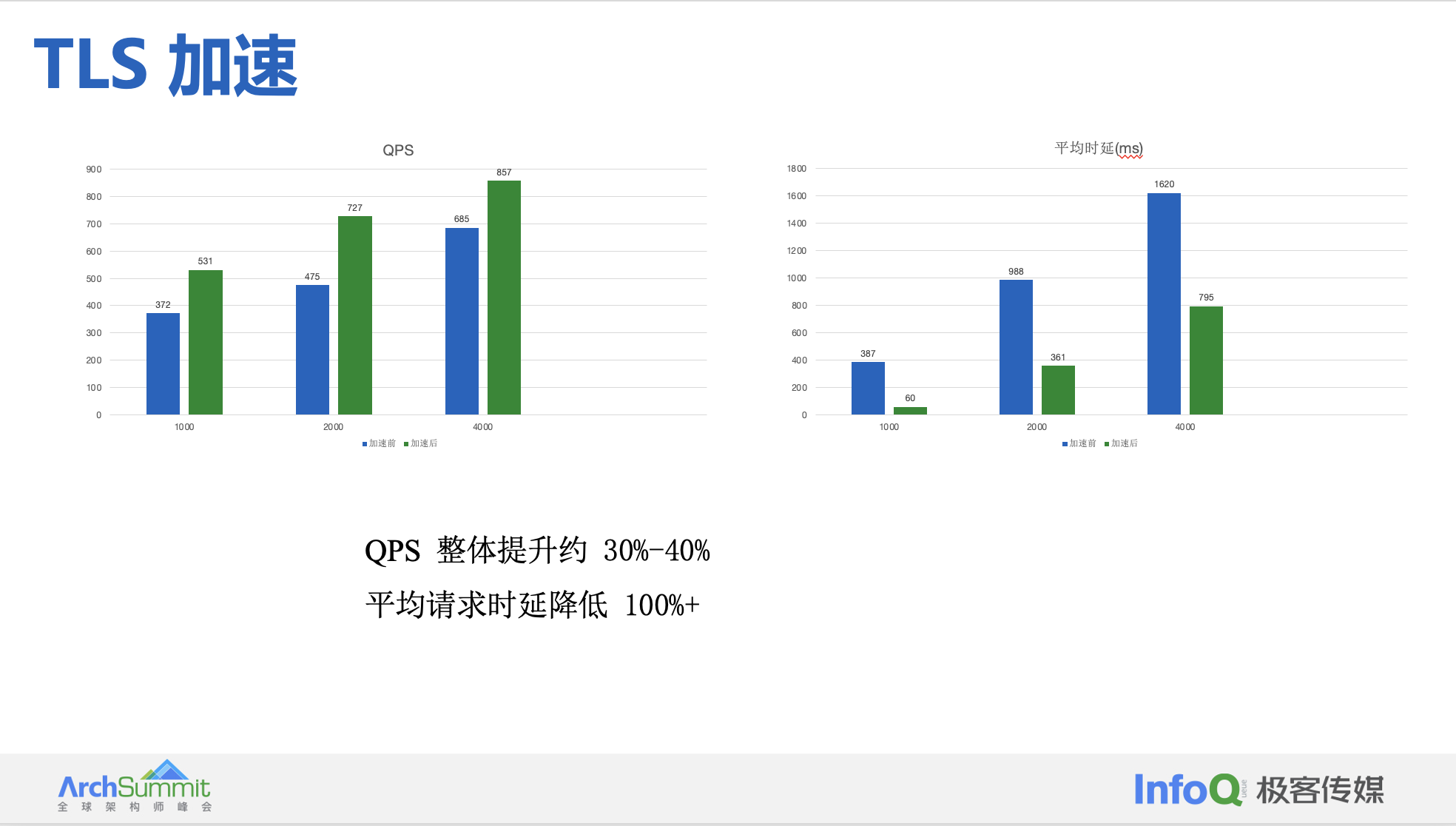
我们利用第三代 Intel® 至强® 可扩展处理器指令 AVX512、Intel® Integrated Performance Primitives (Intel® IPP) 加密库、Envoy 中的 CryptoMB Private Key Provider 以及 Istio 中使用 ProxyConfig 配置来实现 Envoy TLS 加速。Envoy + BoringSSL + Multi-Buffer 实现 TLS 加速,测试数据如上所述。
网格红利
安全管理
随着越来越多组织拥抱混合云、多云、容器及边缘运算,零信任的价值愈趋明显。在云端分散式微服务架构中,组件之间的通信需要一个机制来验证各种信息的真实性,而 SPIFFE 与 SPIRE 正是为云端及基于容器的微服务打造服务身份认证能力的两个项目。零信任架构下,需要严格区分工作负载的识别和信任,而签发 X.509 证书是推荐的一种认证方式。

- SPIFFE(Secure Production Identity Framework For Everyone):SPIFFE 的目的是基于零信任的理念,建立一个开放、统一的工作负载身份标准,这有助于建立一个零信任的全面身份化的数据中心网络。SPIFFE 和 SPIRE 是一对的,SPIFFE 定义了服务的认证标准和认证信息的标准,SPIRE 是它的一个实现。SPIFFE 和 SPIRE 是 CNCF 的孵化沙箱项目。