背景
传统的基于二层转发(Linux bridge、Netfilter/iptables、OVS 等)和/或三层路由的网络虚拟化方案中,数据包的转发路径通常非常清晰,通过一些常见工具或命令就能判断包的下一跳。当网络出现问题时,例如,一个容器访问另一个容器网络不通,只要沿着这条路径上的设备依次抓包,分析路由表、ARP 表,一般就能定位到问题。但是,如果容器网络使用的是 Cilium,上述网络排查手段是困难的或者失效的。
本文通过借助常规 Linux 工具来探索 Cilium 的整个转发路径,并分析在每个转发节点分别做了什么事情,深入理解 Cilium 技术原理,提升 Cilium 作为容器网络 CNI 故障排障能力。
说明
环境配置
➜ cilium-mesh kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
network-58bf9867cb-w48k4 1/1 Running 0 45m 10.0.0.250 192.168.1.15 <none> <none>
nginx-6d8cfb4ff7-bjqmh 1/1 Running 0 45m 10.0.1.60 192.168.1.13 <none> <none>
node-shell-debug-2skzt 1/1 Running 0 45m 192.168.1.15 192.168.1.15 <none> <none>
node-shell-debug-mp24n 1/1 Running 0 45m 192.168.1.13 192.168.1.13 <none> <none>
➜ cilium-mesh kubectl get svc -owide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 172.16.0.1 <none> 443/TCP 18d <none>
nginx ClusterIP 172.16.16.87 <none> 80/TCP 6h1m app=nginx
- Kubernetes:1.22.5
- Cilium:1.13.4

安装 Cilium
创建 Kubernetes 集群后,删除 kube-proxy Daemonset 组件,安装 Cilium。
CILIUM_CLI_VERSION=$(curl -s https://raw.githubusercontent.com/cilium/cilium-cli/master/stable.txt)
CLI_ARCH=amd64
if [ "$(uname -m)" = "arm64" ]; then CLI_ARCH=arm64; fi
curl -L --fail --remote-name-all https://github.com/cilium/cilium-cli/releases/download/${CILIUM_CLI_VERSION}/cilium-darwin-${CLI_ARCH}.tar.gz{,.sha256sum}
shasum -a 256 -c cilium-darwin-${CLI_ARCH}.tar.gz.sha256sum
sudo tar xzvfC cilium-darwin-${CLI_ARCH}.tar.gz /usr/local/bin
rm cilium-darwin-${CLI_ARCH}.tar.gz{,.sha256sum}
cilium install
➜ cilium-mesh cilium status
/¯¯\
/¯¯\__/¯¯\ Cilium: OK
\__/¯¯\__/ Operator: OK
/¯¯\__/¯¯\ Envoy DaemonSet: disabled (using embedded mode)
\__/¯¯\__/ Hubble Relay: disabled
\__/ ClusterMesh: disabled
DaemonSet cilium Desired: 2, Ready: 2/2, Available: 2/2
Deployment cilium-operator Desired: 1, Ready: 1/1, Available: 1/1
Containers: cilium Running: 2
cilium-operator Running: 1
Cluster Pods: 12/13 managed by Cilium
Helm chart version: 1.13.4
Image versions cilium quay.io/cilium/cilium:v1.13.4@sha256:bde8800d61aaad8b8451b10e247ac7bdeb7af187bb698f83d40ad75a38c1ee6b: 2
cilium-operator quay.io/cilium/operator-generic:v1.13.4@sha256:09ab77d324ef4d31f7d341f97ec5a2a4860910076046d57a2d61494d426c6301: 1
➜ cilium-mesh kubectl -nkube-system get pod | grep cilium
cilium-8b6x9 1/1 Running 0 10m
cilium-dpbbn 1/1 Running 0 10m
cilium-operator-798478fc69-w54xz 1/1 Running 0 10m
重点配置
Node 节点上 Cilium Agent 配置如下所示:
root@k8s-ig-m6f5hd49-fbso3h3g-ffcfq1uq:/home/cilium# cilium status
KVStore: Ok Disabled # 表示 Cilium 的分布式键值存储(KVStore)的状态是正常,但是被禁用。
Kubernetes: Ok 1.22 (v1.22.5) [linux/amd64] # 表示与 Kubernetes 的集成状态正常,并且使用的Kubernetes版本是1.22,对应的安全加固补丁版本是v1.22.5,运行的操作系统是Linux/amd64。
Kubernetes APIs: ["cilium/v2::CiliumClusterwideNetworkPolicy", "cilium/v2::CiliumEndpoint", "cilium/v2::CiliumNetworkPolicy", "cilium/v2::CiliumNode", "core/v1::Namespace", "core/v1::Node", "core/v1::Pods", "core/v1::Service", "discovery/v1::EndpointSlice", "networking.k8s.io/v1::NetworkPolicy"]
KubeProxyReplacement: Strict [eth0 192.168.1.15] # 表示Kubernetes的kube-proxy替换模式是严格模式,并且指定了网络接口eth0的IP地址为192.168.1.15。
Host firewall: Disabled # 表示主机的防火墙被禁用。
CNI Chaining: none # 表示CNI(网络配置和接口)的链式配置被禁用。
CNI Config file: CNI configuration file management disabled # 表示CNI配置文件的管理被禁用。
Cilium: Ok 1.13.4 (v1.13.4-4061cdfc)
NodeMonitor: Listening for events on 42 CPUs with 64x4096 of shared memory
Cilium health daemon: Ok
IPAM: IPv4: 8/254 allocated from 10.0.0.0/24, # 表示IP地址分配管理(IPAM)的状态正常,已经分配了8个IPv4地址,并且可用的IPv4地址数是254,分配的起始IP地址是10.0.0.0,掩码是24位。
IPv6 BIG TCP: Disabled # 表示IPv6的BIG TCP功能被禁用。
BandwidthManager: Disabled # 表示带宽管理器被禁用。
Host Routing: Legacy # 表示主机路由使用传统模式。
Masquerading: IPTables [IPv4: Enabled, IPv6: Disabled] # 表示伪装(Masquerading)使用IPTables,IPv4被启用,IPv6被禁用。
Controller Status: 42/42 healthy
Proxy Status: OK, ip 10.0.0.175, 0 redirects active on ports 10000-20000
Global Identity Range: min 256, max 65535 # 表示全局身份范围的最小值是256,最大值是65535。
Hubble: Ok Current/Max Flows: 4095/4095 (100.00%), Flows/s: 3.75 Metrics: Disabled
Encryption: Disabled # 表示加密功能被禁用。
Cluster health: 2/2 reachable (2023-07-14T02:41:02Z) # 表示集群的健康状态正常,可以访问两个节点。
- KubeProxyReplacement:Cilium将尽力替代Kube-Proxy,并尝试实现服务负载均衡和网络代理功能。
- Disabled:禁用模式,不使用 Cilium eBPF kube-proxy replacement,保留传统的 kube-proxy 运行方式。
- Strict:严格模式,使用 Cilium eBPF kube-proxy replacement 完全替换 kube-proxy 的运行方式。
- Partial:部分模式,同时使用 kube-proxy 和 Cilium eBPF kube-proxy replacement,用户需要手动指定需要替换的功能。
- Probe:自动探测是否启动 Cilium 替换 kube-proxy。
- CNI Chaining:允许Cilium与其他容器网络接口(Container Network Interface)插件进行协同工作,以支持网络功能的链式连接和集成。
- Host Routing:通过在主机上配置路由表,将特定的流量路由到Cilium代理,以实现服务发现和网络转发。
- Legacy 模式:部分网络数据包依然使用主机路由,依赖了iptables 等 Netfilter。
- BPF模式:在BPF模式下,Cilium代理会使用eBPF程序来拦截和重新处理主机相关的IP流量。eBPF程序会对流量进行检查和转发,而不需要创建额外的网络接口,这种模式下,Cilium使用的是Linux内核中的BPF功能来实现路由和过滤。要求:内核 >= 5.10、直接路由配置或隧道、基于 eBPF 的 kube-proxy 替换、基于 eBPF 的 masquerading 等。
- Masquerading:用于将出站流量的源IP地址伪装为主机的IP地址,以实现网络地址转换(NAT)功能。
其他参数可参考附录。
工具
以下脚本是在宿主机上使用 nsenter 根据容器名称或者容器 id 进入容器执行相关网络配置。
#/bin/bash
CTN=$1 # container ID or name
PID=$(sudo docker inspect --format "{{.State.Pid}}" $CTN)
