基础概念
【分布式推理与服务】(Distributed Inference and Serving)是指在多个机器或设备之间部署和管理机器学习模型,以高效地处理推理请求并满足大规模服务需求。
【推理】是指使用训练好的机器学习模型,对新的、未见过的数据进行预测或决策的过程。 推理可能需要大量计算资源,尤其是在处理大型模型时,因此通过分布式方式将推理任务分摊到多个机器上,可以显著提升性能并减少延迟。
服务(Serving)模型服务是指将模型部署到生产环境中,通过 API 或其他接口提供预测服务的过程。 模型可以部署在单台机器上,也可以分布在多个节点中,以应对高并发请求或降低响应时间。
本文记录在两台 L20 机器,每台机器 4 块 L20 显卡(46G)的环境下,使用 vLLM 部署 Qwen2.5-32B-Instruct-GPTQ-Int4 模型并提供多节点多卡推理服务的过程。
环境信息
- OS:CentOS Linux release 7.9.2009 (Core)
- Kernel:3.10.0-1160.83.1.el7.x86_64
- 驱动: NVIDIA-SMI 535.183.06 Driver Version: 535.183.06 CUDA Version: 12.2
GPU:NVIDIA L20
(base) [root@instance-crwsvl7m-1 multiple-nodes-vllm]# nvidia-smi -L
GPU 0: NVIDIA L20 (UUID: GPU-126fe4b0-c735-771d-680c-0d6826c03129)
GPU 1: NVIDIA L20 (UUID: GPU-11153395-f39b-6d51-1a91-ee33fb04bac1)
GPU 2: NVIDIA L20 (UUID: GPU-992e9b13-7cf8-e571-6826-1c95aa375a53)
GPU 3: NVIDIA L20 (UUID: GPU-70c1a850-a443-6619-7b42-ba59aec4d07a)
- 模型:Qwen2.5-32B-Instruct-GPTQ-Int4
- vLLM
- Docker:20.10.5
- nvidia-container-runtime:1.0.2-dev
- 测试镜像:vllm/vllm-openai:v0.6.4.post1
- 2 台 L20 机器:
# head 节点
192.168.30.4
# worker 工作节点
192.168.30.5
### 配置与模型根目录 /root/chentanjun/multiple-nodes-vllm ###
注意:需要保障模型在每个机器上的路径一致
参数说明
- IP_OF_HEAD_NODE:Ray Head Node 的 IP 地址。测试值:vllm-head-service.vllm.svc.cluster.local
- NCCL_SOCKET_IFNAME:NCCL 通信的以太网接口名称。测试值:eth0
- NCCL_DEBUG:NCCL 的调试信息级别。测试值:TRACE
- NCCL_IB_DISABLE:禁用 InfiniBand。测试值:1
- CUDA_VISIBLE_DEVICES:可用的 GPU 设备列表。
- MODEL_PATH:模型文件的存储路径。
- SERVED_MODEL_NAME:服务化模型的名称。
- TENSOR_PARALLEL_SIZE:张量并行度大小。 测试值:4。
- PIPELINE_PARALLEL_SIZE 管道并行度大小。测试值:2。
- MAX_MODEL_LEN:模型支持的最大输入长度。 测试值:4096。