SVID(SPIFFE Validation Identity Document, SPIFFE 身份标识文档)。SPIRE 是 SPIFFE API 生产可用的实现版本,它执行节点和工作负载证明,以便根据预定义的一组条件安全地向工作负载发布 SVID,并验证其他工作负载的 SVID。
- SPIRE(SPIFFE Runtime Environment) 是 SPIFFE 标准的一套生产就绪实现。
- SVID(SPIFFE Verifiable Identity Document)是工作负载向资源或调用者证明其身份的文件。SVID 包含一个 SPIFFE ID,代表了服务的身份。它将 SPIFFE ID 编码在一个可加密验证的文件中,目前支持两种格式:X.509 证书或 JWT 令牌。
- SPIFFE ID 是一个统一资源标识符(URI),其格式如下:spiffe://trust_domain/workload_identifier。
- SPIRE Server 提供身份映射、节点认证、SVID 颁发等功能。
- SPIRE Agent 提供工作负载认证、工作负载 API等功能。
- 证书:证书(Certificate),又称电子证书,是用于身份认证和加密通信的一种数字证明文件。证书有很多类别,本文中的证书特指的是 X.509 V3 证书 。
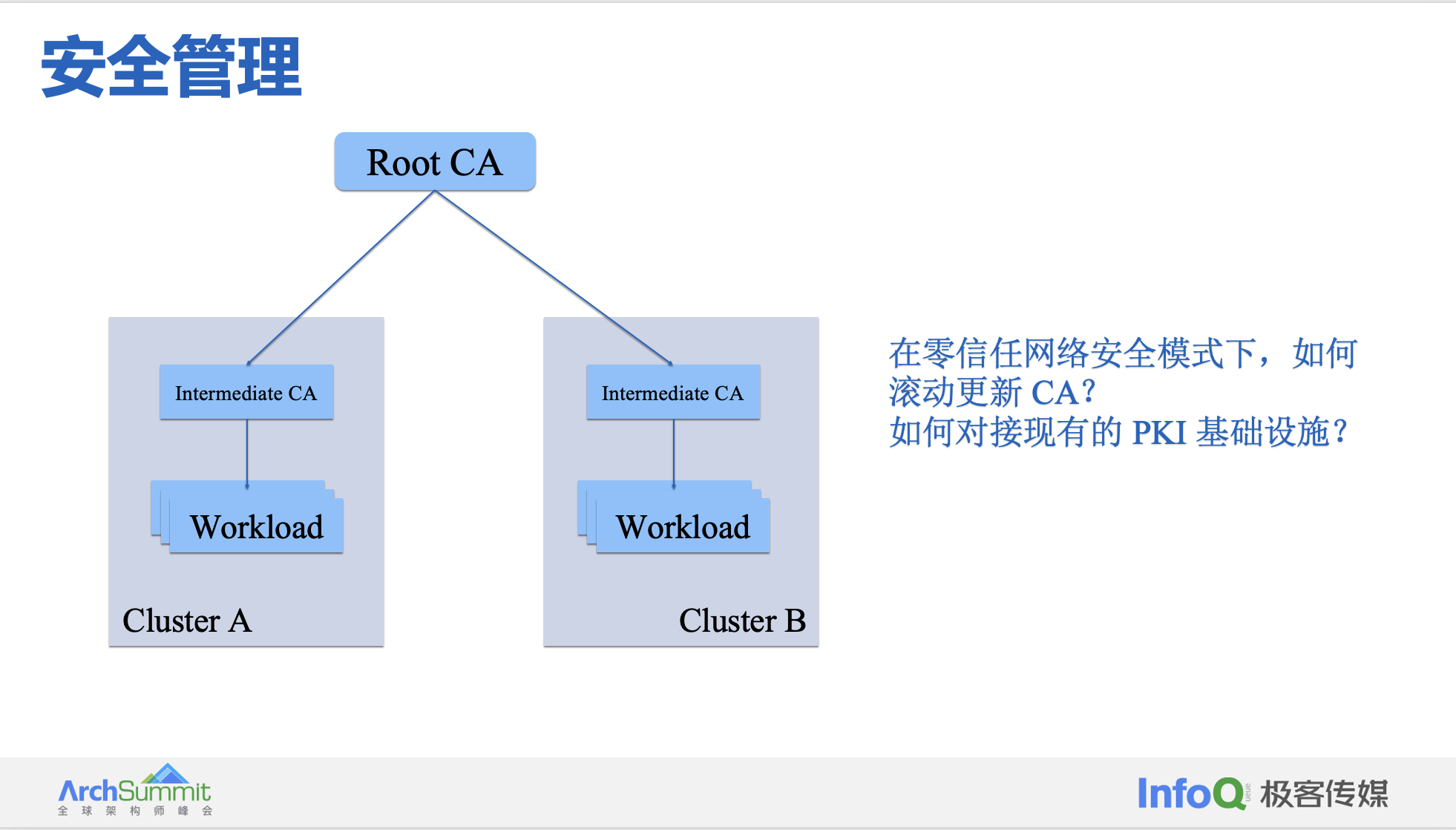
- 支持跨网格/集群通信:有了共同的信任根,集群之间就可以互相验证身份,进而实现跨集群通信
- 更细粒度的证书撤销:你可以撤销某个实体或中间 CA 的证书来撤销某个服务或集群的证书
