通过 eBPF 可以对多种类型的事件进行跟踪,例如 kprobe、kretprobe、tracepoint、uprobe、uretprobe、socket filter、tc filter、perf events 等,本文主要介绍上述事件 hook 跟踪点。
kprobe
Linux kprobes 调试技术是内核开发者们专门为了便于跟踪内核函数执行状态所设计的一种轻量级内核调试技术。利用 kprobes 技术,内核开发人员可以在内核的绝大多数指定函数中动态的插入探测点来收集所需的调试状态信息而基本不影响内核原有的执行流程。当然,也不是所有的函数都是支持 kprobe 机制,可以通过 cat /sys/kernel/debug/tracing/available_filter_functions 查看当前系统支持的函数。
- kprobe 允许在内核函数的入口处插入一个断点。当 CPU 执行到这个位置时,会触发一个陷入(trap),CPU 切换到你预先定义的处理函数(probe handler)执行。这个处理函数可以访问和修改内核的状态,包括 CPU 寄存器、内核栈、全局变量等。执行完处理函数后,CPU 会返回到断点处,继续执行原来的内核代码。
- kretprobe 允许在内核函数返回时插入探测点。这对于追踪函数的返回值或者函数的执行时间非常有用。kretprobe 的工作原理是在函数的返回地址前插入一个断点。当函数返回时,CPU 会先跳转到你的处理函数,然后再返回到原来的地址。具体可参见 kprobe_example.c ,kprobe 是如何跟踪内核事件的。
// SPDX-License-Identifier: GPL-2.0-only
/*
* Here's a sample kernel module showing the use of kprobes to dump a
* stack trace and selected registers when kernel_clone() is called.
*
* For more information on theory of operation of kprobes, see
* Documentation/trace/kprobes.rst
*
* You will see the trace data in /var/log/messages and on the console
* whenever kernel_clone() is invoked to create a new process.
*/
#define pr_fmt(fmt) "%s: " fmt, __func__
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/kprobes.h>
static char symbol[KSYM_NAME_LEN] = "kernel_clone";
module_param_string(symbol, symbol, KSYM_NAME_LEN, 0644);
/* For each probe you need to allocate a kprobe structure */
static struct kprobe kp = {
.symbol_name = symbol,
};
/* kprobe pre_handler: called just before the probed instruction is executed */
static int __kprobes handler_pre(struct kprobe *p, struct pt_regs *regs)
{
#ifdef CONFIG_X86
pr_info("<%s> p->addr = 0x%p, ip = %lx, flags = 0x%lx\n",
p->symbol_name, p->addr, regs->ip, regs->flags);
#endif
#ifdef CONFIG_PPC
pr_info("<%s> p->addr = 0x%p, nip = 0x%lx, msr = 0x%lx\n",
p->symbol_name, p->addr, regs->nip, regs->msr);
#endif
#ifdef CONFIG_MIPS
pr_info("<%s> p->addr = 0x%p, epc = 0x%lx, status = 0x%lx\n",
p->symbol_name, p->addr, regs->cp0_epc, regs->cp0_status);
#endif
#ifdef CONFIG_ARM64
pr_info("<%s> p->addr = 0x%p, pc = 0x%lx, pstate = 0x%lx\n",
p->symbol_name, p->addr, (long)regs->pc, (long)regs->pstate);
#endif
#ifdef CONFIG_ARM
pr_info("<%s> p->addr = 0x%p, pc = 0x%lx, cpsr = 0x%lx\n",
p->symbol_name, p->addr, (long)regs->ARM_pc, (long)regs->ARM_cpsr);
#endif
#ifdef CONFIG_RISCV
pr_info("<%s> p->addr = 0x%p, pc = 0x%lx, status = 0x%lx\n",
p->symbol_name, p->addr, regs->epc, regs->status);
#endif
#ifdef CONFIG_S390
pr_info("<%s> p->addr, 0x%p, ip = 0x%lx, flags = 0x%lx\n",
p->symbol_name, p->addr, regs->psw.addr, regs->flags);
#endif
#ifdef CONFIG_LOONGARCH
pr_info("<%s> p->addr = 0x%p, era = 0x%lx, estat = 0x%lx\n",
p->symbol_name, p->addr, regs->csr_era, regs->csr_estat);
#endif
/* A dump_stack() here will give a stack backtrace */
return 0;
}
/* kprobe post_handler: called after the probed instruction is executed */
static void __kprobes handler_post(struct kprobe *p, struct pt_regs *regs,
unsigned long flags)
{
#ifdef CONFIG_X86
pr_info("<%s> p->addr = 0x%p, flags = 0x%lx\n",
p->symbol_name, p->addr, regs->flags);
#endif
#ifdef CONFIG_PPC
pr_info("<%s> p->addr = 0x%p, msr = 0x%lx\n",