shift 1 # remove the first argument, shift others to the left
nsenter -t $PID $@
核心流程
步骤-请求数据包路径流程
Request Traffic path of Pod-to-ServiceIP 数据路径全景图:

具体来说,我们从一个 Pod 访问 ServiceIP 开始,并假设这个 ServiceIP 对应的后端 Pod 位于另一台 node 上,然后探索包所经过的路径和处理过程。
步骤1 从 Pod network 中向 nginx 发送请求

访问 nginx Service IP
从 node1 上的 network 中访问位于 node2 上的 nginx clusterIP。
cilium-mesh kubectl exec -it network-58bf9867cb-w48k4 -- curl -I 172.16.16.87:80
HTTP/1.1 200 OK
Server: nginx/1.14.2
Date: Tue, 11 Jul 2023 12:07:00 GMT
Content-Type: text/html
Content-Length: 612
Last-Modified: Tue, 04 Dec 2018 14:44:49 GMT
Connection: keep-alive
ETag: "5c0692e1-264"
Ak8spt-Ranges: bytes
在 network 所在的宿主机上抓取网络包,如下所示,发现请求的 clusterIP 变成了 nginx 的 pod IP,Pod 内并无 iptables 规则或 ipvs 规则。

root@k8s-ig-m6f5hd49-fbso3h3g-ffcfq1uq:/# docker ps | grep network
061adb799d0c registry.xxx.com/csm/network-multitool "/bin/sh /docker/ent…" 27 minutes ago Up 27 minutes k8s_network_network-58bf9867cb-w48k4_default_831e9a61-1d51-49b9-8f24-4806edfefb37_0
099e456f401b registry.xxx.com/k8s-public/pause:3.1 "/pause" 27 minutes ago Up 27 minutes k8s_POD_network-58bf9867cb-w48k4_default_831e9a61-1d51-49b9-8f24-4806edfefb37_3
root@k8s-ig-m6f5hd49-fbso3h3g-ffcfq1uq:/# bash nsenter.sh 061adb799d0c -n tcpdump -n -i eth0
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
20:11:43.981031 IP 10.0.0.250.40418 > 10.0.1.60.80: Flags [S], seq 3978619682, win 64860, options [mss 1410,sackOK,TS val 2911480627 ecr 0,nop,wscale 7], length 0
20:11:43.981444 IP 10.0.1.60.80 > 10.0.0.250.40418: Flags [S.], seq 3647241102, ack 3978619683, win 64308, options [mss 1410,sackOK,TS val 2294711974 ecr 2911480627,nop,wscale 7], length 0
20:11:43.981464 IP 10.0.0.250.40418 > 10.0.1.60.80: Flags [.], ack 1, win 507, options [nop,nop,TS val 2911480628 ecr 2294711974], length 0
20:11:43.981528 IP 10.0.0.250.40418 > 10.0.1.60.80: Flags [P.], seq 1:78, ack 1, win 507, options [nop,nop,TS val 2911480628 ecr 2294711974], length 77: HTTP: HEAD / HTTP/1.1
20:11:43.981685 IP 10.0.1.60.80 > 10.0.0.250.40418: Flags [.], ack 78, win 502, options [nop,nop,TS val 2294711975 ecr 2911480628], length 0
20:11:43.981797 IP 10.0.1.60.80 > 10.0.0.250.40418: Flags [P.], seq 1:239, ack 78, win 502, options [nop,nop,TS val 2294711975 ecr 2911480628], length 238: HTTP: HTTP/1.1 200 OK
20:11:43.981804 IP 10.0.0.250.40418 > 10.0.1.60.80: Flags [.], ack 239, win 506, options [nop,nop,TS val 2911480628 ecr 2294711975], length 0
20:11:43.981947 IP 10.0.0.250.40418 > 10.0.1.60.80: Flags [F.], seq 78, ack 239, win 506, options [nop,nop,TS val 2911480628 ecr 2294711975], length 0
20:11:43.982082 IP 10.0.1.60.80 > 10.0.0.250.40418: Flags [F.], seq 239, ack 79, win 502, options [nop,nop,TS val 2294711975 ecr 2911480628], length 0
20:11:43.982088 IP 10.0.0.250.40418 > 10.0.1.60.80: Flags [.], ack 240, win 506, options [nop,nop,TS val 2911480629 ecr 2294711975], length 0
现在先不分析如何实现该功能,下文在做原因分析。
1.2 确定下一跳目的 MAC 地址
包会从 network 容器的 eth0 虚拟网卡发出去,此时能确定的 IP 和 MAC 地址信息:
1. src_ip=POD1_IP
2. src_mac=POD1_MAC
3. dst_ip=ServiceIP
那么目的 MAC 是如何获取的呢?首先,查看 network 容器中的路由表与 ARP 表,PodCIDR 是由 Cilium agent 启动时自己配置,具体可以参考宿主机上的 ifconfig cilium_host。
root@k8s-ig-m6f5hd49-fbso3h3g-ffcfq1uq:/# bash nsenter.sh 061adb799d0c -n route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.0.0.175 0.0.0.0 UG 0 0 0 eth0
10.0.0.175 0.0.0.0 255.255.255.255 UH 0 0 0 eth0
root@k8s-ig-m6f5hd49-fbso3h3g-ffcfq1uq:/# ifconfig cilium_host
cilium_host: flags=4291<UP,BROADCAST,RUNNING,NOARP,MULTICAST> mtu 1500
inet 10.0.0.175 netmask 255.255.255.255 broadcast 0.0.0.0
inet6 fe80::f8df:9eff:fea4:e2b9 prefixlen 64 scopeid 0x20<link>
ether fa:df:9e:a4:e2:b9 txqueuelen 1000 (Ethernet)
RX packets 253 bytes 19455 (19.4 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 19 bytes 1398 (1.3 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
因为 nginx 的 service IP 是 172.16.16.87,下一跳就是网关 10.0.0.175。 所以,dst_mac 就要填 10.0.0.175 对应的 MAC。MAC 和 IP 的对应关系在 ARP 表里。network 容器中的 ARP 表:
root@k8s-ig-m6f5hd49-fbso3h3g-ffcfq1uq:/# bash nsenter.sh 061adb799d0c -n arp -n
Address HWtype HWaddress Flags Mask Iface
10.0.0.175 ether 66:94:e5:1d:37:df C eth0
对应的 MAC 地址是 66:94:e5:1d:37:df,此时网络数据包就可以正常发送出去。 随着 Linux 网络虚拟化技术的演进,有了若干种虚拟化网络设备,典型的有 Tap/Tun、Veth、Bridge 等。在宿主机上查看该 MAC 地址属于哪个虚拟网络设备。
root@k8s-ig-m6f5hd49-fbso3h3g-ffcfq1uq:/# ip link | grep 66:94:e5:1d:37:df -C 5
16: lxc7d69da958e9b@if15: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 3a:ad:aa:56:5c:76 brd ff:ff:ff:ff:ff:ff link-netnsid 4
18: lxccc5e68dbcc4a@if17: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether b2:7b:2c:80:75:9e brd ff:ff:ff:ff:ff:ff link-netnsid 5
20: lxc84a447e034a3@if19: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 66:94:e5:1d:37:df brd ff:ff:ff:ff:ff:ff link-netnsid 6
在容器 network 查看虚拟容器网络设备。
root@k8s-ig-m6f5hd49-fbso3h3g-ffcfq1uq:/# bash nsenter.sh 061adb799d0c -n ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
19: eth0@if20: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether b6:48:79:16:47:7a brd ff:ff:ff:ff:ff:ff link-netnsid 0