- 轻松实现证书轮换:你可以按集群/网格实现证书轮换,而不是轮换根节点证书,减少停机时间
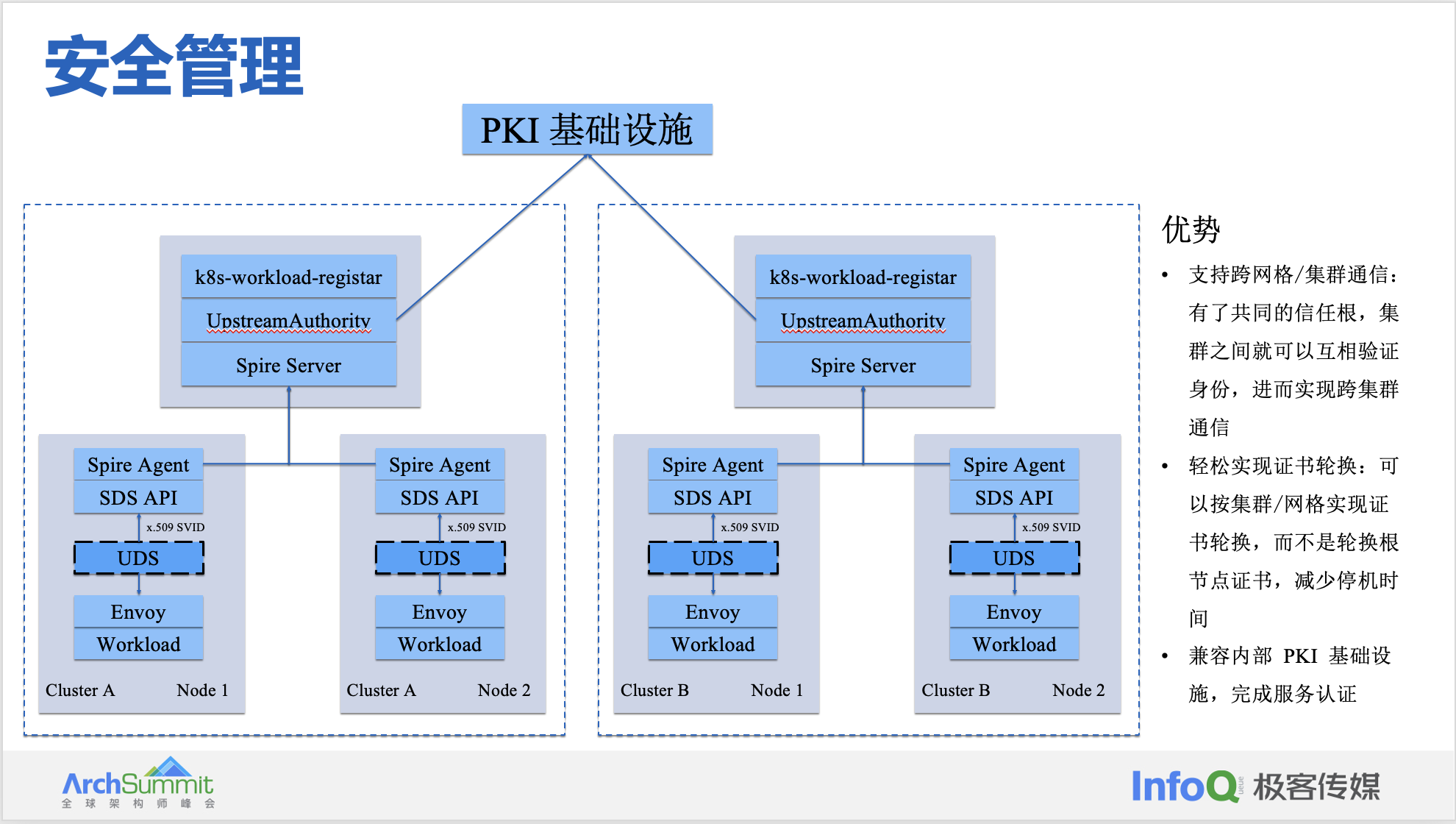
在 Kubernetes 集群中,服务间是通过 DNS 名称互相访问的,而网络流量可能被 DNS 欺骗、BGP/路由劫持、ARP 欺骗等手段劫持,为了将服务名称(DNS 名称)与服务身份强关联起来,Istio 使用置于 X.509 证书中的安全命名(Secure naming)机制。 零信任代表了新一代的网络安全防护理念,它的关键在于打破默认的“信任”,用一句通俗的话来概括,就是“持续验证,永不信任”。 SPIFFE 提供了覆盖了身份、身份证书的类型以及创建、管理和颁发方式的定义,贯彻了零信任的安全模型,为构建基础设施提供了标准框架。SPIRE 则提供了基础设施的实现,使用服务端 + 代理的分级策略采用概念威胁模型,尽可能地提升安全性和降低威胁带来的影响。 SPIFFE 是 Istio 所采用的安全命名的规范,它也是云原生定义的一种标准化的、可移植的工作负载身份规范。SPIFFE 和 SPIRE 还被多种云原生技术使用并与之集成,包括 Istio、HashiCorp、Envoy、gRPC 和 Open Policy Agent(OPA)等,其还为托管在 Kubernetes 与其他平台上工作负载之间的交叉身份验证提供了基础。
环境复用
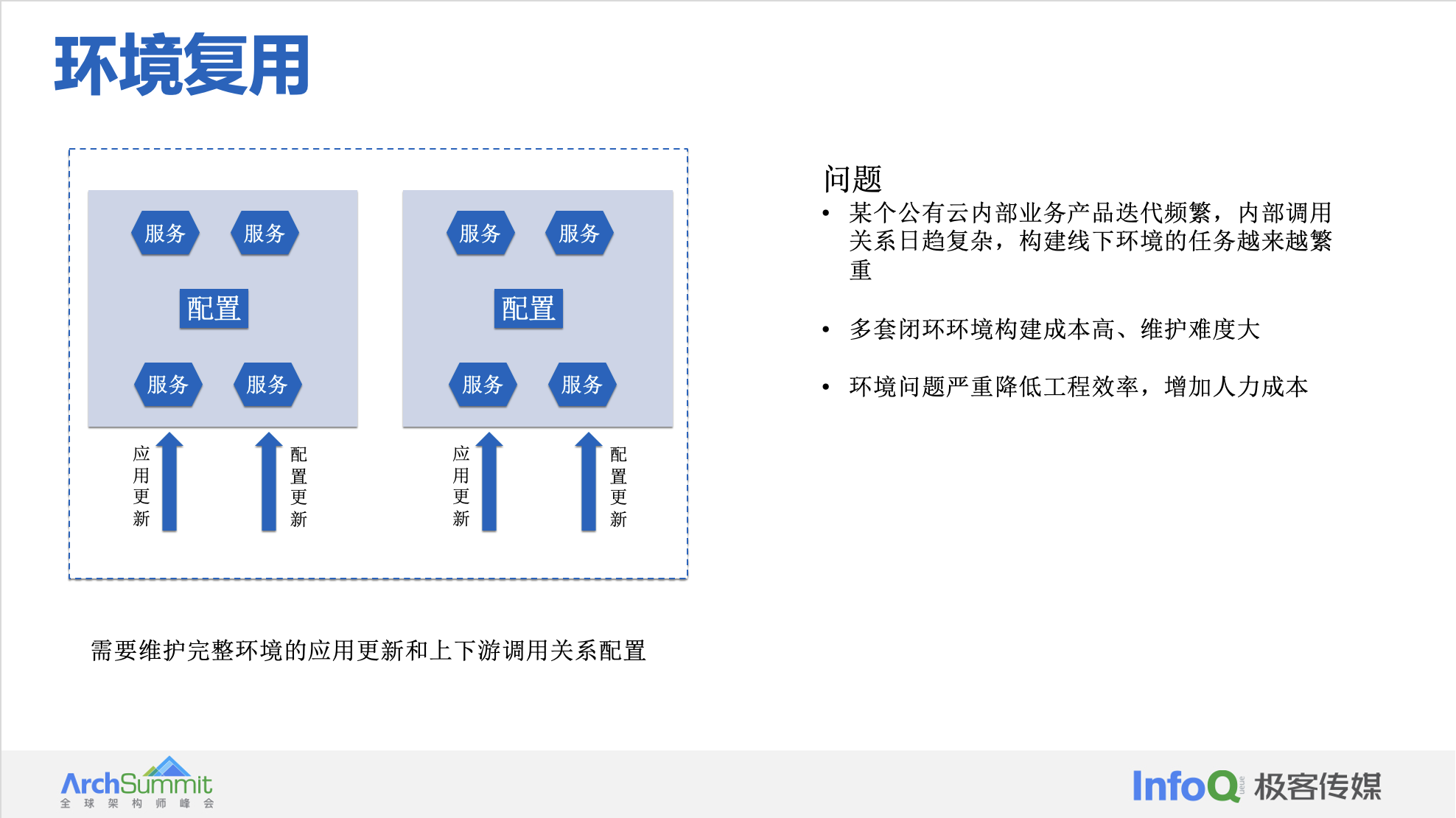