p->symbol_name, p->addr, regs->msr);
#endif
#ifdef CONFIG_MIPS
pr_info("<%s> p->addr = 0x%p, status = 0x%lx\n",
p->symbol_name, p->addr, regs->cp0_status);
#endif
#ifdef CONFIG_ARM64
pr_info("<%s> p->addr = 0x%p, pstate = 0x%lx\n",
p->symbol_name, p->addr, (long)regs->pstate);
#endif
#ifdef CONFIG_ARM
pr_info("<%s> p->addr = 0x%p, cpsr = 0x%lx\n",
p->symbol_name, p->addr, (long)regs->ARM_cpsr);
#endif
#ifdef CONFIG_RISCV
pr_info("<%s> p->addr = 0x%p, status = 0x%lx\n",
p->symbol_name, p->addr, regs->status);
#endif
#ifdef CONFIG_S390
pr_info("<%s> p->addr, 0x%p, flags = 0x%lx\n",
p->symbol_name, p->addr, regs->flags);
#endif
#ifdef CONFIG_LOONGARCH
pr_info("<%s> p->addr = 0x%p, estat = 0x%lx\n",
p->symbol_name, p->addr, regs->csr_estat);
#endif
}
static int __init kprobe_init(void)
{
int ret;
kp.pre_handler = handler_pre;
kp.post_handler = handler_post;
ret = register_kprobe(&kp);
if (ret < 0) {
pr_err("register_kprobe failed, returned %d\n", ret);
return ret;
}
pr_info("Planted kprobe at %p\n", kp.addr);
return 0;
}
static void __exit kprobe_exit(void)
{
unregister_kprobe(&kp);
pr_info("kprobe at %p unregistered\n", kp.addr);
}
module_init(kprobe_init)
module_exit(kprobe_exit)
MODULE_LICENSE("GPL");
使用 kprobe 针对 kernel_clone 进行探测,kprobe 是有其特定的开发模式,需要将 kprobe 代码编译成为一个 LKM 模块加载到内核中才能使用。除了开发比较繁琐之外,还因为是通过 LKM 加载到内核中,还容易造成内核崩溃。但是 eBPF 使用 kprobe 机制就很简单,见 test_overhead_kprobe.bpf.c 如下所示:
/* Copyright (c) 2016 Facebook
*
* This program is free software; you can redistribute it and/or
* modify it under the terms of version 2 of the GNU General Public
* License as published by the Free Software Foundation.
*/
#include "vmlinux.h"
#include <linux/version.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
SEC("kprobe/__set_task_comm")
int prog(struct pt_regs *ctx)
{
struct signal_struct *signal;
struct task_struct *tsk;
char oldcomm[TASK_COMM_LEN] = {};
char newcomm[TASK_COMM_LEN] = {};
u16 oom_score_adj;
u32 pid;
tsk = (void *)PT_REGS_PARM1_CORE(ctx);
pid = BPF_CORE_READ(tsk, pid);
bpf_core_read_str(oldcomm, sizeof(oldcomm), &tsk->comm);
bpf_core_read_str(newcomm, sizeof(newcomm),
(void *)PT_REGS_PARM2(ctx));
signal = BPF_CORE_READ(tsk, signal);
oom_score_adj = BPF_CORE_READ(signal, oom_score_adj);
return 0;
}
SEC("kprobe/fib_table_lookup")
int prog2(struct pt_regs *ctx)
{
return 0;
}
char _license[] SEC("license") = "GPL";
u32 _version SEC("version") = LINUX_VERSION_CODE;
SEC("kprobe/fib_table_lookup") 是一个宏 SEC,它将 eBPF 程序与特定的 kprobe 关联起来。在这个例子中,它将 eBPF 程序与 fib_table_lookup 函数的 kprobe 关联起来。fib_table_lookup 是 Linux 内核中的一个函数,它用于在 FIB(Forwarding Information Base) 表中查找路由信息。
SEC("kprobe/__set_task_comm") 是一个宏 SEC,它将 eBPF 程序与特定的 kprobe 关联起来。在这个例子中,它将 eBPF 程序与 __set_task_comm 函数的 kprobe 关联起来。__set_task_comm 是 Linux 内核中的一个函数,它用于设置任务(即进程)的名称。在这个 eBPF 程序中,它首先获取了被调用 __set_task_comm 函数的任务结构体 task_struct 的指针,然后读取了任务的 PID、旧的名称、新的名称和 OOM(Out of Memory)得分调整值。
kretprobe
kretprobe 的使用基本上和 kprobe 是一致的,参见代码库 kretprobe_example.c 。
// SPDX-License-Identifier: GPL-2.0-only
/*
* kretprobe_example.c
*
* Here's a sample kernel module showing the use of return probes to
* report the return value and total time taken for probed function
* to run.