- QUANTIZATION:模型量化方式。 测试值:gptq_marlin。
- GPU_MEMORY_UTILIZATION:GPU 内存的最大利用率。测试值:0.90。
- PORT:服务监听的端口号。测试值:8009。
并行策略
张量并行(Tensor Parallelism, TP)
- 简介:模型的张量(如权重矩阵)被切分到多个 GPU 上,计算由这些 GPU 协同完成。
- 典型例子:GPT-3 和 GPT-4 的分布式推理使用 Megatron-LM 框架,依靠张量并行来分散矩阵乘法计算。
- 适用场景:模型权重矩阵较大(如多亿参数级别),单张 GPU 无法处理时。
- 优点:减少单 GPU 显存占用,提高计算效率。
- 缺点:GPU 通信频繁,可能成为性能瓶颈。
管道并行(Pipeline Parallelism, PP)
- 简介:将模型按层划分,每组层分配到不同的 GPU 上,输入数据以流水线方式依次经过这些 GPU 处理。
- 典型例子:BERT 或 GPT-3 推理中,使用 Hugging Face 的 DeepSpeed 或 FairScale 框架结合管道并行进行推理。
- 适用场景:模型规模超大(数百亿或更多参数),显存需求超过单 GPU 时。
- 优点:分摊显存需求,提高利用率。
- 缺点:存在流水线延迟,计算资源可能闲置。
数据并行(Data Parallelism, DP)
- 简介:将整个模型复制到多个 GPU 上,所有 GPU 同步计算不同的输入数据分片。
- 典型例子:ResNet 和 ViT 等模型在分布式推理或训练时广泛采用数据并行策略(如 PyTorch Distributed Data Parallel,DDP)。
- 适用场景:大批量推理任务,模型规模适中,显存足够容纳完整模型时。
- 优点:实现简单,通信开销小。
- 缺点:参数同步开销随 GPU 数量增加。
混合并行(Hybrid Parallelism)
- 简介:同时采用张量并行、管道并行和数据并行,结合其优势进行优化。
- 典型例子:GPT-3 训练使用 Megatron-LM 的混合并行技术,尤其是在多节点分布式系统中。
- 适用场景:超大规模模型(数百亿到数万亿参数),需要跨节点分布式推理或训练时。
- 优点:高效利用硬件资源,适应复杂任务。
- 缺点:实现复杂,需精细调优并行配置。
流式并行(Stream Parallelism)
- 简介:将任务划分为多个子任务并发执行,减少 GPU 空闲时间。
- 典型例子:NVIDIA TensorRT 在推理优化中,通过异步执行多个推理流实现流式并行。
- 适用场景:实时推理,任务间独立性较高时。
- 优点:减少延迟,提高 GPU 利用率。
- 缺点:对任务间的独立性要求较高。
特定硬件优化并行(Hardware-Specific Parallelism)
- 简介:针对硬件架构(如 NVIDIA Tensor Cores 或 Google TPU)设计计算优化策略。
- 典型例子:
- NVIDIA 的 Transformer Engine 针对 A100 和 H100 GPU 优化张量并行和低精度计算。
- TPU Pod 上使用的切片并行策略。
- 适用场景:有特定硬件支持的部署场景。
- 优点:能充分利用硬件特性,达到最佳性能。
- 缺点:硬件依赖性强,迁移性差。
异步并行(Asynchronous Parallelism)
- 简介:不同 GPU 处理不同任务,避免同步等待。
- 典型例子:在自定义推理服务中,结合异步任务调度框架(如 Ray Serve)实现分布式推理。
- 适用场景:并发推理场景,允许输入任务间异步执行。
- 优点:最大化吞吐量。