可以看到,容器的 eth0 index 就是 19,对端是 20。而这个 66:94:e5:1d:37:df MAC 属于 lxc84a447e034a3 设备,并且从 @ 符号判断,它属于某个 veth pair 的一端,另一端的 interface index 是 19。
我们发现容器将 Pod 流量的下一跳劫持到 veth pair 的主机端。接下来分析网络数据包在 Node1 宿主机上的处理过程。
步骤2 Pod1 eth0对端lxc84a447e034a3虚拟网络流量处理

2.1 宿主机 lxc84a447e034a3 虚拟网络设备分析
网络数据包到达了 Node1 节点上的 lxc84a447e034a3,此时在宿主机上抓取网络虚拟设备 lxc84a447e034a3 包。
root@k8s-ig-m6f5hd49-fbso3h3g-ffcfq1uq:/# tcpdump -n -i lxc84a447e034a3
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on lxc84a447e034a3, link-type EN10MB (Ethernet), capture size 262144 bytes
20:43:23.980960 IP 10.0.0.250.56510 > 10.0.1.60.80: Flags [S], seq 1324573640, win 64860, options [mss 1410,sackOK,TS val 2913380627 ecr 0,nop,wscale 7], length 0
20:43:23.981369 IP 10.0.1.60.80 > 10.0.0.250.56510: Flags [S.], seq 3536933088, ack 1324573641, win 64308, options [mss 1410,sackOK,TS val 2296611975 ecr 2913380627,nop,wscale 7], length 0
20:43:23.981386 IP 10.0.0.250.56510 > 10.0.1.60.80: Flags [.], ack 1, win 507, options [nop,nop,TS val 2913380628 ecr 2296611975], length 0
20:43:24.080138 IP 10.0.0.250.56510 > 10.0.1.60.80: Flags [P.], seq 1:78, ack 1, win 507, options [nop,nop,TS val 2913380727 ecr 2296611975], length 77: HTTP: HEAD / HTTP/1.1
20:43:24.080363 IP 10.0.1.60.80 > 10.0.0.250.56510: Flags [.], ack 78, win 502, options [nop,nop,TS val 2296612074 ecr 2913380727], length 0
20:43:24.080517 IP 10.0.1.60.80 > 10.0.0.250.56510: Flags [P.], seq 1:239, ack 78, win 502, options [nop,nop,TS val 2296612074 ecr 2913380727], length 238: HTTP: HTTP/1.1 200 OK
20:43:24.080525 IP 10.0.0.250.56510 > 10.0.1.60.80: Flags [.], ack 239, win 506, options [nop,nop,TS val 2913380727 ecr 2296612074], length 0
20:43:24.080935 IP 10.0.0.250.56510 > 10.0.1.60.80: Flags [F.], seq 78, ack 239, win 506, options [nop,nop,TS val 2913380727 ecr 2296612074], length 0
20:43:24.081093 IP 10.0.1.60.80 > 10.0.0.250.56510: Flags [F.], seq 239, ack 79, win 502, options [nop,nop,TS val 2296612075 ecr 2913380727], length 0
20:43:24.081103 IP 10.0.0.250.56510 > 10.0.1.60.80: Flags [.], ack 240, win 506, options [nop,nop,TS val 2913380728 ecr 2296612075], length 0
20:43:29.150560 ARP, Request who-has 10.0.0.175 tell 10.0.0.250, length 28
20:43:29.150576 ARP, Reply 10.0.0.175 is-at 66:94:e5:1d:37:df, length 28
如上所述,获取到了请求目的 Pod IP 的报文,查看宿主机 Node1 上的路由规则:
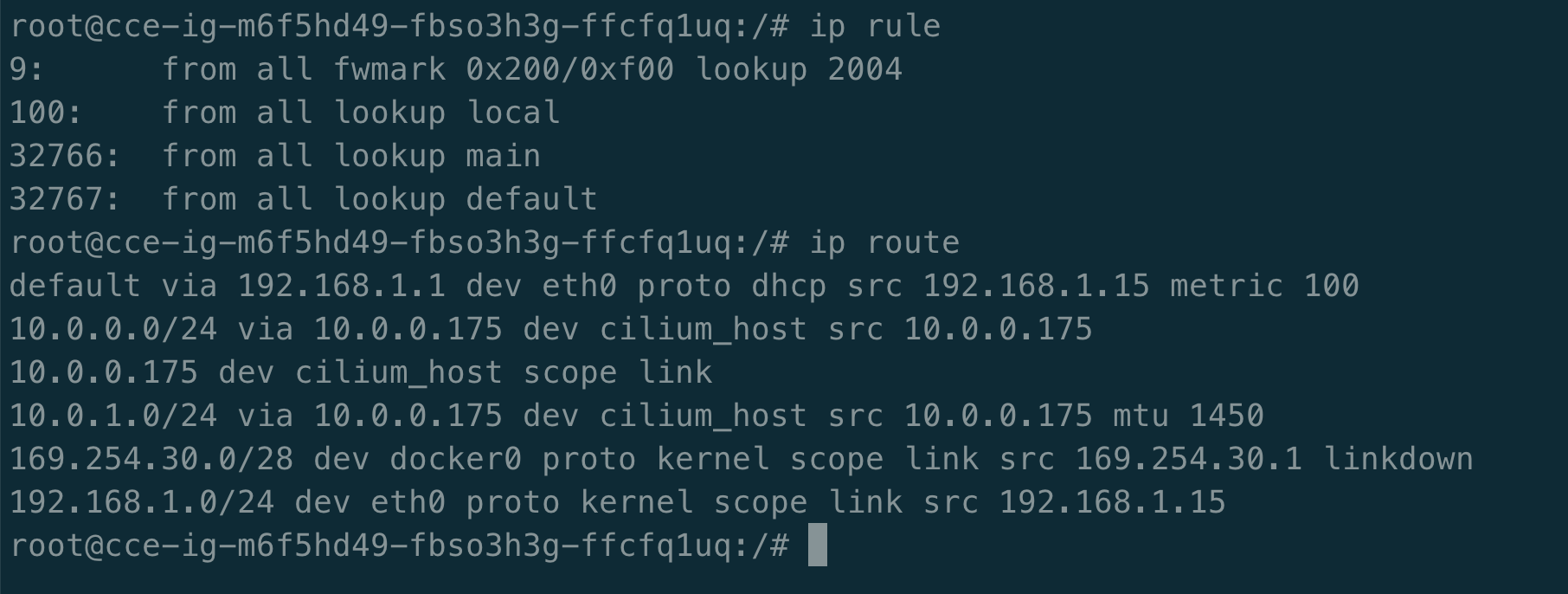
root@k8s-ig-m6f5hd49-fbso3h3g-ffcfq1uq:/# ip rule
# 这条规则表示匹配所有来源地址的流量,且满足标记位(fwmark)为0x200的范围(0xf00)的流量。
# 这些流量将被发送到编号为2004的路由表进行处理。
9: from all fwmark 0x200/0xf00 lookup 2004
# 这条规则表示任何来源地址的流量都将被直接发送到本地路由表进行处理。本地路由表通常包含了与本地主机直接相连的网络。
100: from all lookup local
# 这条规则表示所有来源地址的流量都将通过使用默认的主路由表进行处理。主路由表通常包含了大部分的路由信息。
32766: from all lookup main
# 这条规则表示任何来源地址的流量都将通过使用默认的默认路由表进行处理。默认路由表通常包含了通向外部网络的默认路由。
32767: from all lookup default
root@k8s-ig-m6f5hd49-fbso3h3g-ffcfq1uq:/# ip route
#这条规则代表默认路由,指定了当目标地址不符合任何其他路由规则时,通过网关192.168.1.1以太网接口eth0转发流量。
#源IP地址被指定为192.168.1.15,并设置了metric指标为100。
#也就是说,如果目标地址不在本地子网或其他特定路由表中,则流量将被发送到网关192.168.1.1。
default via 192.168.1.1 dev eth0 proto dhcp src 192.168.1.15 metric 100
#这条规则表示目标子网10.0.0.0/24通过网关10.0.0.175和cilium_host接口转发,源IP地址为10.0.0.175。
10.0.0.0/24 via 10.0.0.175 dev cilium_host src 10.0.0.175
#这条规则表示目标地址为10.0.0.175的流量将直接在cilium_host接口上进行处理,作用范围仅限于本地链接。
10.0.0.175 dev cilium_host scope link
# 这条规则与第二条类似,目标子网为10.0.1.0/24,通过网关10.0.0.175和cilium_host接口转发,
# 源IP地址为10.0.0.175,并设置最大传输单元(MTU)为1450字节。
10.0.1.0/24 via 10.0.0.175 dev cilium_host src 10.0.0.175 mtu 1450
# 这条规则表示目标子网169.254.30.0/28直接在docker0接口上进行处理,由内核协议处理,作用范围仅限于本地链接。
# 此路由规则的状态是down,可能是因为docker0接口当前不可用。
169.254.30.0/28 dev docker0 proto kernel scope link src 169.254.30.1 linkdown
#这条规则表示目标子网192.168.1.0/24直接在eth0接口上进行处理,由内核协议处理,作用范围仅限于本地链接,源IP地址为192.168.1.15。
192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.15
从上文中得知 nginx 的 service IP 是 172.16.16.87,下一跳就是网关 10.0.0.175,所以网络数据包从 Node1 上的 dev cilium_host 发送出去。
问题:Node1 上的网络设备抓取不到 Pod IP 报文?
Cilium使用VXLAN隧道作为默认的Overlay模式,用于跨节点的容器通信。Cilium的VXLAN隧道模式会将容器之间的通信流量封装在VXLAN头部中,并通过Underlay网络(通常是物理网络)进行传输。
2.2 查看 BPF 程序
包从容器 eth0 发出,然后被 lxc84a447e034a3 收进来,因此在 lxc 的 tc ingress hook 能对 容器发出的包 进行拦截和处理。
root@k8s-ig-m6f5hd49-fbso3h3g-ffcfq1uq:/# tc filter show dev lxc84a447e034a3 ingress
filter protocol all pref 1 bpf chain 0
filter protocol all pref 1 bpf chain 0 handle 0x1 cil_from_container-lxc84a447e034a3 direct-action not_in_hw id 512 tag 0526e3710160da95 jited
root@k8s-ig-m6f5hd49-fbso3h3g-ffcfq1uq:/# tc filter show dev lxc84a447e034a3 egress
root@k8s-ig-m6f5hd49-fbso3h3g-ffcfq1uq:/# bash nsenter.sh 061adb799d0c -n tc filter show dev eth0 ingress
root@k8s-ig-m6f5hd49-fbso3h3g-ffcfq1uq:/# bash nsenter.sh 061adb799d0c -n tc filter show dev eth0 egress
可以看到,在 tc ingress hook 点加载了 cil_from_container-lxc84a447e034a3 BPF 程序。 在 veth pair 模式中,用上面的 tc 命令分别在容器eth0 的 ingress/egress 以 及 lxc84a447e034a3 的 egress 点查看, 最后会发现这些地方都没有加载 BPF。没有相应的 BPF,怎么对容器的入向包做拦截和处理呢?我们后面在揭晓,先保留疑问。
2.3 理解 cil_from_container BPF 程序
#define __section_entry __section("tc")
/* Attachment/entry point is ingress for veth.
* It corresponds to packets leaving the container.
