1. 问题
有客户反馈使用 A100 卡跑训练时会出现 RuntimeError: CUDA error: out of memory 报错。使用 docker Pod 运行的方式下出现的概率很低,但是使用 Kubernetes Pod 会很大的概率出现上述报错现象,总之都会出现该报错。
具体报错信息如下所示:
Traceback (most recent call last):
File "tools/test.py", line 195, in <module>
main()
File "tools/test.py", line 182, in main
runner = Runner.from_cfg(cfg)
File "/tmp/algorithm/deps/mmengine/runner/runner.py", line 443, in from_cfg
runner = cls(
File "/tmp/algorithm/deps/mmengine/runner/runner.py", line 412, in __init__
self.model = self.wrap_model(
File "/tmp/algorithm/deps/mmengine/runner/runner.py", line 855, in wrap_model
model = model.to(get_device())
File "/tmp/algorithm/deps/mmengine/model/base_model/base_model.py", line 202, in to
return super().to(*args, **kwargs)
File "/opt/conda/envs/py38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 899, in to
return self._apply(convert)
File "/opt/conda/envs/py38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 570, in _apply
module._apply(fn)
File "/opt/conda/envs/py38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 570, in _apply
module._apply(fn)
File "/opt/conda/envs/py38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 570, in _apply
module._apply(fn)
[Previous line repeated 1 more time]
File "/opt/conda/envs/py38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 593, in _apply
param_applied = fn(param)
File "/opt/conda/envs/py38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 897, in convert
return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None, non_blocking)
RuntimeError: CUDA error: out of memory
2. 分析过程
客户训练镜像与机器基础信息:
- 内核:3.10.0-1062.9.1.el7.x86_64