W3C 分布式追踪工作组(Distributed Tracing Working Group)发布分布式追踪上下文传播格式:Baggage 规范的首个公开工作草案(First Public Working Draft)。分布式追踪是一组用于监测分布式应用程序运行状况和可靠性的工具和实践。分布式应用程序是由多个单独部署和操作的组件组成的应用程序,它也被称为微服务。
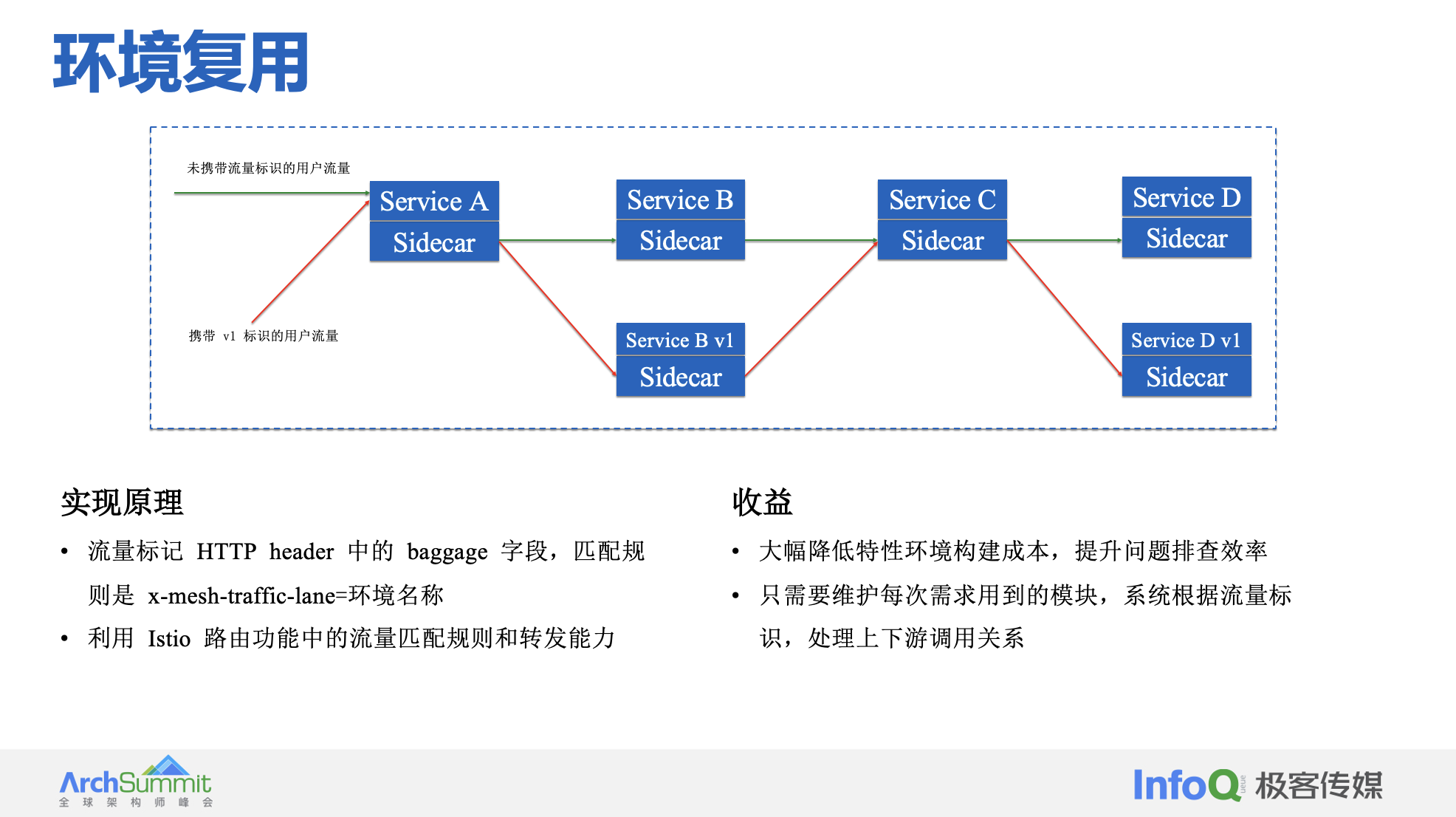
环境复用
- 大幅降低特性环境构建时间:1-3 天缩短到 10-20 min
- 降低了多套环境人工维护的成本,问题排查效率 1 天 -> 10 分钟
- 环境数量限制:3 套 -> 无限制(一站式目前限制 50 个)
- 近一百套 datahub 队列、支付回调等场景,服务流量路由接入 mesh,维护成本大幅降低
规模与收益

业务规模
- 内外客户核心产品线 Mesh 接入数 10+,如地图、搜索、好看视频、百度健康等
- 在线 Mesh 实例数达 10 万+,每天 PV 流量超过万亿
业务收益
- 为各业务线提供低侵入、低成本、高性能、标准化的服务治理解决方案,系统性解决各个产品线的基础可用性问题
- 大幅降低治理策略迭代成本与周期,从数月缩短到天级别、甚至分钟级别
- 系统核心可用性和整体容灾、防雪崩能力得到提升
- 降低研发与测试成本,提升工程效能
- 协同基础设施系统,极大提升系统稳定性与可用性
回顾与总结
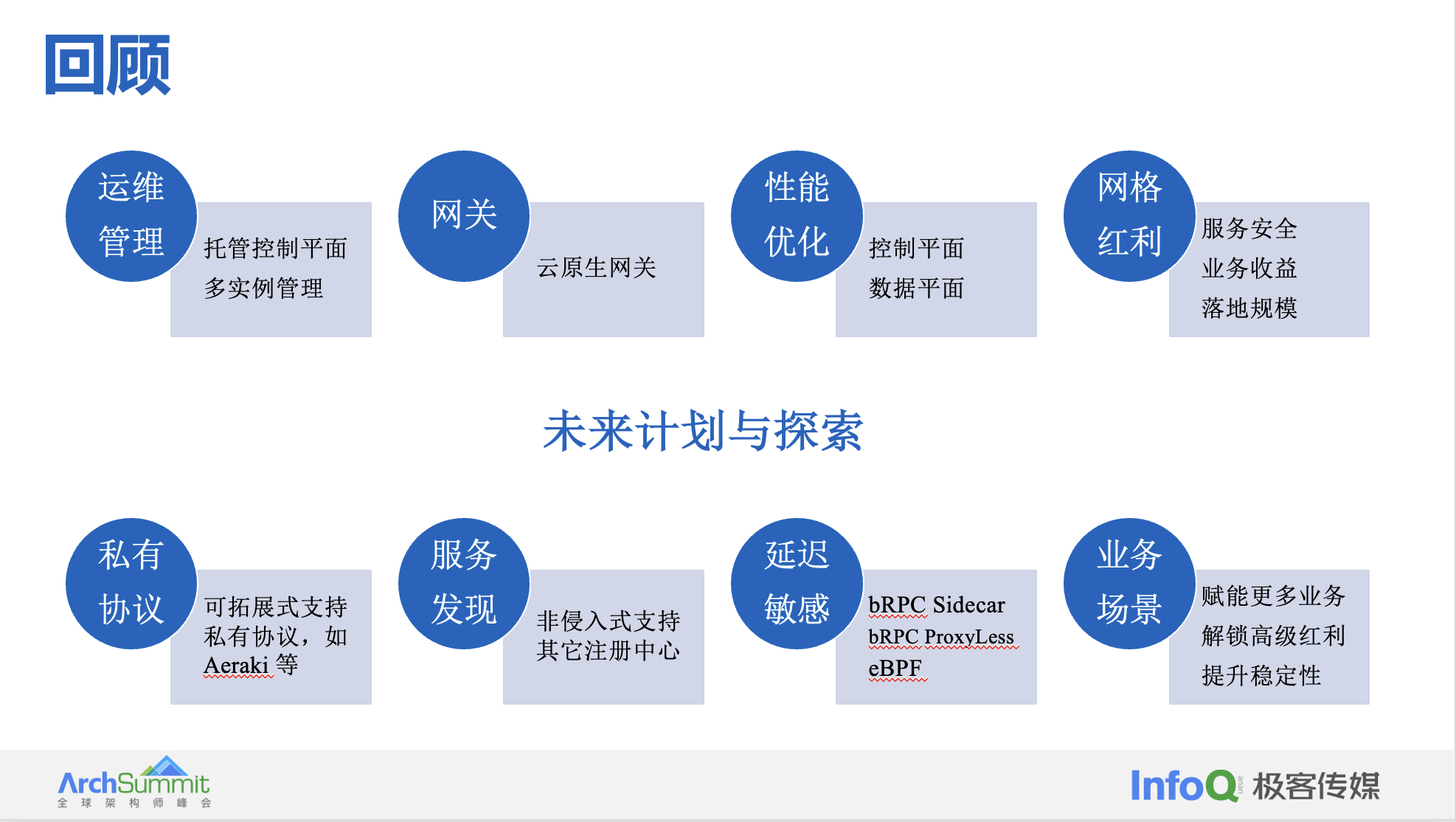
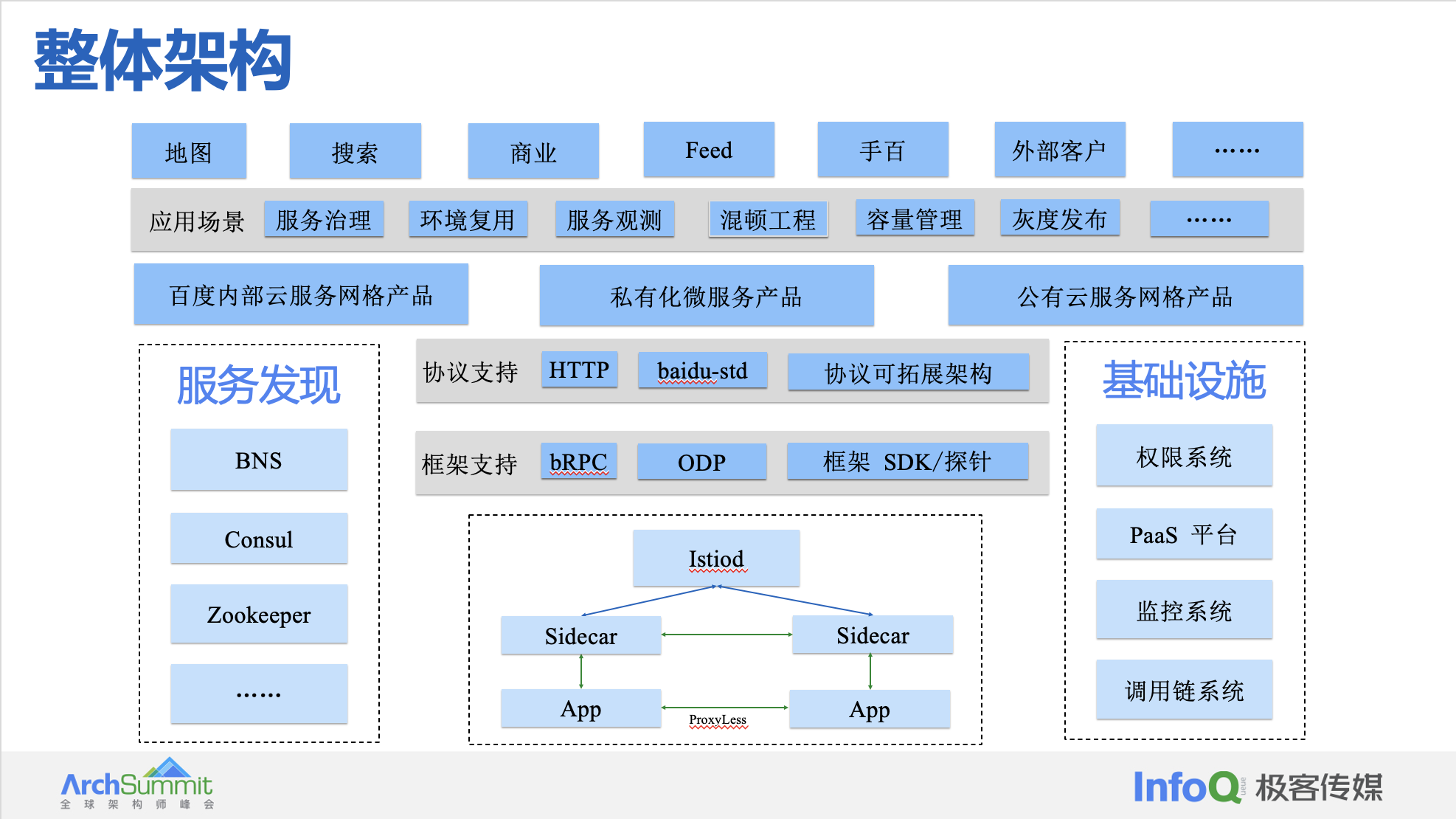
服务网格架构总结与展望