*/
__section_entry
int cil_from_container(struct __ctx_buff *ctx)
{
__u16 proto;
int ret;
bpf_clear_meta(ctx);
reset_queue_mapping(ctx);
send_trace_notify(ctx, TRACE_FROM_LXC, SECLABEL, 0, 0, 0,
TRACE_REASON_UNKNOWN, TRACE_PAYLOAD_LEN);
if (!validate_ethertype(ctx, &proto)) {
ret = DROP_UNSUPPORTED_L2;
goto out;
}
switch (proto) {
#ifdef ENABLE_IPV6
case bpf_htons(ETH_P_IPV6):
edt_set_aggregate(ctx, LXC_ID);
ep_tail_call(ctx, CILIUM_CALL_IPV6_FROM_LXC);
ret = DROP_MISSED_TAIL_CALL;
break;
#endif /* ENABLE_IPV6 */
#ifdef ENABLE_IPV4
case bpf_htons(ETH_P_IP):
edt_set_aggregate(ctx, LXC_ID);
ep_tail_call(ctx, CILIUM_CALL_IPV4_FROM_LXC);
ret = DROP_MISSED_TAIL_CALL;
break;
#ifdef ENABLE_ARP_PASSTHROUGH
case bpf_htons(ETH_P_ARP):
ret = CTX_ACT_OK;
break;
#elif defined(ENABLE_ARP_RESPONDER)
case bpf_htons(ETH_P_ARP):
ep_tail_call(ctx, CILIUM_CALL_ARP);
ret = DROP_MISSED_TAIL_CALL;
break;
#endif /* ENABLE_ARP_RESPONDER */
#endif /* ENABLE_IPV4 */
default:
ret = DROP_UNKNOWN_L3;
}
out:
if (IS_ERR(ret))
return send_drop_notify(ctx, SECLABEL, 0, 0, ret, CTX_ACT_DROP,
METRIC_EGRESS);
return ret;
}
declare_tailcall_if(is_defined(ENABLE_PER_PACKET_LB), CILIUM_CALL_IPV4_FROM_LXC_CONT)
int tail_handle_ipv4_cont(struct __ctx_buff *ctx)
{
__u32 dst_sec_identity = 0;
__s8 ext_err = 0;
int ret = handle_ipv4_from_lxc(ctx, &dst_sec_identity, &ext_err);
if (IS_ERR(ret))
return send_drop_notify_ext(ctx, SECLABEL, dst_sec_identity, 0, ret, ext_err,
CTX_ACT_DROP, METRIC_EGRESS);
#ifdef ENABLE_CUSTOM_CALLS
if (!encode_custom_prog_meta(ctx, ret, dst_sec_identity)) {
tail_call_static(ctx, &CUSTOM_CALLS_MAP,
CUSTOM_CALLS_IDX_IPV4_EGRESS);
update_metrics(ctx_full_len(ctx), METRIC_EGRESS,
REASON_MISSED_CUSTOM_CALL);
}
#endif
return ret;
}
函数比较长,下图保留核心流程。
static __always_inline int handle_ipv4_from_lxc(struct __ctx_buff *ctx, __u32 *dst_sec_identity,
__s8 *ext_err)
handle_ipv4_from_lxc
ENABLE_XXX
ENABLE_ROUTING
ENABLE_PER_PACKET_LB
ENABLE_L7_LB
ENABLE_HOST_FIREWALL
ENABLE_EGRESS_GATEWAY
ENABLE_VTEP
TUNNEL_MODE
ENABLE_HIGH_SCALE_IPCACHE
ENABLE_CLUSTER_AWARE_ADDRESSING
per_packet_lb_svc_xlate_4
lb4_local
ct_lazy_lookup4
lb4_select_backend_id
ct_create4
lb4_lookup_backend
lb4_xlate
skip_policy_enforcement # 策略检查
lookup_ip4_remote_endpoint # 确定策略回退的目标类别。
# 如果数据包处于建立连接的方向,并且目标地址在集群内部,它必须匹配策略或被丢弃。
# 如果它是发送到主机/外部的,执行CIDR策略检查。
policy_can_egress4
Cilium 各种模式选择与转发
return CTX_ACT_OK
cil_from_container 使用调用栈简化上图流程:
1. bpf_clear_meta 清理元数据。
2. reset_queue_mapping 解决GH-18311的问题,其中veth驱动程序可能记录了veth的RX队列映射,而没有将其保留在0上。这可能会导致在物理设备上出现问题,所有流量只会命中单个TX队列(假设veth设备只有一个并且映射被保留为1)。重置以便堆栈选择一个新的队列。
3. 对包进行验证,并提取出 L3 proto(协议类型)。
4. 如果 L3 proto 是 IPv4,调用 ep_tail_call进行处理。也支持 ipv6、ARP_PASSTHROUGH等。
5. ep_tail_call 进一步调用 tail_call_static,然后尾调用 tail_handle_ipv4_cont, 后者完成:
a. Service 负载均衡,即从 Service 的后端 Pod 中选择一个合适的,假设选择 Node2 上的 pod2。
b. 创建或更新连接跟踪(CT)记录。
c. 执行 DNAT,将包的目的 IP 由 ServiceIP 改成 pod2 pod IP。
d. 进行容器出向(egress)安全策略验证。
e. 对包进行封装,或者通过主机进行路由。
f. 在主机转发网络数据包时,在送回协议栈之前,调用 ipv4_l3 设置 TTL、MAC 地址。
6. BPF 程序最后返回 CTX_ACT_OK,这个包就进入内核协议栈继续处理。
pass_to_stack:
#ifdef ENABLE_ROUTING
ret = ipv4_l3(ctx, ETH_HLEN, NULL, (__u8 *)&router_mac.addr, ip4);
if (unlikely(ret != CTX_ACT_OK))
return ret;
#endif
static __always_inline int ipv4_l3(struct __ctx_buff *ctx, int l3_off,
const __u8 *smac, const __u8 *dmac,
struct iphdr *ip4)
{
if (ipv4_dec_ttl(ctx, l3_off, ip4)) {
/* FIXME: Send ICMP TTL */
return DROP_INVALID;
}
if (smac && eth_store_saddr(ctx, smac, 0) < 0)
return DROP_WRITE_ERROR;
if (dmac && eth_store_daddr(ctx, dmac, 0) < 0)
return DROP_WRITE_ERROR;
return CTX_ACT_OK;
}
static __always_inline int ipv4_dec_ttl(struct __ctx_buff *ctx, int off,
const struct iphdr *ip4)
{
__u8 new_ttl, ttl = ip4->ttl;
if (ttl <= 1)
return 1;
new_ttl = ttl - 1;
/* l3_csum_replace() takes at min 2 bytes, zero extended. */
ipv4_csum_update_by_value(ctx, off, ttl, new_ttl, 2);
ctx_store_bytes(ctx, off + offsetof(struct iphdr, ttl), &new_ttl, sizeof(new_ttl), 0);
return 0;
}
步骤3 Node1 物理网卡 egress BPF 程序处理

3.1 查看 BPF 程序
查看 eth0 设备上的 egress BPF,这是包出宿主机之前最后的 tc BPF hook 点:
root@k8s-ig-m6f5hd49-fbso3h3g-ffcfq1uq:/# tc filter show dev eth0 egress
filter protocol all pref 1 bpf chain 0
filter protocol all pref 1 bpf chain 0 handle 0x1 cil_to_netdev-eth0 direct-action not_in_hw id 500 tag e00d90807b2c4cda jited
3.2 理解 cil_to_netdev BPF 程序
to-netdev 被附加为 tc egress 过滤器到由Cilium管理的一个或多个物理设备(例如eth0),只有在以下情况才会附加这个程序:
- 主机启用防火墙
- 启用了 BPF NodePort
/*
* to-netdev is attached as a tc egress filter to one or more physical devices
* managed by Cilium (e.g., eth0). This program is only attached when:
* - the host firewall is enabled, or
* - BPF NodePort is enabled
*/
__section("to-netdev")
int cil_to_netdev(struct __ctx_buff *ctx __maybe_unused)
{
struct trace_ctx trace = {
.reason = TRACE_REASON_UNKNOWN,
.monitor = 0,
};
__u16 __maybe_unused proto = 0;
__u32 __maybe_unused vlan_id;
int ret = CTX_ACT_OK;
#ifdef ENABLE_HOST_FIREWALL
__s8 ext_err = 0;
#endif
/* Filter allowed vlan id's and pass them back to kernel.
*/
if (ctx->vlan_present) {
vlan_id = ctx->vlan_tci & 0xfff;
if (vlan_id) {
if (allow_vlan(ctx->ifindex, vlan_id))
return CTX_ACT_OK;
else
return send_drop_notify_error(ctx, 0, DROP_VLAN_FILTERED,
CTX_ACT_DROP, METRIC_EGRESS);
}
}
#if defined(ENABLE_L7_LB)
{
__u32 magic = ctx->mark & MARK_MAGIC_HOST_MASK;
if (magic == MARK_MAGIC_PROXY_EGRESS_EPID) {
__u32 lxc_id = get_epid(ctx);
ctx->mark = 0;
tail_call_dynamic(ctx, &POLICY_EGRESSCALL_MAP, lxc_id);
return send_drop_notify_error(ctx, 0, DROP_MISSED_TAIL_CALL,
CTX_ACT_DROP, METRIC_EGRESS);
}
}
#endif
#ifdef ENABLE_HOST_FIREWALL
if (!proto && !validate_ethertype(ctx, &proto)) {
ret = DROP_UNSUPPORTED_L2;
goto out;
}
policy_clear_mark(ctx);
switch (proto) {
# if defined ENABLE_ARP_PASSTHROUGH || defined ENABLE_ARP_RESPONDER
case bpf_htons(ETH_P_ARP):
ret = CTX_ACT_OK;
break;
# endif
# ifdef ENABLE_IPV6
case bpf_htons(ETH_P_IPV6):
ret = handle_to_netdev_ipv6(ctx, &trace, &ext_err);
break;
# endif
# ifdef ENABLE_IPV4
case bpf_htons(ETH_P_IP): {
ret = handle_to_netdev_ipv4(ctx, &trace, &ext_err);
break;
}
# endif
default:
ret = DROP_UNKNOWN_L3;
break;
}
out:
if (IS_ERR(ret))
return send_drop_notify_error_ext(ctx, 0, ret, ext_err,
CTX_ACT_DROP, METRIC_EGRESS);
#endif /* ENABLE_HOST_FIREWALL */
#if defined(ENABLE_BANDWIDTH_MANAGER)
ret = edt_sched_departure(ctx);
/* No send_drop_notify_error() here given we're rate-limiting. */
if (ret == CTX_ACT_DROP) {
update_metrics(ctx_full_len(ctx), METRIC_EGRESS,
-DROP_EDT_HORIZON);
return ret;
}
#endif
#ifdef ENABLE_SRV6
ret = handle_srv6(ctx);
if (ret != CTX_ACT_OK)
return send_drop_notify_error(ctx, 0, ret, CTX_ACT_DROP,
METRIC_EGRESS);
#endif /* ENABLE_SRV6 */
#ifdef ENABLE_NODEPORT
if (!ctx_snat_done(ctx)) {
/*
* handle_nat_fwd tail calls in the majority of cases,
* so control might never return to this program.