- 缺点:实现复杂,需要任务解耦。
总结与选择策略:
- 小模型且任务独立:选择数据并行。
- 大模型且显存不足:选择张量并行、管道并行或混合并行。
- 超大规模分布式系统:混合并行是首选。
- 实时性要求高:结合流式并行或异步并行优化延迟。
- 硬件优化场景:优先使用硬件特定并行策略。
验证过程
因为涉及到跨机通信,环境无 IB/RoCE RDMA 高性能网卡,所以使用以太网进行验证
1、搭建ray集群
run_cluster.sh 脚本如下所示:
#!/bin/bash
# Check for minimum number of required arguments
if [ $# -lt 4 ]; then
echo "Usage: $0 docker_image head_node_address --head|--worker path_to_hf_home [additional_args...]"
exit 1
fi
# Assign the first three arguments and shift them away
DOCKER_IMAGE="$1"
HEAD_NODE_ADDRESS="$2"
NODE_TYPE="$3" # Should be --head or --worker
PATH_TO_HF_HOME="$4"
shift 4
# Additional arguments are passed directly to the Docker command
ADDITIONAL_ARGS=("$@")
# Validate node type
if [ "${NODE_TYPE}" != "--head" ] && [ "${NODE_TYPE}" != "--worker" ]; then
echo "Error: Node type must be --head or --worker"
exit 1
fi
# Define a function to cleanup on EXIT signal
cleanup() {
docker stop node
docker rm node
}
trap cleanup EXIT
# Command setup for head or worker node
RAY_START_CMD="ray start --block"
if [ "${NODE_TYPE}" == "--head" ]; then
RAY_START_CMD+=" --head --port=6379 --dashboard-host=0.0.0.0"
else
RAY_START_CMD+=" --address=${HEAD_NODE_ADDRESS}:6379"
fi
# Run the docker command with the user specified parameters and additional arguments
docker run \
--entrypoint /bin/bash \
--privileged \
--network host \
--ipc host \
--name node \
--shm-size 10.24g \
--gpus all \
-v "${PATH_TO_HF_HOME}:/root/.cache/huggingface" \
"${ADDITIONAL_ARGS[@]}" \
"${DOCKER_IMAGE}" -c "${RAY_START_CMD}"
head 节点:
export IP_OF_HEAD_NODE=192.168.30.4