步入 2023 年,相比于 PaaS 底层能力,微服务领域是一个面向用户、与业务联系最近的一套架构,场景复杂,需求多变,因此很难出现所谓的“事实标准”。服务网格大势所趋,社区生态逐步完善。我们期待服务网格继续呈现百花齐放、多家争鸣的状态,持续给用户带来更大的价值,解放生产力,为全行业实现全面云原生化做出贡献。
总结

如果我们在使用传统微服务进行服务治理常常面临以上问题时,或者引入 Service Mesh 是很好的选择。

Service Mesh 自从诞生之时,受到各方高度认可,备受工程师关注,如果我们需要在生产环境大规模应用服务网格面临以上问题,就需要着重考量几个核心要素。
- 求实:只有适合内部基础设施的架构才是最优之选,合适的架构才是第一选择。
- 性能:对于敏感业务来说,Mesh 代理不能有很大的网络延迟,性能是第一要素。
- 平稳:Mesh 是否有劫持流量可开关、Mesh 代理故障可自动回滚、业务生产稳定可用才是第一原则。
- 易用:Mesh 本身是有一定的复杂性,作为基础架构设施,对于业务来说,产品易用是第一印象,是够有 CRD、变更日志、权限管理、产品化界面等。
- 生态:容器、网络、可观测性、安全、可拓展性等等,需要周边生态协同,才能更好地为业务服务。
Service Mesh 观点
- 拥抱开源,不等于开箱即用,需要适配公司基础设施,如 Paas、监控、链路追踪、服务框架等。
- Service Mesh 不是万能钥匙,完全无侵入、支持所有协议、各种治理策略的服务网格方案是不存在的。