*/
ret = handle_nat_fwd(ctx);
if (IS_ERR(ret))
return send_drop_notify_error(ctx, 0, ret,
CTX_ACT_DROP,
METRIC_EGRESS);
}
#endif
#ifdef ENABLE_HEALTH_CHECK
ret = lb_handle_health(ctx);
if (IS_ERR(ret))
return send_drop_notify_error(ctx, 0, ret, CTX_ACT_DROP,
METRIC_EGRESS);
#endif
send_trace_notify(ctx, TRACE_TO_NETWORK, 0, 0, 0,
0, trace.reason, trace.monitor);
return ret;
}
cil_to_netdev
ENABLE_XXX
ENABLE_HOST_FIREWALL
ENABLE_L7_LB
ENABLE_IPV4
ENABLE_IPV6
ENABLE_SRV6
ENABLE_HEALTH_CHECK
ENABLE_NODEPORT
ENABLE_ARP_PASSTHROUGH
ENABLE_ARP_RESPONDER
allow_vlan
policy_clear_mark
handle_to_netdev_ipv4
resolve_srcid_ipv4
lookup_ip4_remote_endpoint
srcid_from_ipcache
revalidate_data
ipv4_host_policy_egress
whitelist_snated_egress_connections
revalidate_data
policy_can_egress4 # /* Perform policy lookup. */
ct_create4
send_policy_verdict_notify
handle_nat_fwd
lb_handle_health
return CTX_ACT_OK
cil_to_netdev 调用栈简化上图流程:
1. allow_vlan 过滤允许的 VLAN ID,并将其传递回内核。
2. policy_clear_mark 策略初始化。
3. handle_to_netdev_ipv4 完成主机数据包出主机时对数据包进行处理:
a. 当主机需要发出数据包时,to-netdev 程序会拦截这些数据包,并使用 handle_to_netdev_ipv4 方法进行处理。如果数据包符合主机的防火墙策略,或者需要经过 NodePort 的 SNAT 处理,数据包会被允许通过;否则,数据包将被丢弃或者被进行其他处理。
b. resolve_srcid_ipv4 解析源自代理的源 ID,并根据配置的映射表和安全策略来确定数据包的真正源 ID,并将其存储在 sec_label指向的内存位置。
c. revalidate_data 校验数据的合法性
d. ipv4_host_policy_egress 用于在 IPv4 主机出口策略的上下文中处理数据包,并根据配置的策略规则对数据包进行相应的处理操作。
4. BPF 程序最后返回 CTX_ACT_OK,继续在内核协议栈处理。
Host Native device 上的 BPF 主要处理南北向流量,即容器和集群外交互的流量 。这包括 LoadBalancer Service 流量、带 externalIPs 的 Service 流量、NodePort Service 流量等。
3.3 确定源与目的 MAC 地址
查看宿主机的路由表与ARP表。
root@k8s-ig-m6f5hd49-fbso3h3g-ffcfq1uq:/# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.1.1 0.0.0.0 UG 100 0 0 eth0
10.0.0.0 10.0.0.175 255.255.255.0 UG 0 0 0 cilium_host
10.0.0.175 0.0.0.0 255.255.255.255 UH 0 0 0 cilium_host
10.0.1.0 10.0.0.175 255.255.255.0 UG 0 0 0 cilium_host
169.254.30.0 0.0.0.0 255.255.255.240 U 0 0 0 docker0
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
root@k8s-ig-m6f5hd49-fbso3h3g-ffcfq1uq:/# arp -n
Address HWtype HWaddress Flags Mask Iface
192.168.1.1 ether fa:28:00:14:3f:94 C eth0
192.168.1.13 ether fa:28:00:14:3f:94 C eth0
命中宿主机默认路由,因此会执行以下操作:
- 将 eth0 的 MAC 作为 src_mac:MAC 地址只在二层网络内有效,宿主机和 Pod 属于不同二层网络(Cilium 自己管理了一个 CIDR),宿主机做转发时会将 src_mac 换成自己的 MAC。
- 将宿主机网关对应的 MAC 作为 dst_mac:下一跳是宿主机网关。
步骤4 VPC 网络路由处理

4.1 内核转发 Pod 网络数据包
查看宿主机 node1 上的路由表,根据目的 pod2 IP 判断网络下一跳,内核路由表如下所示:
root@k8s-ig-m6f5hd49-fbso3h3g-ffcfq1uq:/# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.1.1 0.0.0.0 UG 100 0 0 eth0
10.0.0.0 10.0.0.175 255.255.255.0 UG 0 0 0 cilium_host
10.0.0.175 0.0.0.0 255.255.255.255 UH 0 0 0 cilium_host
10.0.1.0 10.0.0.175 255.255.255.0 UG 0 0 0 cilium_host
169.254.30.0 0.0.0.0 255.255.255.240 U 0 0 0 docker0
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
根据以上路由规则,只要目的 IP 不是本机 PodCIDR 网段的,都会命中默认路由 ,走网络设备 eth0。
4.2 Node 到 Node 网络处理
从源 Node 到 目的 Node 请求转发由底层 VPC 网络完成,涉及跨主机网络方案,不做过多的阐述。数据中心网络根据 dst_ip 对包进行路由。知识点:
- 在二层/大二层网络中,对于同一个包,发送方和接收方看到的 src_mac 是一样的,因为二层转发只修改 dst_mac,不会修改 src_mac。
- 三层组网中,src_mac 和 dst_mac 都会变。
步骤5 Node2 物理网卡 ingress BPF 程序处理

5.1 查看 Node2 上的路由规则
查看宿主机 Node2 和 Pod2 nginx 上的路由表、ARP 表。
root@k8s-ig-m6f5hd49-2ie613z6-ffcfq1uq:/# ip rule
9: from all fwmark 0x200/0xf00 lookup 2004
100: from all lookup local
32766: from all lookup main
32767: from all lookup default
root@k8s-ig-m6f5hd49-2ie613z6-ffcfq1uq:/# ip route
default via 192.168.1.1 dev eth0 proto dhcp src 192.168.1.13 metric 100
10.0.0.0/24 via 10.0.1.172 dev cilium_host src 10.0.1.172 mtu 1450
10.0.1.0/24 via 10.0.1.172 dev cilium_host src 10.0.1.172
10.0.1.172 dev cilium_host scope link
169.254.30.0/28 dev docker0 proto kernel scope link src 169.254.30.1 linkdown
192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.13
root@k8s-ig-m6f5hd49-2ie613z6-ffcfq1uq:/# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.1.1 0.0.0.0 UG 100 0 0 eth0
10.0.0.0 10.0.1.172 255.255.255.0 UG 0 0 0 cilium_host
10.0.1.0 10.0.1.172 255.255.255.0 UG 0 0 0 cilium_host
10.0.1.172 0.0.0.0 255.255.255.255 UH 0 0 0 cilium_host
169.254.30.0 0.0.0.0 255.255.255.240 U 0 0 0 docker0
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
查看 Pod2 在宿主机上的对端网络设备是 lxc493a9120593a。
root@k8s-ig-m6f5hd49-2ie613z6-ffcfq1uq:/# bash nsenter.sh 02f75de6e631 -n route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.0.1.172 0.0.0.0 UG 0 0 0 eth0
10.0.1.172 0.0.0.0 255.255.255.255 UH 0 0 0 eth0
root@k8s-ig-m6f5hd49-2ie613z6-ffcfq1uq:/# bash nsenter.sh 02f75de6e631 -n arp -n
Address HWtype HWaddress Flags Mask Iface
10.0.1.172 ether fa:fb:bb:ab:82:72 C eth0
root@k8s-ig-m6f5hd49-2ie613z6-ffcfq1uq:/# ip link | grep -C2 fa:fb:bb:ab:82:72
16: lxc493a9120593a@if15: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether fa:fb:bb:ab:82:72 brd ff:ff:ff:ff:ff:ff link-netnsid 6
root@k8s-ig-m6f5hd49-2ie613z6-ffcfq1uq:/# bash nsenter.sh 02f75de6e631 -n ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
15: eth0@if16: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 86:62:55:e0:8a:5e brd ff:ff:ff:ff:ff:ff link-netnsid 0
我们分别对 lxc493a9120593a 和容器内 eth0 抓包,lxc493a9120593a 网络设备抓包结果如下所示:
root@k8s-ig-m6f5hd49-2ie613z6-ffcfq1uq:/# tcpdump -n -e -i lxc493a9120593a
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on lxc493a9120593a, link-type EN10MB (Ethernet), capture size 262144 bytes
16:55:19.281201 fa:fb:bb:ab:82:72 > 86:62:55:e0:8a:5e, ethertype IPv4 (0x0800), length 74: 10.0.0.250.52724 > 10.0.1.60.80: Flags [S], seq 289137642, win 64860, options [mss 1410,sackOK,TS val 3072495928 ecr 0,nop,wscale 7], length 0
16:55:19.281236 86:62:55:e0:8a:5e > fa:fb:bb:ab:82:72, ethertype IPv4 (0x0800), length 74: 10.0.1.60.80 > 10.0.0.250.52724: Flags [S.], seq 3924940845, ack 289137643, win 64308, options [mss 1410,sackOK,TS val 2455727274 ecr 3072495928,nop,wscale 7], length 0