- 宿主机:CentOS Linux release 7.3.1611 (Core) 与 cuda_11.8.r11.8/compiler.31833905_0
- 容器镜像:Ubuntu 20.04.6 LTS \n \l 与 cuda_11.3.r11.3/compiler.29920130_0
- k8s:1.20.8
- device-plugin:nvidia-k8s-device-plugin:1.11
- Driver Version: 535.129.03
- CUDA Version: 12.2
- PyTorch: 1.10.1+cu113
- CuDNN:8.2
- Python: 3.8.18 (default, Sep 11 2023, 13:40:15) [GCC 11.2.0]
- NVCC: Cuda compilation tools, release 11.3, V11.3.109
搜索引擎与 NVIDIA 官网给出的建议是升级 torch 版本(pytorch:2.4.1),升级版本后会打印出更详细的报错日志,但是因不可控因素任务镜像无法升级 torch 版本,所以需要协助客户分析出现这个报错的原因与解决该问题;
OutOfMemoryError: CUDA out of memory.
Tried to allocate 734.00 MiB (GPU 0; 7.79 GiB total capacity;
5.20 GiB already allocated; 139.94 MiB free;6.78 GiB reserved in total by PyTorch)
If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation.
See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF;
2.1. 排查思路
按照以下思路进行排查:
| 类别 | 排查项 | 排查方式 | 排查结果 |
|---|---|---|---|
| K8s & 容器资源限制 | CPU/Memory 限制 | 检查 Pod 和 Docker 的 resource limits | 存在内存限制,但 OOM 发生在 GPU 显存申请阶段,且主内存使用未达限值,排除主内存不足导致 OOM 的可能 |
| Docker & 容器运行时 | nvidia-container-runtime | 替换为原生版本、对比容器 inspect 信息、OCI 配置、nvidia-container-runtime 执行日志 | 自研 runtime 与原生版本在配置和行为上无明显差异,基本排除容器运行时实现问题 |
| GPU 插件与虚拟化 | gpu-manager、nvidia-device-plugin、共享模式 | 关闭 gpu-manager 组件、尝试直接挂载 GPU 设备(绕过 device plugin) | 关闭共享模式后问题曾短暂消失,后续复现,表明 GPU 虚拟化层可能存在资源隔离或上下文管理异常,存在干扰嫌疑 |
| CUDA 环境 | 宿主机 vs 容器内 CUDA 版本 | 宿主机 CUDA 12.2,容器内 CUDA 11.3 | 版本不一致,虽符合 NVIDIA 官方兼容性矩阵(驱动 ≥ 所需最低版本),但在复杂调度与多容器场景下存在潜在兼容风险,尤其影响 CUDA context 初始化行为 |
| NVIDIA 驱动 | 驱动版本(535.183.01 / 520 / 525) | 升级/降级驱动版本进行对比测试 | 高版本驱动(535.183.01)下 nvidia-smi 显示 GPU 初始化显存仅 4M(异常,正常应为数十 MB 起),表明设备初始化异常;降级至 520 导致业务失败,525 仍存在问题,驱动与旧内核协同存在隐患 |