- 业务应用 Mesh 化改造确实给业务带来了很多的收益,解锁各种高级能力,这是传统微服务是不能满足的,但是依然需要协同各类基础设施,才能发挥出最大价值。
展望
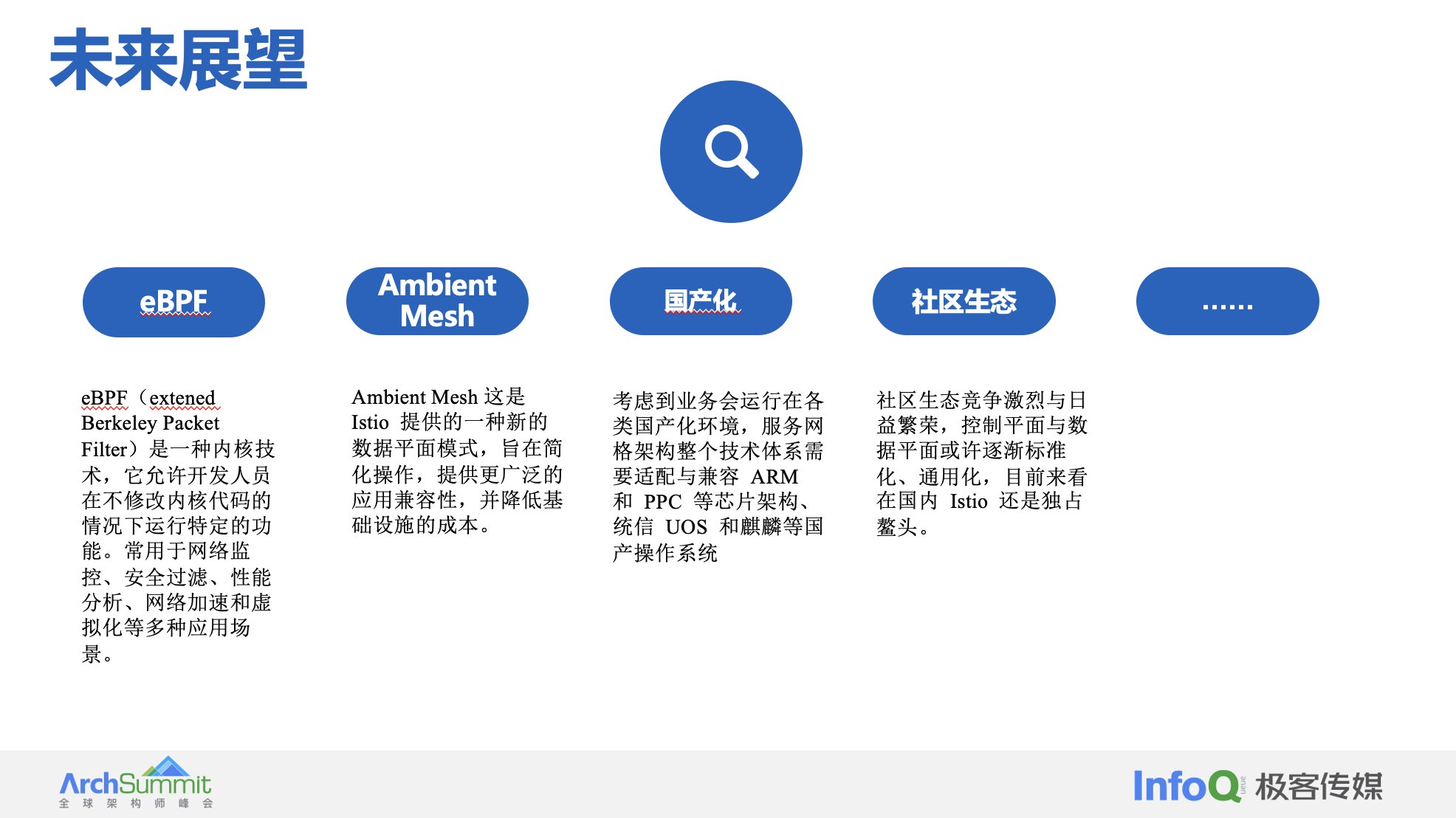
我们其实可以发现,Mesh Sidecar 这种架构就是使网络变得可编程。路途漫漫,服务网格未来大有可为,或许以下方面值得我们继续期待,EBPF、WASM、环境 Mesh、国产化等等,希望进一步与社区生态融合,共建服务网格架构生态,如下方面值得期许。
- 服务网格标准:前面我们曾接触过容器运行时领域的 CRI 规范、容器网络领域的 CNI 规范、容器存储领域的 CSI 规范,尽管服务网格诞生至今仅有数年时间,但作为微服务、云原生的前沿热点,它也正在酝酿自己的标准规范,既本节的主角:服务网格接口(Service Mesh Interface,SMI)与通用数据平面 API(Universal Data Plane API,UDPA)。服务网格实质上是数据平面产品与控制平面产品的集合,所以在规范制订方面,很自然地也分成了两类:SMI 规范提供了外部环境(实际上就是 Kubernetes)与控制平面交互的标准,使得 Kubernetes 及在其之上的应用能够无缝地切换各种服务网格产品。UDPA 规范则提供了控制平面与数据平面交互的标准,使得服务网格产品能够灵活地搭配不同的边车代理,针对不同场景的需求,发挥各款边车代理的功能或者性能优势。