16:55:19.281544 fa:fb:bb:ab:82:72 > 86:62:55:e0:8a:5e, ethertype IPv4 (0x0800), length 66: 10.0.0.250.52724 > 10.0.1.60.80: Flags [.], ack 1, win 507, options [nop,nop,TS val 3072495928 ecr 2455727274], length 0
16:55:19.480019 fa:fb:bb:ab:82:72 > 86:62:55:e0:8a:5e, ethertype IPv4 (0x0800), length 143: 10.0.0.250.52724 > 10.0.1.60.80: Flags [P.], seq 1:78, ack 1, win 507, options [nop,nop,TS val 3072496127 ecr 2455727274], length 77: HTTP: HEAD / HTTP/1.1
16:55:19.480053 86:62:55:e0:8a:5e > fa:fb:bb:ab:82:72, ethertype IPv4 (0x0800), length 66: 10.0.1.60.80 > 10.0.0.250.52724: Flags [.], ack 78, win 502, options [nop,nop,TS val 2455727473 ecr 3072496127], length 0
16:55:19.480197 86:62:55:e0:8a:5e > fa:fb:bb:ab:82:72, ethertype IPv4 (0x0800), length 304: 10.0.1.60.80 > 10.0.0.250.52724: Flags [P.], seq 1:239, ack 78, win 502, options [nop,nop,TS val 2455727473 ecr 3072496127], length 238: HTTP: HTTP/1.1 200 OK
16:55:19.480311 fa:fb:bb:ab:82:72 > 86:62:55:e0:8a:5e, ethertype IPv4 (0x0800), length 66: 10.0.0.250.52724 > 10.0.1.60.80: Flags [.], ack 239, win 506, options [nop,nop,TS val 3072496127 ecr 2455727473], length 0
16:55:19.480658 fa:fb:bb:ab:82:72 > 86:62:55:e0:8a:5e, ethertype IPv4 (0x0800), length 66: 10.0.0.250.52724 > 10.0.1.60.80: Flags [F.], seq 78, ack 239, win 506, options [nop,nop,TS val 3072496127 ecr 2455727473], length 0
16:55:19.480734 86:62:55:e0:8a:5e > fa:fb:bb:ab:82:72, ethertype IPv4 (0x0800), length 66: 10.0.1.60.80 > 10.0.0.250.52724: Flags [F.], seq 239, ack 79, win 502, options [nop,nop,TS val 2455727474 ecr 3072496127], length 0
16:55:19.480879 fa:fb:bb:ab:82:72 > 86:62:55:e0:8a:5e, ethertype IPv4 (0x0800), length 66: 10.0.0.250.52724 > 10.0.1.60.80: Flags [.], ack 240, win 506, options [nop,nop,TS val 3072496128 ecr 2455727474], length 0
Pod2 容器中的网络设备 eth0 抓包结果如下所示:
root@k8s-ig-m6f5hd49-2ie613z6-ffcfq1uq:/# bash nsenter.sh 02f75de6e631 -n tcpdump -e -i eth0
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
16:53:22.180816 fa:fb:bb:ab:82:72 (oui Unknown) > 86:62:55:e0:8a:5e (oui Unknown), ethertype IPv4 (0x0800), length 74: 10.0.0.250.41026 > 10.0.1.60.http: Flags [S], seq 2364019483, win 64860, options [mss 1410,sackOK,TS val 3072378827 ecr 0,nop,wscale 7], length 0
16:53:22.180850 86:62:55:e0:8a:5e (oui Unknown) > fa:fb:bb:ab:82:72 (oui Unknown), ethertype IPv4 (0x0800), length 74: 10.0.1.60.http > 10.0.0.250.41026: Flags [S.], seq 1674396123, ack 2364019484, win 64308, options [mss 1410,sackOK,TS val 2455610174 ecr 3072378827,nop,wscale 7], length 0
16:53:22.181107 fa:fb:bb:ab:82:72 (oui Unknown) > 86:62:55:e0:8a:5e (oui Unknown), ethertype IPv4 (0x0800), length 66: 10.0.0.250.41026 > 10.0.1.60.http: Flags [.], ack 1, win 507, options [nop,nop,TS val 3072378828 ecr 2455610174], length 0
16:53:22.181162 fa:fb:bb:ab:82:72 (oui Unknown) > 86:62:55:e0:8a:5e (oui Unknown), ethertype IPv4 (0x0800), length 143: 10.0.0.250.41026 > 10.0.1.60.http: Flags [P.], seq 1:78, ack 1, win 507, options [nop,nop,TS val 3072378828 ecr 2455610174], length 77: HTTP: HEAD / HTTP/1.1
16:53:22.181169 86:62:55:e0:8a:5e (oui Unknown) > fa:fb:bb:ab:82:72 (oui Unknown), ethertype IPv4 (0x0800), length 66: 10.0.1.60.http > 10.0.0.250.41026: Flags [.], ack 78, win 502, options [nop,nop,TS val 2455610174 ecr 3072378828], length 0
16:53:22.181272 86:62:55:e0:8a:5e (oui Unknown) > fa:fb:bb:ab:82:72 (oui Unknown), ethertype IPv4 (0x0800), length 304: 10.0.1.60.http > 10.0.0.250.41026: Flags [P.], seq 1:239, ack 78, win 502, options [nop,nop,TS val 2455610174 ecr 3072378828], length 238: HTTP: HTTP/1.1 200 OK
16:53:22.181392 fa:fb:bb:ab:82:72 (oui Unknown) > 86:62:55:e0:8a:5e (oui Unknown), ethertype IPv4 (0x0800), length 66: 10.0.0.250.41026 > 10.0.1.60.http: Flags [.], ack 239, win 506, options [nop,nop,TS val 3072378828 ecr 2455610174], length 0
16:53:22.181500 fa:fb:bb:ab:82:72 (oui Unknown) > 86:62:55:e0:8a:5e (oui Unknown), ethertype IPv4 (0x0800), length 66: 10.0.0.250.41026 > 10.0.1.60.http: Flags [F.], seq 78, ack 239, win 506, options [nop,nop,TS val 3072378828 ecr 2455610174], length 0
16:53:22.181599 86:62:55:e0:8a:5e (oui Unknown) > fa:fb:bb:ab:82:72 (oui Unknown), ethertype IPv4 (0x0800), length 66: 10.0.1.60.http > 10.0.0.250.41026: Flags [F.], seq 239, ack 79, win 502, options [nop,nop,TS val 2455610175 ecr 3072378828], length 0
16:53:22.181732 fa:fb:bb:ab:82:72 (oui Unknown) > 86:62:55:e0:8a:5e (oui Unknown), ethertype IPv4 (0x0800), length 66: 10.0.0.250.41026 > 10.0.1.60.http: Flags [.], ack 240, win 506, options [nop,nop,TS val 3072378828 ecr 2455610175], length 0
我们发现网络数据包一直都是 Pod IP 通信,Pod IP 得以保留。
5.2 查看 BPF 程序
网络数据包从网卡到 Pod 虚拟网卡经历过哪些流程,请参考网络数据平面是 ipvs/iptables 或者 Cilium 网卡到 Pod 的数据路径。初识容器网络与eBPF。接着,查看在 Node2 宿主机上 dev eth0 查看 TC Hook 程序。
root@k8s-ig-m6f5hd49-2ie613z6-ffcfq1uq:/# tc filter show dev eth0 ingress
filter protocol all pref 1 bpf chain 0
filter protocol all pref 1 bpf chain 0 handle 0x1 cil_from_netdev-eth0 direct-action not_in_hw id 487 tag ced9b57550cd8ef8 jited
5.3 理解 cil_from_netdev BPF 程序
上述程序中 BPF 会对进入 dev eth0 的网络数据包进行处理。from-netdev 作为 tc 的 ingress 过滤器 附加到由 Cilium 管理的一个或多个物理设备(例如eth0)上。只有在以下情况下才附加此程序:启用主机防火墙或者启用了 BPF NodePort。
__section("from-netdev")
int cil_from_netdev(struct __ctx_buff *ctx)
{
__u32 __maybe_unused vlan_id;
int ret;
#ifdef ENABLE_NODEPORT_Ak8sLERATION
#ifdef HAVE_ENCAP
__u32 flags = ctx_get_xfer(ctx, XFER_FLAGS);
struct trace_ctx trace = {
.reason = TRACE_REASON_UNKNOWN,
.monitor = TRACE_PAYLOAD_LEN,
};
if (flags & XFER_PKT_SNAT_DONE)
ctx_snat_done_set(ctx);
if (flags & XFER_PKT_ENCAP) {
edt_set_aggregate(ctx, 0);
ret = __encap_and_redirect_with_nodeid(ctx, ctx_get_xfer(ctx, XFER_ENCAP_NODEID),
ctx_get_xfer(ctx, XFER_ENCAP_SECLABEL),
ctx_get_xfer(ctx, XFER_ENCAP_DSTID),
NOT_VTEP_DST, &trace);
if (IS_ERR(ret))
goto drop_err;
return ret;
}
#endif
#endif
/* Filter allowed vlan id's and pass them back to kernel.