| 存储 & 网络 | PFS 存储、CNI 网络 | 将 PFS 数据迁移至本地磁盘;将 Pod 网络模式由 CNI 切换为 hostNetwork | 问题依旧存在,排除 PFS 网络延迟或文件锁竞争导致阻塞的可能性 |
| PyTorch 框架行为 | torch 1.10.1、CUDA 初始化逻辑 | 在代码中增加 try-catch、手动调用 torch.cuda.init()、循环查询显存状态 | nvidia-ml-py(通过 pynvml)可正常读取显存信息,但 torch.cuda 申请显存失败,表明问题发生在 PyTorch CUDA 上下文初始化层,而非底层驱动或硬件 |
| 业务代码结构 | 业务代码是否存在缺陷(但在其他厂商环境运行正常) | 对比不同厂商环境的基础软硬件配置差异 | 代码本身在其他环境运行稳定,初步排除逻辑 bug;问题更可能源于当前环境基础配置(如内核版本、驱动、GPU 虚拟化策略)未与其他厂商对齐,导致行为偏移 |
经过上述排查过程后,发现问题依然存在,但还是没有定位到原因与解决办法。
2.2. 核心突破
客户无意中提到同样的代码在另外一套环境基本不会出现 OOM,通过对比差异点,发现机器的内核版本不同,没有问题的内核版本是 4.18,现在有问题的机器内核是 3.10。
【突破点,可能与内核版本有关】查阅官网,内核与cuda版本兼容文档如下所示:
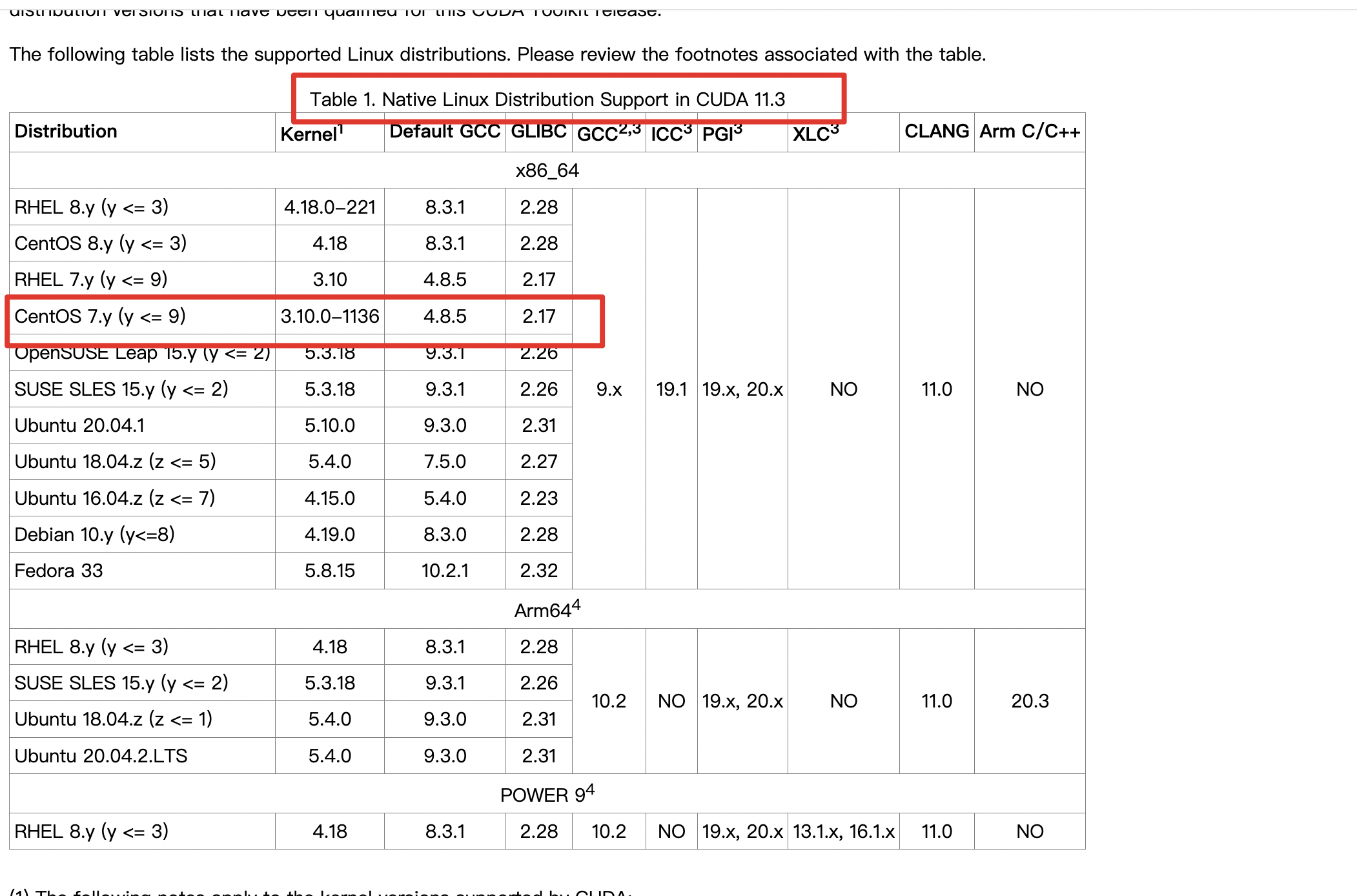
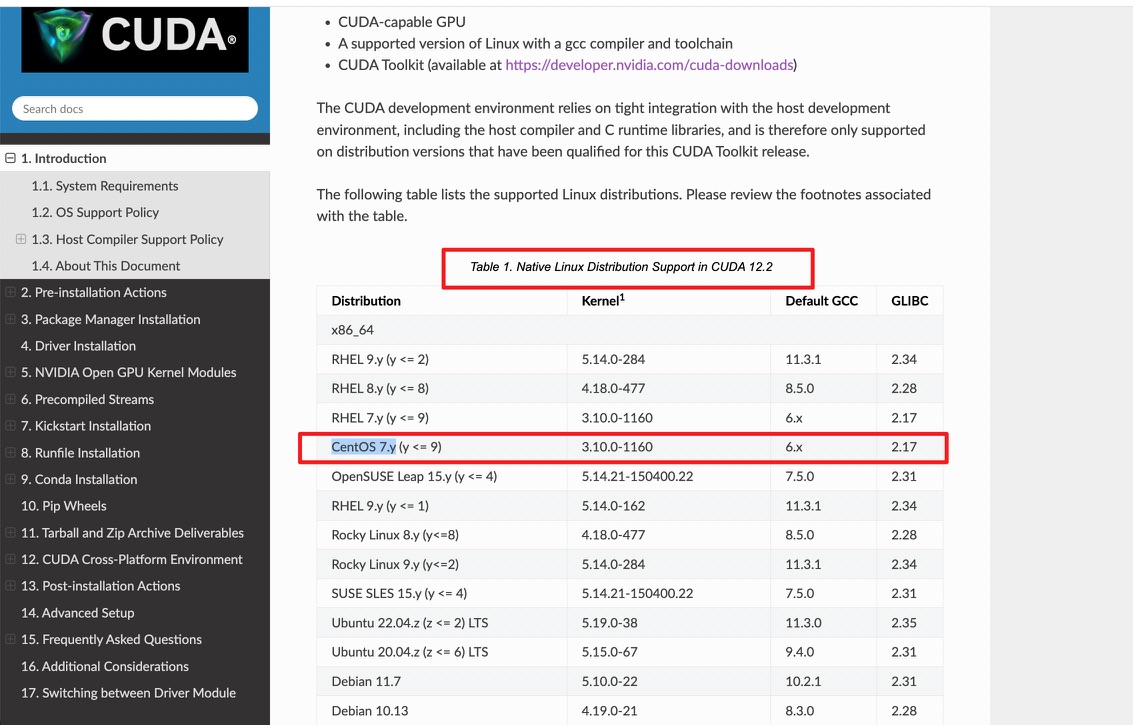
现在机器的内核版本不满足表格中的版本要求,我们尝试升级内核版本到 4.19,经过大量测试与验证发现问题得到解决;
【原因分析】 在某种场景下(业务 torch 版本 :1.10 cuda 版本: cuda_11.3.r11.3/compiler.29920130_0 操作系统:ubuntu20.04)在宿主机驱动版本: CUDA Driver 535.183.x ,cuda 版本:cuda_11.8.r11.8/compiler.31833905_0)由于内核版本偏低可能触发了bug,导致在k8s或者docker容器运行方式下出现该OOM问题。
3. 结论与思考
| 怀疑原因 | 支持证据 | 置信度 | 备注 |
|---|---|---|---|
| 旧内核(3.10)与新驱动不兼容导致 GPU 初始化异常(核心原因) | - 系统偶现内核态 hang 住现象 - nvidia-smi 显示 GPU 初始化后显存仅 4M(严重异常,正常应为数十 MB 起)- 升级内核过程中问题频率下降,初步验证相关性 | 🔴 高 | 内核 3.10 发布于 2013 年,而当前使用驱动版本为 535.183.01(2023+),存在显著版本错配,可能导致 GPU 内存映射、DMA 或设备初始化异常 |
| PyTorch 1.10.1 在低内核 + 虚拟化环境下的 CUDA 初始化缺陷 | - 在 tools/test.py 中手动调用 torch.cuda.init() 有时成功、有时失败- 增加 try-catch 后可捕获 OOM,但底层 pynvml 显示显存充足- 问题在非虚拟化环境或高内核版本下较少出现 | 🟡 中高 | PyTorch 1.10.1 对复杂环境(老旧内核 + GPU 虚拟化)的容错能力较弱,CUDA context 初始化可能因底层状态不一致而失败 |