*
* usage: insmod kretprobe_example.ko func=<func_name>
*
* If no func_name is specified, kernel_clone is instrumented
*
* For more information on theory of operation of kretprobes, see
* Documentation/trace/kprobes.rst
*
* Build and insert the kernel module as done in the kprobe example.
* You will see the trace data in /var/log/messages and on the console
* whenever the probed function returns. (Some messages may be suppressed
* if syslogd is configured to eliminate duplicate messages.)
*/
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/kprobes.h>
#include <linux/ktime.h>
#include <linux/sched.h>
static char func_name[KSYM_NAME_LEN] = "kernel_clone";
module_param_string(func, func_name, KSYM_NAME_LEN, 0644);
MODULE_PARM_DESC(func, "Function to kretprobe; this module will report the"
" function's execution time");
/* per-instance private data */
struct my_data {
ktime_t entry_stamp;
};
/* Here we use the entry_hanlder to timestamp function entry */
static int entry_handler(struct kretprobe_instance *ri, struct pt_regs *regs)
{
struct my_data *data;
if (!current->mm)
return 1; /* Skip kernel threads */
data = (struct my_data *)ri->data;
data->entry_stamp = ktime_get();
return 0;
}
NOKPROBE_SYMBOL(entry_handler);
/*
* Return-probe handler: Log the return value and duration. Duration may turn
* out to be zero consistently, depending upon the granularity of time
* accounting on the platform.
*/
static int ret_handler(struct kretprobe_instance *ri, struct pt_regs *regs)
{
unsigned long retval = regs_return_value(regs);
struct my_data *data = (struct my_data *)ri->data;
s64 delta;
ktime_t now;
now = ktime_get();
delta = ktime_to_ns(ktime_sub(now, data->entry_stamp));
pr_info("%s returned %lu and took %lld ns to execute\n",
func_name, retval, (long long)delta);
return 0;
}
NOKPROBE_SYMBOL(ret_handler);
static struct kretprobe my_kretprobe = {
.handler = ret_handler,
.entry_handler = entry_handler,
.data_size = sizeof(struct my_data),
/* Probe up to 20 instances concurrently. */
.maxactive = 20,
};
static int __init kretprobe_init(void)
{
int ret;
my_kretprobe.kp.symbol_name = func_name;
ret = register_kretprobe(&my_kretprobe);
if (ret < 0) {
pr_err("register_kretprobe failed, returned %d\n", ret);
return ret;
}
pr_info("Planted return probe at %s: %p\n",
my_kretprobe.kp.symbol_name, my_kretprobe.kp.addr);
return 0;
}
static void __exit kretprobe_exit(void)
{
unregister_kretprobe(&my_kretprobe);
pr_info("kretprobe at %p unregistered\n", my_kretprobe.kp.addr);
/* nmissed > 0 suggests that maxactive was set too low. */
pr_info("Missed probing %d instances of %s\n",
my_kretprobe.nmissed, my_kretprobe.kp.symbol_name);