- eBPF:eBPF(extened Berkeley Packet Filter)是一种内核技术,它允许开发人员在不修改内核代码的情况下运行特定的功能。常用于网络监控、安全过滤、性能分析、网络加速和虚拟化等多种应用场景。提供一种类似于在应用层编写驱动的能力,允许用户编写一个沙盒程序动态注入到内核中,运行在内核的虚拟机中,所以可以利用 ebpf 绕过内核协议栈进行网络加速。
- Wasm:WebAssembly(又名wasm)是一种高效的,低级别的编程语言。它让我们能够使用 JavaScript 以外的语言(例如C,C ++,Rust等)编写程序,然后将其编译成 WebAssembly,进而生成一个加载和执行速度非常快的 Web 应用程序。Wasm 具有运行高效、内存安全、无未定义行为和平台独立等特点,经过了编译器和标准化团队多年耕耘,目前已经有了成熟的社区。WebAssembly 是一种沙盒技术,可用于扩展 Istio 代理(Envoy)的能力。基于 WasmEdge 的微服务可以与 Dapr 和 Linkerd 边车一起使用,作为具有操作系统和完整软件堆栈的重量级成熟 Linux 容器的替代方案。与 Linux 容器应用程序相比,WebAssembly 微服务消耗 1% 的资源,冷启动时间为 1%。
- Ambient Mesh:这是 Istio 提供的一种新的数据平面模式,旨在简化操作,提供更广泛的应用兼容性,并降低基础设施的成本。Ambient mesh 使得用户可以选择使用一种可以集成到其基础设施中的 Mesh 数据平面,而不是需要和应用一起部署的 sidecar。同时,该模式可以提供和 Sidecar 模式相同的零信任安全、遥测和流量管理等 Istio 的核心功能。