*/
if (ctx->vlan_present) {
vlan_id = ctx->vlan_tci & 0xfff;
if (vlan_id) {
if (allow_vlan(ctx->ifindex, vlan_id))
return CTX_ACT_OK;
ret = DROP_VLAN_FILTERED;
goto drop_err;
}
}
return handle_netdev(ctx, false);
drop_err:
return send_drop_notify_error(ctx, 0, ret, CTX_ACT_DROP, METRIC_INGRESS);
}
__section_tail(CILIUM_MAP_CALLS, CILIUM_CALL_IPV4_FROM_LXC)
int tail_handle_ipv4(struct __ctx_buff *ctx)
{
int ret = __tail_handle_ipv4(ctx);
if (IS_ERR(ret))
return send_drop_notify_error(ctx, SECLABEL, ret,
CTX_ACT_DROP, METRIC_EGRESS);
return ret;
}
declare_tailcall_if(is_defined(ENABLE_PER_PACKET_LB), CILIUM_CALL_IPV4_FROM_LXC_CONT)
int tail_handle_ipv4_cont(struct __ctx_buff *ctx)
{
__u32 dst_id = 0;
__s8 ext_err = 0;
int ret = handle_ipv4_from_lxc(ctx, &dst_id, &ext_err);
if (IS_ERR(ret))
return send_drop_notify_ext(ctx, SECLABEL, dst_id, 0, ret, ext_err,
CTX_ACT_DROP, METRIC_EGRESS);
#ifdef ENABLE_CUSTOM_CALLS
if (!encode_custom_prog_meta(ctx, ret, dst_id)) {
tail_call_static(ctx, &CUSTOM_CALLS_MAP,
CUSTOM_CALLS_IDX_IPV4_EGRESS);
update_metrics(ctx_full_len(ctx), METRIC_EGRESS,
REASON_MISSED_CUSTOM_CALL);
}
#endif
return ret;
}
cil_from_netdev
ENABLE_XXX
ENABLE_NODEPORT_Ak8sLERATION
HAVE_ENCAP
HAVE_ENCAP
ctx_snat_done_set
__encap_and_redirect_with_nodeid
allow_vlan
handle_netdev
validate_ethertype
do_netdev
ENABLE_L7_LB
lxc_id = get_epid(ctx)
tail_call_dynamic
ENABLE_IPSEC
do_decrypt
CTX_ACT_OK
bpf_clear_meta
proto-ipv4
identity = resolve_srcid_ipv4
ctx_store_meta
ep_tail_call(CILIUM_CALL_IPV4_FROM_NETDEV / CILIUM_CALL_IPV4_FROM_LXC) // 尾调用
tail_handle_ipv4_from_netdev
tail_handle_ipv4 // CILIUM_CALL_IPV4_FROM_LXC
__tail_handle_ipv4
ENABLE_IPV4_FRAGMENTS
ENABLE_PER_PACKET_LB
ret = lb4_extract_tuple
svc = lb4_lookup_service
ret = lb4_local
lb4_ctx_store_state
invoke_tailcall_if(is_defined(ENABLE_PER_PACKET_LB),CILIUM_CALL_IPV4_CT_EGRESS, tail_ipv4_ct_egress) // 尾调用
CILIUM_CALL_IPV4_FROM_LXC_CONT // 尾调用
tail_handle_ipv4_cont
handle_ipv4_from_lxc
ENABLE_WIREGUARD
ENABLE_PER_PACKET_LB
HAVE_DIRECT_Ak8sSS_TO_MAP_VALUES
ENABLE_L7_LB
ENABLE_NODEPORT
...
verdict = policy_can_egress4
ep = lookup_ip4_endpoint
policy_clear_mark
ipv4_local_delivery
tail_call_static(ctx, &POLICY_CALL_MAP, HOST_EP_ID) // 尾调用
return CTX_ACT_OK
cil_from_netdev 调用栈简化上图流程:
1. 如果开启 HAVE_ENCAP
a. ctx_snat_done_set 确保 Cilium 在处理流量时已经正确地设置了 SNAT 上下文,从而保证流量的正确转发和路由。
b. __encap_and_redirect_with_nodeid 该函数的作用是根据指定的节点 ID 将流量数据包进行封装,并将其重定向到目标节点。
2. allow_vlan 过滤允许的 VLAN ID,并将其传递回内核。
3. handle_netdev 处理从宿主机到 Cilium 管理的网络数据包:
a. 解析这个包所属的 identity(Cilium 依赖 identity 做安全策略),并存储到包的结构体中。
b. 尾调用到 CILIUM_CALL_IPV4_FROM_NETDEV tail_handle_ipv4_from_netdev。
4. 继续尾调用 CILIUM_CALL_IPV4_FROM_LXC_CONT,进行以下主要流程:
a. 查找 dst_ip 对应的 endpoint(即 Pod2)。
b. 调用 ipv4_local_delivery 执行处理,这个函数会根据 endpoint id 直接尾调用到 endpoint (POD4) 的 BPF 程序。
步骤6 Pod2 eth0 网卡对端的 lxc493a9120593a BPF 程序处理

6.1 查看 BPF 程序
root@k8s-ig-m6f5hd49-2ie613z6-ffcfq1uq:/# tc filter show dev lxc493a9120593a egress
root@k8s-ig-m6f5hd49-2ie613z6-ffcfq1uq:/#
解答问题:没有相应的 BPF,怎么对容器的入向包做拦截和处理呢?对于网络数据包,直接从上文中的 eth0 BPF 程序尾调用 tail_call_static(ctx, &POLICY_CALL_MAP, HOST_EP_ID) ,不需要通过 tc 加载到 lxc 设备,极大缩短了物理网卡到容器的路径,提升了网络性能。
6.2 to-container BPF 程序分析
当 endpoint 路由被启用时,连接到容器的 lxc 设备。
__section("to-container")
int cil_to_container(struct __ctx_buff *ctx)
{
enum trace_point trace = TRACE_FROM_STACK;
__u32 magic, identity = 0;
__u16 proto;
int ret;
if (!validate_ethertype(ctx, &proto)) {
ret = DROP_UNSUPPORTED_L2;
goto out;
}
bpf_clear_meta(ctx);
magic = inherit_identity_from_host(ctx, &identity);
if (magic == MARK_MAGIC_PROXY_INGRESS || magic == MARK_MAGIC_PROXY_EGRESS)
trace = TRACE_FROM_PROXY;
#if defined(ENABLE_L7_LB)
else if (magic == MARK_MAGIC_PROXY_EGRESS_EPID) {
tail_call_dynamic(ctx, &POLICY_EGRESSCALL_MAP, identity);
return DROP_MISSED_TAIL_CALL;
}
#endif
send_trace_notify(ctx, trace, identity, 0, 0, ctx->ingress_ifindex,
TRACE_REASON_UNKNOWN, TRACE_PAYLOAD_LEN);
#if defined(ENABLE_HOST_FIREWALL) && !defined(ENABLE_ROUTING)
/* If the packet comes from the hostns and per-endpoint routes are enabled,
* jump to bpf_host to enforce egress host policies before anything else.
*
* We will jump back to bpf_lxc once host policies are enforced. Whenever
* we call inherit_identity_from_host, the packet mark is cleared. Thus,
* when we jump back, the packet mark will have been cleared and the
* identity won't match HOST_ID anymore.
*/
if (identity == HOST_ID) {
ctx_store_meta(ctx, CB_FROM_HOST, 1);
ctx_store_meta(ctx, CB_DST_ENDPOINT_ID, LXC_ID);
tail_call_static(ctx, &POLICY_CALL_MAP, HOST_EP_ID);
return DROP_MISSED_TAIL_CALL;
}
#endif /* ENABLE_HOST_FIREWALL && !ENABLE_ROUTING */
ctx_store_meta(ctx, CB_SRC_LABEL, identity);
switch (proto) {
#if defined(ENABLE_ARP_PASSTHROUGH) || defined(ENABLE_ARP_RESPONDER)
case bpf_htons(ETH_P_ARP):
ret = CTX_ACT_OK;
break;
#endif
#ifdef ENABLE_IPV6
case bpf_htons(ETH_P_IPV6):
ep_tail_call(ctx, CILIUM_CALL_IPV6_CT_INGRESS);
ret = DROP_MISSED_TAIL_CALL;
break;
#endif /* ENABLE_IPV6 */
#ifdef ENABLE_IPV4
case bpf_htons(ETH_P_IP):
ep_tail_call(ctx, CILIUM_CALL_IPV4_CT_INGRESS);
ret = DROP_MISSED_TAIL_CALL;
break;
#endif /* ENABLE_IPV4 */
default:
ret = DROP_UNKNOWN_L3;
break;
}
out:
if (IS_ERR(ret))
return send_drop_notify(ctx, identity, SECLABEL, LXC_ID,
ret, CTX_ACT_DROP, METRIC_INGRESS);
return ret;
}
cil_to_container
validate_ethertype
bpf_clear_meta
inherit_identity_from_host
ep_tail_call(ctx, CILIUM_CALL_IPV4_CT_INGRESS)
__section_tail(CILIUM_MAP_POLICY, TEMPLATE_LXC_ID)
handle_policy
validate_ethertype
invoke_tailcall_if(__and(is_defined(ENABLE_IPV4), is_defined(ENABLE_IPV6)),
CILIUM_CALL_IPV4_CT_INGRESS_POLICY_ONLY, tail_ipv4_ct_ingress_policy_only)
policy_can_ak8sss_ingress
__policy_can_ak8sss
id/proto/port (L3/L4)
ANY/proto/port (L4-only)
id/proto/ANY (L3-proto)
ANY/proto/ANY (Proto-only)
id/ANY/ANY (L3-only)
ANY/ANY/ANY (All)
return CTX_ACT_OK
return CTX_ACT_OK
to-container 调用栈简化上图流程:
- inherit_identity_from_host 从元数据中获取 src identity 信息。
- 尾调用 ep_tail_call(ctx, CILIUM_CALL_IPV4_CT_INGRESS),执行容器入向(ingress)安全策略检查。
步骤7 Pod2 eth0 网络数据包处理
 网络数据包到达容器的虚拟网卡,接下来就会被更上层处理。
网络数据包到达容器的虚拟网卡,接下来就会被更上层处理。
总结
步骤-请求与响应数据包路径流程
Request/Reponse Traffic path of Pod-to-ServiceIP 数据路径全景图

Cilium 是一个用于容器网络加速的开源项目,它提供高性能、安全性和可观察性的容器网络解决方案。总的来说,Cilium 是一个强大的容器网络加速工具,通过利用 eBPF 技术提供高性能、安全性和可观察性。它为容器网络提供了一个可扩展、灵活且易于管理的解决方案,适用于各种容器环境和工作负载。
- 高性能:Cilium 使用 Linux 内核功能如 eBPF 来实现数据包过滤和转发,以提供卓越的网络性能。它支持透明的负载均衡、快速的请求转发和响应处理,从而提高容器网络的吞吐量和响应性能。
- 安全性:Cilium 充分利用了 eBPF 技术的安全特性,可实现高度可扩展且具有细粒度的网络安全策略。它提供了基于标签的访问控制列表(ACL)和网络策略,用于保护容器之间的通信,并允许定义细粒度的网络过滤规则。此外,Cilium 可与基于身份验证和授权的系统(如 Kubernetes)集成,以实现更强大的网络安全性。
- 可观察性:Cilium 提供了强大的监控和可观察性功能,使用户能够深入了解容器网络的行为和性能。它可以生成详细的网络流量日志,允许用户对流量进行分析和故障排除。另外,Cilium 还集成了 Prometheus 和 Grafana,以便用户可以轻松地收集和可视化网络指标数据。
- 灵活性:Cilium 可与各种容器和编排平台集成,包括 Kubernetes、Docker 和纯裸机环境。它能够适应不同的网络拓扑和部署环境,并提供了丰富的配置选项,以满足各种需求。
附录
Cilium Agent 节点 Node 配置
- KubeProxyReplacement:Cilium将尽力替代Kube-Proxy,并尝试实现服务负载均衡和网络代理功能。
- Disabled:禁用模式,不使用 Cilium eBPF kube-proxy replacement,保留传统的 kube-proxy 运行方式。
- Strict:严格模式,使用 Cilium eBPF kube-proxy replacement 完全替换 kube-proxy 的运行方式。
- Partial:部分模式,同时使用 kube-proxy 和 Cilium eBPF kube-proxy replacement,用户需要手动指定需要替换的功能。
- Probe:自动探测是否启动 Cilium 替换 kube-proxy。
- KVStore:通过与 KVStore 进行交互,Cilium 可以读取和写入网络安全和网络配置相关的数据,从而实现更高效的网络管理和更强大的安全功能。
- Cilium Host firewall:用于保护和控制主机上的网络流量,并基于Cilium的网络策略来过滤和管理流入和流出主机的数据包。
- CNI Chaining:允许Cilium与其他容器网络接口(Container Network Interface)插件进行协同工作,以支持网络功能的链式连接和集成。
- NodeMonitor:通过监控集群中的节点和它们的状态,用于检测节点的上线和下线,并相应地调整网络拓扑和负载均衡。
- IPAM:负责为Cilium网络中的容器分配和管理IP地址,确保每个容器都有唯一的IP地址,并提供与主机网络的连接。
- IPv6 BIG TCP:支持IPv6网络中的大连接TCP流量,通过对TCP流量进行片段重排和负载均衡,提高网络性能和可靠性。
- BandwidthManager:用于在Cilium网络中实现带宽控制和限制,以确保每个容器或服务所使用的带宽不超过其指定的限制。
- Host Routing:通过在主机上配置路由表,将特定的流量路由到 Cilium 代理,以实现服务发现和网络转发。
- Legacy 模式:部分网络数据包依然使用主机路由,依赖了iptables 等 Netfilter。
- BPF模式:在BPF模式下,Cilium代理会使用eBPF程序来拦截和重新处理主机相关的IP流量。eBPF程序会对流量进行检查和转发,而不需要创建额外的网络接口,这种模式下,Cilium使用的是Linux内核中的BPF功能来实现路由和过滤。要求:内核 >= 5.10、直接路由配置或隧道、基于 eBPF 的 kube-proxy 替换、基于 eBPF 的 masquerading 等。
- Masquerading:用于将出站流量的源IP地址伪装为主机的IP地址,以实现网络地址转换(NAT)功能。
- Global Identity Range:定义了Cilium网络中可用的全局身份范围,确保分配给每个容器和服务的身份和标识是唯一和全局唯一的。
- Hubble:提供了网络观测和监控的解决方案,可以捕获、分析和可视化Cilium网络中的流量和性能数据。
- Encryption:针对Cilium通信提供加密功能,以保护网络通信的机密性和安全性。可以使用传输层安全协议(TLS)实现加密。
Cilium-Config ConfigMap 配置
- agent-not-ready-taint-key: Cilium代理标记节点为不可用的键。
- arping-refresh-period: ARP刷新周期。
- auto-direct-node-routes: 是否自动将节点路由直接发送到它们的目标。
- bpf-lb-external-clusterip: 是否启用使用外部网络负载均衡器的ClusterIP。
- bpf-lb-map-max: BPF负载均衡器映射的最大数量。
- bpf-lb-sock: 是否启用 BPF 负载均衡器套接字。
- bpf-map-dynamic-size-ratio: BPF 映射的动态分配比率。
- bpf-policy-map-max: BPF策略映射的最大数量。
- bpf-root: BPF根路径。
- cgroup-root: Cilium使用的Cgroup根路径。
- cilium-endpoint-gc-interval: 清理未启动的Cilium终端的间隔。
- cluster-id: 集群ID。
- cluster-name: 集群名称。
- cluster-pool-ipv4-cidr: IPv4集群CIDR。
- cluster-pool-ipv4-mask-size: IPv4集群掩码大小。
- cni-uninstall: 是否卸载CNI配置。
- custom-cni-conf: 是否使用自定义CNI配置。
- debug: 是否启用调试模式。
- debug-verbose: 调试模式的详细级别。
- disable-cnp-status-updates: 是否禁用CNP状态更新。
- disable-endpoint-crd: 是否禁用终端自定义资源定义。
- enable-auto-protect-node-port-range: 是否启用自动保护节点端口范围。
- enable-bgp-control-plane: 是否启用BGP控制平面。
- enable-bpf-clock-probe: 是否启用BPF时钟探针。
- enable-endpoint-health-checking: 是否启用终端健康检查。
- enable-health-check-nodeport: 是否启用健康检查的NodePort。
- enable-health-checking: 是否启用健康检查。
- enable-hubble: 是否启用Hubble。
- enable-ipv4: 是否启用IPv4。
- enable-ipv4-masquerade: 是否启用IPv4伪装。
- enable-ipv6: 是否启用IPv6。
- enable-ipv6-big-tcp: 是否启用IPv6的Big TCP。
- enable-ipv6-masquerade: 是否启用IPv6伪装。
- enable-k8s-terminating-endpoint: 是否启用Kubernetes终端。
- enable-l2-neigh-discovery: 是否启用L2邻居发现。
- enable-l7-proxy: 是否启用L7代理。
- enable-local-redirect-policy: 是否启用本地重定向策略。
- enable-policy: 是否启用策略,默认为"default"。
- enable-remote-node-identity: 是否启用远程节点标识。
- enable-sctp: 是否启用SCTP协议。
- enable-svc-source-range-check: 是否启用服务源范围检查。
- enable-vtep: 是否启用VTEP(VXLAN隧道封装协议)。
- enable-well-known-identities: 是否启用众所周知的标识。
- enable-xt-socket-fallback: 是否启用XT套接字回退。
- hubble-disable-tls: 是否禁用Hubble的TLS。
- hubble-listen-address: Hubble监听地址。
- hubble-socket-path: Hubble套接字路径。
- hubble-tls-cert-file: Hubble的TLS证书文件路径。
- hubble-tls-client-ca-files: Hubble的TLS客户端CA文件路径。
- hubble-tls-key-file: Hubble的TLS密钥文件路径。
- identity-allocation-mode: 用于分配标识的模式。
- identity-gc-interval: 清理未使用的标识的间隔。
- identity-heartbeat-timeout: 标识心跳超时时间。
- install-no-conntrack-iptables-rules: 是否跳过安装无连接跟踪的iptables规则。
- ipam: IP地址管理模式。
- kube-proxy-replacement: Kubernetes代理替换模式。
- kube-proxy-replacement-healthz-bind-address: 用于健康检查绑定的地址。
- monitor-aggregation: 监控聚合级别。
- monitor-aggregation-flags: 监控聚合标志。
- monitor-aggregation-interval: 监控聚合间隔。
- node-port-bind-protection: 是否启用节点端口绑定保护。
- nodes-gc-interval: 清理未连接的节点的间隔。
- operator-api-serve-addr: Operator API的服务地址。
- preallocate-bpf-maps: 是否预分配BPF映射。
- procfs: Proc文件系统的路径。
- remove-cilium-node-taints: 是否移除Cilium节点的污点。
- set-cilium-is-up-condition: 是否设置Cilium节点状态为启动状态。
- sidecar-istio-proxy-image: 用于Istio代理的Cilium镜像。
- skip-cnp-status-startup-clean: 是否跳过CNP启动时的清理。
- synchronize-k8s-nodes: 是否同步Kubernetes节点。
- tofqdns-dns-reject-response-code: 拒绝DNS请求的响应码。
- tofqdns-enable-dns-compression: 是否启用TOFQDNS的DNS压缩。
- tofqdns-endpoint-max-ip-per-hostname: 每个主机名的最大IP数量。
- tofqdns-idle-connection-grace-period: 空闲连接的处理时间。
- tofqdns-max-deferred-connection-deletes: 最大延迟删除连接数。
- tofqdns-min-ttl: 最小TTL(Time To Live)。
- tofqdns-proxy-response-max-delay: 代理响应的最大延迟。
- tunnel: 使用的隧道类型。
- unmanaged-pod-watcher-interval: 未管理的Pod的观察间隔。
- vtep-cidr: VTEP的CIDR。
- vtep-endpoint: VTEP的终端。
- vtep-mac: VTEP的MAC地址。
- vtep-mask: VTEP的掩码。