}
module_init(kretprobe_init)
module_exit(kretprobe_exit)
MODULE_LICENSE("GPL");
在这个模块中,它首先定义了一个 kretprobe 结构体 my_kretprobe,并设置了它的处理函数 ret_handler 和 entry_handler,以及用于存储每个实例数据的空间大小 data_size。entry_handler 函数在被跟踪的函数开始执行时被调用,它记录了函数开始执行的时间戳。ret_handler 函数在被跟踪的函数返回时被调用,它计算了函数的执行时间(即当前时间减去开始执行的时间戳),并打印了函数的返回值和执行时间。在 kretprobe_init 函数中,它注册了 kretprobe,使得内核开始跟踪指定的函数。在 kretprobe_exit 函数中,它注销了 kretprobe,使得内核停止跟踪该函数。这个模块可以通过 insmod 命令加载到内核中,然后你就可以在系统日志中看到被跟踪函数的执行时间和返回值。
tracepoint
tracepoints 是 Linux 内核中的一种机制,它们是在内核源代码中预定义的钩子点,用于插入用于跟踪和调试的代码。tracepoints 在内核中的特定位置被硬编码,每个 tracepoint 都有一个唯一的名称和一组相关的参数。
- tracepoints 的主要优点是它们对性能的影响非常小。当没有激活 tracepoint 时,它几乎不会影响系统性能。只有当一个 tracepoint 被激活,并且有一个或多个回调函数(也称为探针)附加到它时,它才会消耗 CPU 时间。tracepoints 非常适合在生产环境中使用,因为它们可以在需要时打开,而在不需要时关闭,以最小化性能影响。
- tracepoints 的另一个优点是它们提供了一种稳定的 ABI(应用程序二进制接口)。这意味着,即使在内核版本升级后,tracepoint 的名称和参数不会改变,这使得开发者可以编写依赖于特定 tracepoint 的代码,而不用担心在未来的内核版本中这些 tracepoint 会改变。
在 eBPF 中,你可以使用 tracepoint 来捕获内核中发生的事件。你可以编写一个 eBPF 程序,然后将它附加到一个 tracepoint 上。当 tracepoint 被触发时,你的 eBPF 程序会被调用,你可以在你的 eBPF 程序中访问 tracepoint 的参数,以获取有关事件的详细信息。tracepoints 和 kprobes/kretprobes 都是 Linux 内核中用于动态跟踪的机制,但它们在使用和性能方面有一些关键的区别。以下是 tracepoints 和 kprobes/kretprobes 的一些优缺点:
tracepoints: 优点:
- 稳定性:Tracepoints 是内核开发者在代码中明确定义的,因此它们的位置和语义在内核版本之间是稳定的。
- 性能:Tracepoints 的开销通常比 kprobes/kretprobes 小,因为它们是在编译时直接嵌入到内核代码中的。
- 安全性:Tracepoints 不会改变内核代码,因此它们不会引入新的安全风险。 缺点:
- 灵活性:Tracepoints 的数量和位置是固定的,你不能在任意位置添加新的 tracepoints。
- 覆盖范围:并非所有的内核函数和事件都有对应的 tracepoints。
Kprobes/Kretprobes: 优点:
- 灵活性:你可以在任意的内核函数入口和退出点设置 kprobes/kretprobes,这使得它们可以覆盖到内核中的任何代码。
- 动态性:你可以在系统运行时动态地添加和移除 kprobes/kretprobes,而不需要重新编译或者重启内核。
- 稳定性:kprobes/kretprobes 的位置和语义可能会在不同的内核版本之间变化,因为它们依赖于具体的内核代码。 缺点:
- 性能:kprobes/kretprobes 的开销通常比 tracepoints 大,因为它们需要在运行时修改内核代码。
- 安全性:虽然 kprobes/kretprobes 有一些机制来防止它们引入新的安全风险,但是它们仍然比 tracepoints 更容易出错,因为它们需要在运行时修改内核代码。
socket
socket 就是和网络包相关的事件,常见的网络包处理函数有 sock_filter 和 sockops。eBPF 所有可以处理的事件类型都在 bpf.h 文件中定义。其中和 socket 相关的事件有:
- BPF_PROG_TYPE_SOCKET_FILTER: 这种类型的 eBPF 程序设计用于处理网络数据包;
- BPF_PROG_TYPE_SOCK_OPS 和 BPF_PROG_TYPE_SK_SKB: 这两种类型的 eBPF 程序设计用于处理 socket 操作和 socket 缓冲区中的数据包;
- BPF_PROG_TYPE_SK_MSG:用于处理 socket 消息;
BPF_PROG_TYPE_SOCKET_FILTER 对应的 eBPF 代码是
#include "include/bpf.h"
#include "include/bpf_helpers.h"
SEC("socket/sock_filter")
int socket_sock_filter(void *ctx)
{
bpf_printk("new packet received\n");
return 0;
};
这段 eBPF 代码是一个 socket filter 程序,它不需要绑定到特定的内核函数上。相反,socket filter 程序会被附加到用户态创建的套接字上,然后对通过该套接字收发的所有数据包进行处理。SEC("socket/sock_filter") 是一个标记,表示这个 eBPF 程序应该作为一个 socket filter 使用。当你在用户态加载这个程序并将其附加到一个套接字上时,每当有新的数据包经过这个套接字时,这个程序就会被执行。在这个程序中,bpf_printk("new packet received\n"); 语句会在每次接收到新数据包时向内核日志输出一条消息。返回值 0 表示该数据包应被接受(即不被丢弃)。