Sidecar 是 Istio 的特色,利用 Sidecar,对应用进行非常小的修改就可以享受服务网格带来的好处,减少运维负担;另外,Ambient 共享模式可以大大减少网格组件本身的资源开销,这一点对资源敏感的用户来说是一个巨大的福音。Sidecar 模式也有一些限制,如侵入性:Sidecar 容器是以Admission Webhook的方式来注入,与应用容器属于同一个Pod,因此Sidecar的升级,必须伴随着业务容器的重建。对应用负载来可能是破坏性的(例如:长连接场景下滚动升级可能造成浪涌)。资源利用率低:Sidecar 与应用对应,且必须预留足够的CPU和内存,可能导致整个集群资源利用率偏低;弹性扩缩容只能针对整个工作负载进行,无法单独对 Sidecar 进行。流量中断:流量的捕获和 HTTP 处理由 Sidecar 完成,成本高且可能破坏一些不兼容 HTTP 的实现。
- 国产化:考虑到业务会运行在各类国产化环境中,因此也会将服务网格整个技术体系兼容不同的国产化环境。比如在芯片层面需要兼容X86、ARM 和PPC,在操作系统上需要兼容统信UOS 和麒麟,在秘钥兼容国产密码算法等。
- 生态:社区生态竞争激烈与日益繁荣,控制平面与数据平面或许逐渐标准化、通用化,目前来看在国内 Istio 还是独占鳌头。
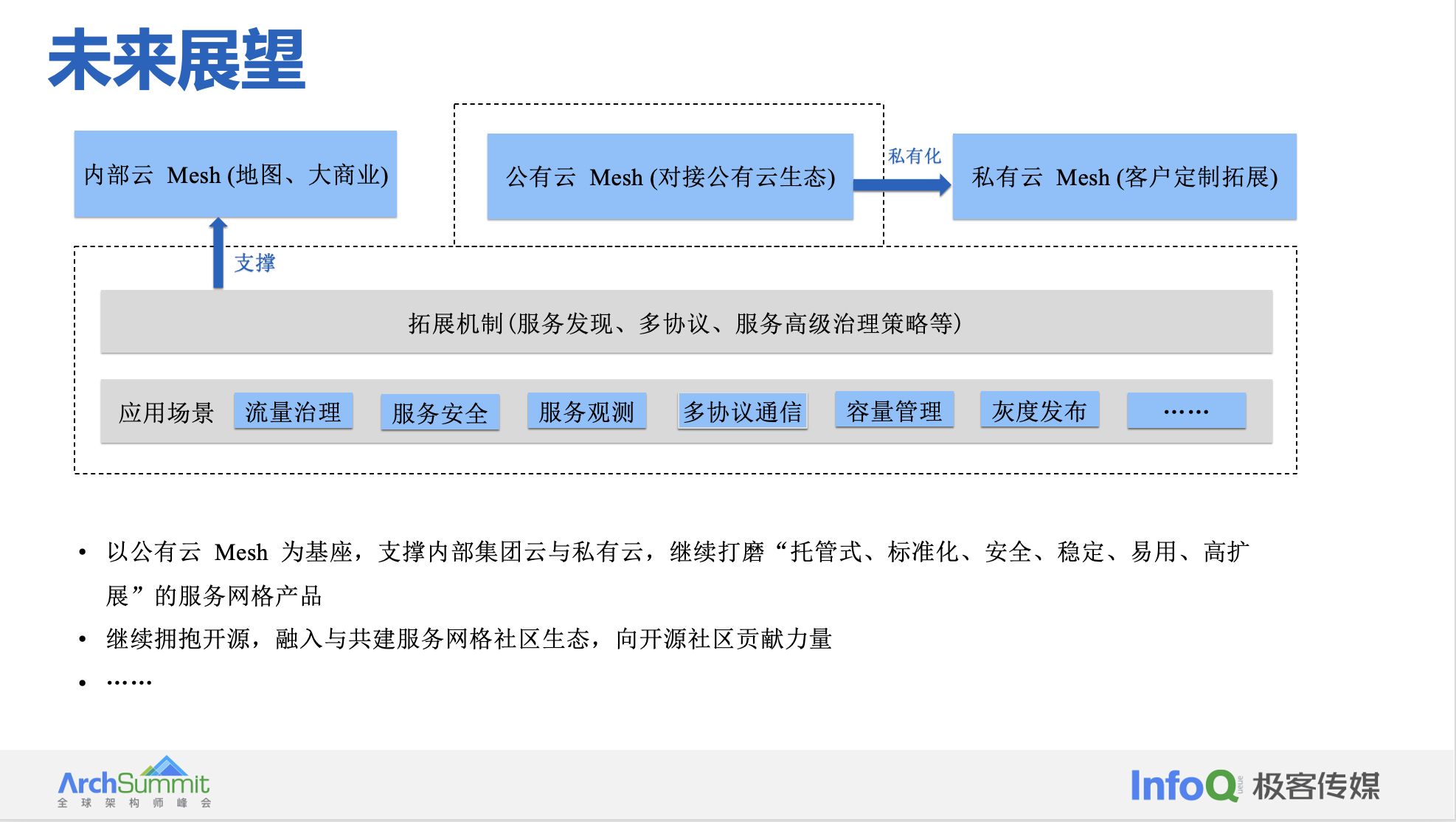
结语

架构不是一蹴而就的,只有能够赋能业务,架构才能有生命力。 Service Mesh 不会是微服务架构演进的终极方向。
参考
ArchSummit 全球架构师峰会微服务专场(2023 北京)