| 前置脚本污染 CUDA 上下文 + GPU 共享模式干扰 | - bin2pcd.py 执行后立即运行 tools/test.py 时更容易触发 OOM- 关闭 gpu-manager(即禁用 GPU 共享模式)后问题曾短暂消失- 拆分两个脚本执行环境后问题减少 | 🟡 中 | 即使 bin2pcd.py 未显式使用 GPU,若其导入了 torch 等库,可能触发隐式 CUDA context 初始化且未正确释放,导致后续进程无法正常申请资源;共享模式加剧了上下文管理复杂性 |
本次排查遵循“由外到内、逐层剥离、控制变量、交叉验证”的系统性方法,全面覆盖了从应用层到内核底层的全技术栈,体现了典型的复杂环境故障定位思路。
- 分层排查,边界清晰:将整个技术栈划分为多个独立层级(K8s 资源、容器运行时、GPU插件、CUDA环境、驱动、存储、网络等),逐层验证,确保每一层的问题被独立评估,避免干扰判断。这种“模块化隔离”策略有效防止了误判和路径偏移。
- 控制变量,精准对比:在关键环节(如容器运行时替换、数据路径迁移、GPU挂载方式切换)中,通过环境对调、配置替换、组件回退等方式实现变量控制。例如:
- 替换自研与原生 nvidia-container-runtime 对比行为差异;
- 将PFS数据迁移至本地盘以排除网络存储影响;
- 交换机器验证是否为硬件个体问题;这些操作体现了严谨的实验设计思维。
- 现象驱动,逆向溯源:面对“偶发性OOM”这一非确定性问题,通过增加日志埋点、try-catch捕获、显存轮询、自助初始化CUDA等手段,主动触发并捕获异常现场,将“黑盒问题”逐步转化为可观测行为,极大提升了问题可分析性。
- 兼容性与版本敏感性验证:针对异构环境(宿主机CUDA 12.2 / 容器内11.3、驱动535+ / 内核3.10),评估版本兼容性风险,并通过升级/降级驱动、尝试不同内核版本等方式验证假设,体现出对软硬件协同依赖的深刻理解。
- 对虚拟化中间层保持警惕:gpu-manager 和共享模式可能引入的副作用,通过关闭组件、直连设备等方式绕过抽象层,验证了“中间件干扰”的可能性。这是在云原生AI场景中尤为关键的排查视角。
- 具备底层系统视野:当问题指向内核hang、nvidia-smi初始化异常等低层现象时,跳出框架层,深入到内核版本、DMA、设备初始化流程等操作系统层面进行推断,展现了对GPU资源管理全链路的理解。
- 接受不确定性,保留回溯路径:面对“可复现→消失”的波动现象,未强行归因,而是通过多轮交叉验证积累证据链,保留多种可能性,体现了工程排查中的理性与克制。
现象:GPU显存充足(nvidia-smi 显示有空闲),但 torch.cuda 申请显存失败(OOM);问题偶发、替换机器、迁移数据、更换 runtime、升级/降级驱动、切换网络模式等操作均不能彻底解决
核心难点:GPU显存充足但PyTorch无法申请显存(OOM),且具有概率性、偶发性、不可稳定复现的特点;系统层面显存可用,但 PyTorch CUDA 上下文申请失败,说明问题可能发生在 CUDA 上下文管理、内存管理机制、或资源未释放导致的隐式占用;
总结:本次OOM问题表现为GPU显存充足但PyTorch无法申请,具有概率性、偶发性特征。排查覆盖资源限制、容器运行时、GPU插件、CUDA环境、驱动、内核、存储网络等多个层面,排除了主存限制、存储I/O、网络及runtime实现问题。关键线索包括:nvidia-smi显示初始化显存异常(仅4M)、旧内核(3.10)与新驱动(535+)兼容性存疑、GPU共享模式干扰、前后脚本连续执行可能导致CUDA上下文污染。综合判断,问题核心并非真实显存不足,而是CUDA上下文初始化失败或状态异常,由前置脚本隐式加载CUDA、GPU虚拟化干扰、旧内核兼容性不足等多重因素叠加导致,属于“伪OOM”。