所以,对于这种类型的 eBPF 程序,你不需要指定要绑定的内核函数。你只需要在用户态创建一个套接字,并将这个 eBPF 程序附加到这个套接字上。对应用户端的代码如下:
func newSocketPair() (SocketPair, error) {
return syscall.Socketpair(syscall.AF_UNIX, syscall.SOCK_DGRAM, 0)
}
func main() {
m := &manager.Manager{
Probes: []*manager.Probe{
{
Section: "socket/sock_filter",
EbpfFuncName: "socket_sock_filter",
},
},
}
err := m.Init(bytes.NewReader(_bytecode))
if err != nil {
fmt.Println(err)
return
}
sockPair, err := newSocketPair()
if err != nil {
fmt.Println(err)
return
}
m.Probes[0].SocketFD = sockPair[0]
...
}
通过 m.Probes[0].SocketFD = sockPair[0],将创建的 socket/sock_filter 对应的程序绑定到 sockPair[0] (即 socket 的输入)。
func trigger(sockPair SocketPair) error {
fmt.Println("Sending a message through the socket pair to trigger the probes ...")
_, err := syscall.Write(sockPair[1], nil)
if err != nil {
return err
}
_, err = syscall.Read(sockPair[0], nil)
return err
}
通过 syscall.Write(sockPair[1], nil) 和 syscall.Read(sockPair[0], nil) 触发 eBPF。实际的运行结果如下:
sudo cat /sys/kernel/debug/tracing/trace_pipe
___go_build_soc-3814323 [009] d...1 1508306.501709: bpf_trace_printk: new packet received
成功输出 new packet received 说明程序成功执行。
sockops
除了有 BPF_PROG_TYPE_SOCKET_FILTER,还有 BPF_PROG_TYPE_SOCK_OPS 类型的事件,BPF_PROG_TYPE_SOCK_OPS 类型的 eBPF 程序用于 TCP 事件的处理,例如连接的建立和断开、拥塞控制等。这种类型的程序可以用于获取和修改 socket 操作的各种参数,例如发送和接收窗口的大小,重传超时时间等。内核态的代码如下:
#include "include/bpf.h"
#include "include/bpf_helpers.h"
SEC("sockops")
int bpf_sockops(struct bpf_sock_ops *skops)
{
switch (skops->op) {
default:
bpf_printk("eBPF sockops : %d \n",skops->op);
}
return 0;
}
char _license[] SEC("license") = "GPL";
__u32 _version SEC("version") = 0xFFFFFFFE;
bpf_sock_ops 在文件 bpf.h 中定义。由于 bpf_sock_ops 的定义较长,这里只列出部分代码:
struct bpf_sock_ops
{
__u32 op;
union {
__u32 args[4]; /* Optionally passed to bpf program */
__u32 reply; /* Returned by bpf program */
__u32 replylong[4]; /* Optionally returned by bpf prog */
};
__u32 family;
__u32 remote_ip4; /* Stored in network byte order */
__u32 local_ip4; /* Stored in network byte order */
__u32 remote_ip6[4]; /* Stored in network byte order */
__u32 local_ip6[4]; /* Stored in network byte order */
__u32 remote_port; /* Stored in network byte order */
__u32 local_port; /* stored in host byte order */
__u32 is_fullsock; /* Some TCP fields are only valid if
* there is a full socket. If not, the
* fields read as zero.
*/
.....
};
内核态的代码含义很简单明确,根据 skops->op 的值进行分支处理。struct bpf_sock_ops 是一个用于描述 socket 操作的结构体,其中的 op 字段表示当前的操作类型,默认情况下会通过 bpf_printk 输出,用户态代码:
func trigger() {
fmt.Println("Generating some network traffic to trigger the probes ...")