export MODEL_PATH=/root/chentanjun/multiple-nodes-vllm/models
nohup bash run_cluster.sh vllm/vllm-openai:v0.6.4.post1 $IP_OF_HEAD_NODE --head $MODEL_PATH -e NCCL_SOCKET_IFNAME=eth0 -e NCCL_DEBUG=TRACE -e NCCL_IB_DISABLE=1 > nohup.log 2>&1 &
worker 节点:
export IP_OF_HEAD_NODE=192.168.30.4
export MODEL_PATH=/root/chentanjun/multiple-nodes-vllm/models
nohup bash run_cluster.sh vllm/vllm-openai:v0.6.4.post1 $IP_OF_HEAD_NODE --worker $MODEL_PATH -e NCCL_SOCKET_IFNAME=eth0 -e NCCL_DEBUG=TRACE -e NCCL_IB_DISABLE=1 > nohup.log 2>&1 &
2、检查 ray 集群状态(随机找ray集群中的节点就行,执行命令 docker exec -it node bash):
root@instance-crwsvl7m-1:/vllm-workspace# ray status
======== Autoscaler status: 2025-01-18 04:26:08.652980 ========
Node status
---------------------------------------------------------------
Active:
1 node_5fabbf7fa271a449afd0784e469b505b46eb1e8987e1c4e4f9fed6bc
1 node_2c42a16ded3d6043b5cb685362edf41193f2895654e44fa1f44153a3
Pending:
(no pending nodes)
Recent failures:
(no failures)
Resources
---------------------------------------------------------------
Usage:
0.0/224.0 CPU
0.0/8.0 GPU
0B/646.08GiB memory
0B/280.88GiB object_store_memory
Demands:
(no resource demands)
3、启动 vLLM 服务
在节点 head 的容器中启动服务,如下所示:
vllm serve /root/.cache/huggingface/Qwen2.5-32B-Instruct-GPTQ-Int4 \
--served-model-name Qwen2.5-32B-Instruct-GPTQ-Int4 \
--tensor-parallel-size 4 \
--pipeline-parallel-size 2 \
--max-model-len 4096 \
--quantization gptq_marlin \
--gpu-memory-utilization 0.95 \
--trust-remote-code \
--port 8009
# 守护进程启动
nohup vllm serve /root/.cache/huggingface/Qwen2.5-32B-Instruct-GPTQ-Int4 \
--served-model-name Qwen2.5-32B-Instruct-GPTQ-Int4 \
--tensor-parallel-size 4 \
--pipeline-parallel-size 2 \
--max-model-len 4096 \
--quantization gptq_marlin \
--gpu-memory-utilization 0.95 \
--trust-remote-code \
--port 8009 > vllm_serve.log 2>&1 &
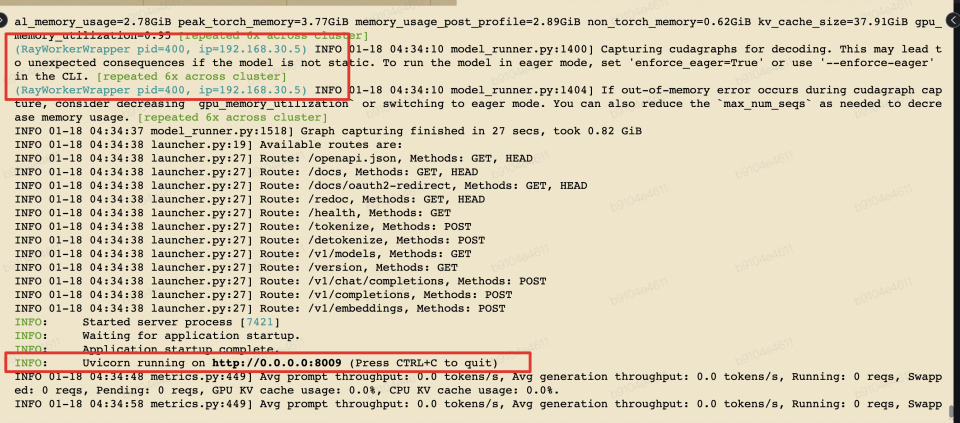
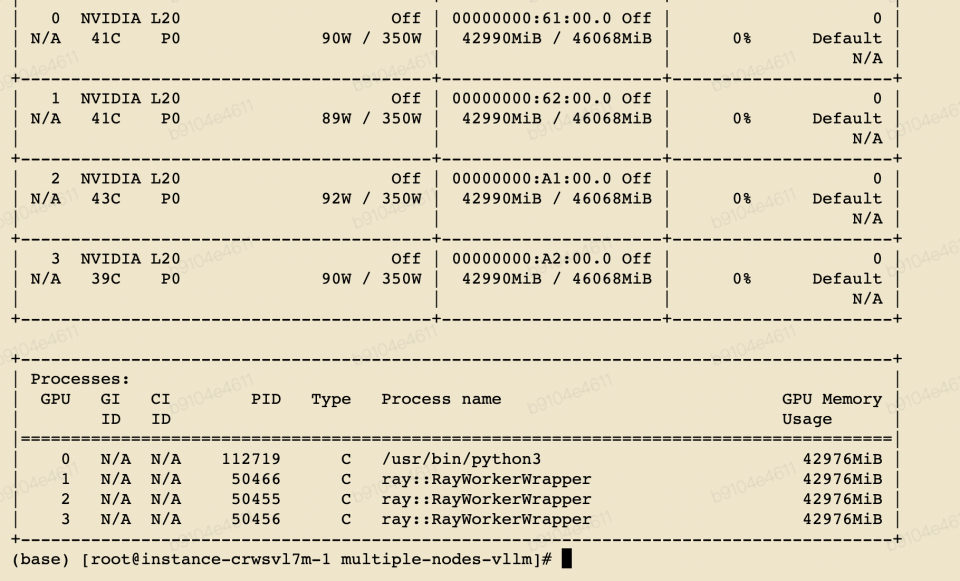
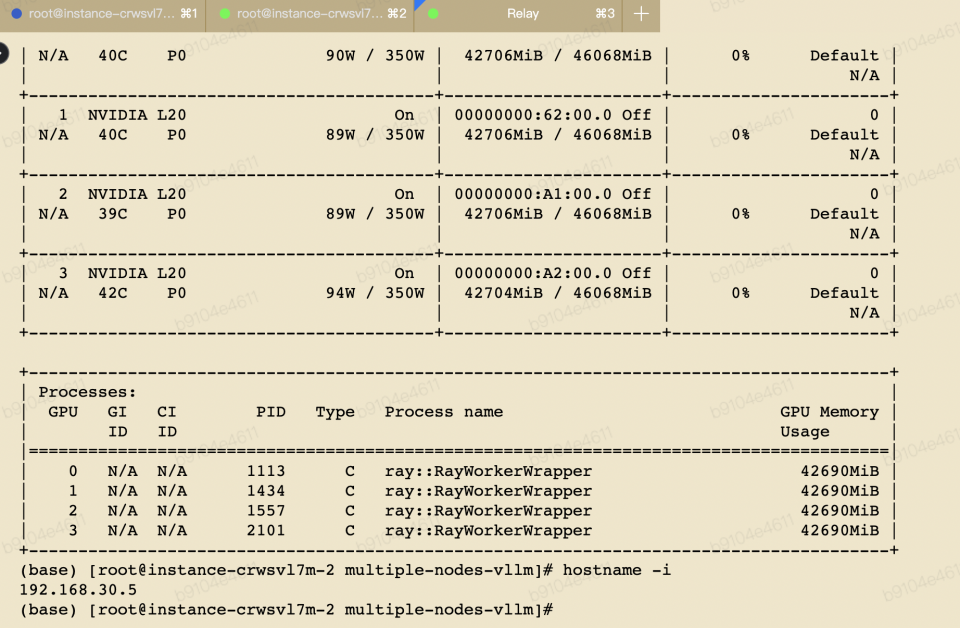
4、请求 openapi 测试
export IP_OF_HEAD_NODE=192.168.30.4
# Qwen2.5-32B-Instruct-GPTQ-Int4
# 非流式
curl --request POST \
-H "Content-Type: application/json" \
--url http://$IP_OF_HEAD_NODE:8009/v1/chat/completions \
--data '{"messages":[{"role":"user","content":"给我推荐中国适合旅游的方"}],"stream":false,"model":"Qwen2.5-32B-Instruct-GPTQ-Int4"}'
# 流式
curl --request POST \
-H "Content-Type: application/json" \
--url http://$IP_OF_HEAD_NODE:8009/v1/chat/completions \
--data '{"messages":[{"role":"user","content":"给我推荐中国适合旅游的地方"}],"stream":true,"model":"Qwen2.5-32B-Instruct-GPTQ-Int4"}'
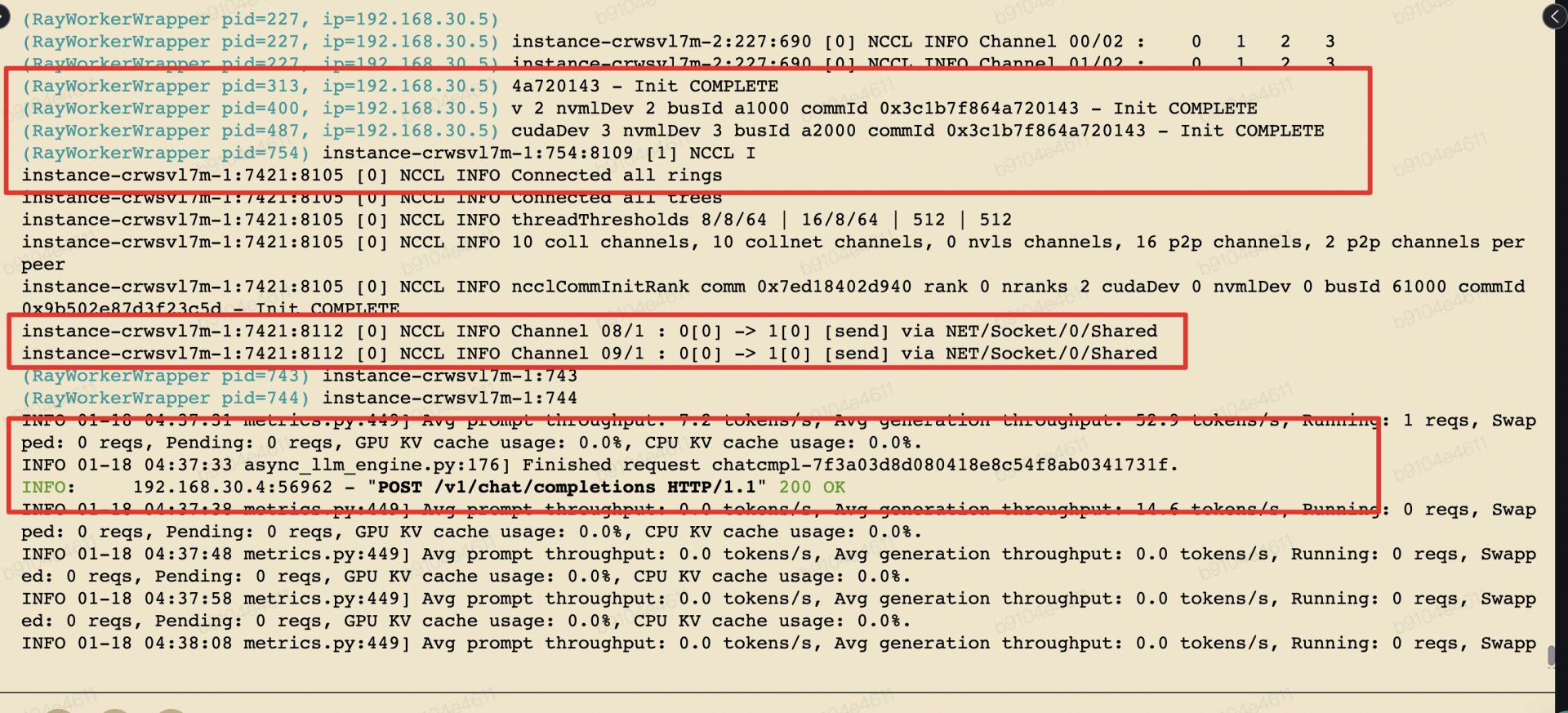
测试结果:

附录
校验模型hash值工具如下所示:
sha256sum *.safetensors > sum.txt
root@instance-o6t26vv4:~/chentanjun/Qwen2.5-32B-Instruct-GPTQ-Int4# cat sum.txt
942d93a82fb6d0cb27c940329db971c1e55da78aed959b7a9ac23944363e8f47 model-00001-of-00005.safetensors
19139f34508cb30b78868db0f19ed23dbc9f248f1c5688e29000ed19b29a7eef model-00002-of-00005.safetensors
d0f829efe1693dddaa4c6e42e867603f19d9cc71806df6e12b56cc3567927169 model-00003-of-00005.safetensors
3a5a428f449bc9eaf210f8c250bc48f3edeae027c4ef8ae48dd4f80e744dd19e model-00004-of-00005.safetensors
c22a1d1079136e40e1d445dda1de9e3fe5bd5d3b08357c2eb052c5b71bf871fe model-00005-of-00005.safetensors