_, _ = http.Get("https://www.bing.com/")
}
func detectCgroupPath() (string, error) {
f, err := os.Open("/proc/mounts")
if err != nil {
return "", err
}
defer f.Close()
scanner := bufio.NewScanner(f)
for scanner.Scan() {
fields := strings.Split(scanner.Text(), " ")
if len(fields) >= 3 && fields[2] == "cgroup2" {
return fields[1], nil
}
}
return "", errors.New("cgroup2 is not mounted")
}
func main() {
m := &manager.Manager{
Probes: []*manager.Probe{
{
Section: "sockops",
EbpfFuncName: "bpf_sockops",
},
},
}
err := m.Init(bytes.NewReader(_bytecode))
if err != nil {
fmt.Println(err)
return
}
result, err := detectCgroupPath()
if err != nil {
fmt.Println(err)
return
}
m.Probes[0].CGroupPath = result
if err := m.Start(); err != nil {
fmt.Println(err)
return
}
fmt.Println("successfully started, head over to /sys/kernel/debug/tracing/trace_pipe")
time.Sleep(time.Second * 3)
// Generate some network traffic to trigger the probe
trigger()
// Close the manager
if err := m.Stop(manager.CleanAll); err != nil {
fmt.Println(err)
return
}
}
因为 sockops 是针对 TCP 事件的处理,所以可以通过构造一个网络事件来触发 sockops 的执行。在使用 eBPF 进行网络监控和处理时,指定 sockops 的 CGroupPath 是为了将 eBPF 程序限定在特定的 cgroup2 控制组中生效.cgroup(控制组)是 Linux 内核中的一个特性,用于对进程进行分组和限制资源的使用。通过将 eBPF 程序关联到特定的 cgroup2 控制组,可以实现对该组内的进程进行网络流量监控和处理。
具体来说,sockops 在 eBPF 中是一个用于监控和处理套接字操作的功能或钩子。它允许你捕获和处理诸如套接字创建、连接、关闭等事件。通过指定 CGroupPath,你可以使 sockops 程序仅在特定的 cgroup2 控制组中生效,只监控该组内的套接字操作。这样做的好处是可以针对特定的进程或应用程序进行网络监控和处理,而不会干扰其他进程或应用程序。同时,也能够提供更精细的网络流量控制和安全策略,增强系统的安全性和性能。
需要注意的是,指定 CGroupPath 前提是系统中已经挂载了 cgroup2 文件系统,并且相关的权限和配置已正确设置。否则,可能会导致无法在指定的 cgroup2 控制组中启用 eBPF 程序。最终通过 http.Get("https://www.bing.com/") 触发 socket 执行,最终运行的结果如下所示:
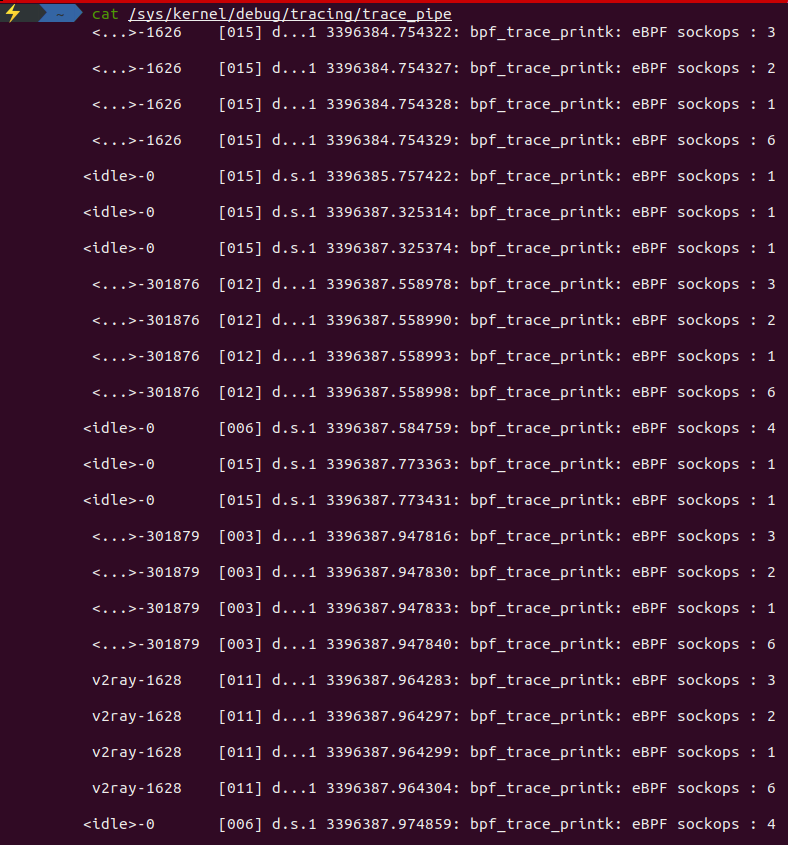
关于 socket 的妙用,可以参考 Cilium 基于 eBPF 实现 socket 加速、使用 eBPF 技术实现更快的网络数据包传输。
tc
tc 的全程是 traffic control,即流量控制。通过 tc 可以对网络流量进行控制,例如限速,限流,负载均衡等等。从 Kernel 4.1 开始,TC 支持加载 eBPF 程序到子系统的 Hook 点,并且在之后的 Kernel 4.4 中引入了 direct-action 模式,Cilium、Calico 等网络插件大量使用 TC Hook 来控制网络包的转发。子系统包括 qdisc、class、classifier(filter)、action 等概念,eBPF 程序可以作为 classifier 被挂载。想比其他类型的事件,需要额外引入 uapi/linux/pkt_cls.h 文件、pkt_cls.h 头文件提供了一组用于数据包分类的常量、数据结构和函数原型,例如 struct __sk_buff 结构体,它是 eBPF 中用于表示网络数据包的重要数据结构。
示例内核态代码:
SEC("classifier/egress")
int egress_cls_func(struct __sk_buff *skb)
{
bpf_printk("new packet captured on egress (TC)\n");
return TC_ACT_OK;
};
SEC("classifier/ingress")
int ingress_cls_func(struct __sk_buff *skb)
{
bpf_printk("new packet captured on ingress (TC)\n");
return TC_ACT_OK;
};
其中 egress 表示出流量,ingress 表示进流量,TC_ACT_OK 表示数据包在经过 TC 分类器处理后,应该继续传递到下一个阶段或进行转发操作。
示例用户态代码:
m := &manager.Manager{
Probes: []*manager.Probe{
{
Section: "classifier/egress",
EbpfFuncName: "egress_cls_func",
Ifname: "wlp3s0", // change this to the interface connected to the internet
NetworkDirection: manager.Egress,
SkipLoopback: true, // ignore loopback traffic
},
{
Section: "classifier/ingress",
EbpfFuncName: "ingress_cls_func",
Ifname: "wlp3s0", // change this to the interface connected to the internet
NetworkDirection: manager.Ingress,
},
},
}
相比之前事件类型,tc 的 Probe 配置也额外多了几项,分别是 Ifname/SkipLoopback/NetworkDirection。
- Ifname:指定要附加到的网络接口的名称。这是一个字符串,需要根据实际运行的机器上的网卡地址的名称进行修改,常见的网卡名称就是 “eth0”。在本机上,可以通过
ip addr命令查看网卡名称。 - SkipLoopback:指示是否跳过回环设备的标志。当设置为 true 时,如果数据包是通过回环设备(loopback)发送或接收的,则不会触发 eBPF 程序。这在一些情况下很有用,因为回环设备上的数据包通常不需要进行额外的处理。
- NetworkDirection:指定网络流量的方向。它可以是 manager。Ingress(入站)、manager 或者 Egress(出站)。这决定了 eBPF 程序将被应用于哪个方向的流量。请注意,在某些情况下,如果你在虚拟以太网对的主机侧进行挂钩,则 Ingress 和 Egress 的含义可能会相反。
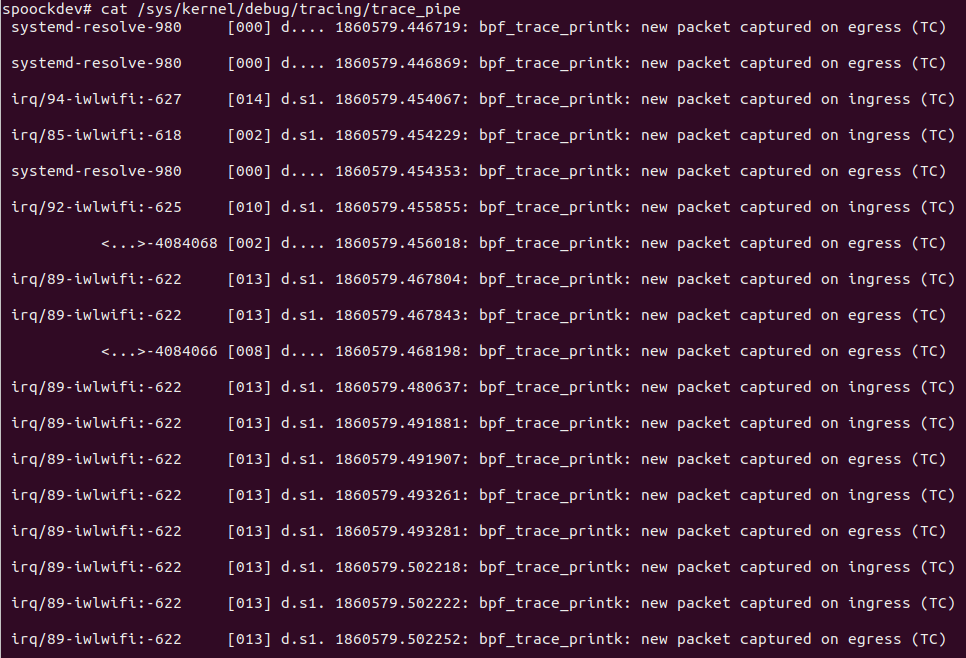
xdp
XDP 机制的主要目标是在接收数据包时尽早处理它们,以提高网络性能和降低延迟。它通过将 eBPF 程序附加到网络设备的接收路径上来实现这一目标。具体而言,XDP 程序会在数据包进入网络设备的接收队列之前执行,这样可以在内核中进行快速的数据包过滤和处理,而无需将数据包传递给用户空间。tc(Traffic Control)和 xdp(eXpress Data Path)是 Linux 网络中两种不同的数据包处理机制,他们的区别如下:
- 位置不同: tc 位于 Linux 网络协议栈的较高层,主要用于在网络设备的出入口处对数据包进行分类、调度和限速等操作。而 xdp 位于网络设备驱动程序的接收路径上,用于快速处理数据包并决定是否将其传递给协议栈。
- 执行时机不同: tc 在数据包进入或离开网络设备时执行,通常在内核空间中进行。而 xdp 在数据包进入网络设备驱动程序的接收路径时执行,可以在内核空间中或用户空间中执行。
- 处理能力不同: tc 提供了更复杂的流量控制和分类策略,可以实现各种 QoS(Quality of Service)功能。它可以对数据包进行过滤、限速、排队等操作。而 xdp 主要用于快速的数据包过滤和处理,以降低延迟和提高性能。
xdp 和 tc 的代码基本相同,除了 Section 不同之外,其他的都是一样的,示例代码如下所示:
SEC("xdp/ingress")
int egress_cls_func(struct __sk_buff *skb)
{
bpf_printk("new packet captured (XDP)\n");
return XDP_PASS;
};
用户态的代码也和 tc 的代码一致,不做说明。
uprobe
uprobe 是 “User Probe” 的缩写,它利用了 Linux 内核中的 ftrace(function trace)框架来实现。通过 uprobe,可以在用户空间程序的指定函数入口或出口处插入探测点,当该函数被调用或返回时,可以触发事先定义的处理逻辑。kprobe 是用于监控内核态的程序,uprobe 就是用于监控用户态的程序。目前 uprobe 最常用的做法就是用在获取 bash 的命令。内核态代码如下所示:
SEC("uprobe/readline")
int uprobe_readline(void *ctx)
{
bpf_printk("new bash command detected\n");
return 0;
};
这个内核态的代码是用于监控 bash 命令的,当 bash 命令被执行时,就会触发 uprobe_readline 的执行,基本上和其他类型的监控事件没有差别。用户态代码如下所示:
m := &manager.Manager{
Probes: []*manager.Probe{
{
Section: "uprobe/readline",
EbpfFuncName: "uprobe_readline",
AttachToFuncName: "readline",
BinaryPath: "/usr/bin/bash",
},
},
}
uprobe 监控相比其他类型事件的监控存在一个很明显的差别,需要额外配置 BinaryPath。原因是因为 uprobe 针对用户态程序的监控,所以需要指定用户态程序的路径。在本例中,我们针对的是 bash 进程,所以需要指定 /usr/bin/bash,最终运行的结果如下所示:
