基础知识

查看 deepseek-ai 开源官网,DeepSeek 有以下系列:
- DeepSeek-R1
- DeepSeek-V3 (DeepSeek-V3-Base)
- DeepSeek-VL
- DeepSeek-Coder
- DeepSeek-Math
- DeepSeek-LLM
- 蒸馏模型系列(Qwen、LLaMA等)
- ……

模型系列
| 模型名称 | 类型/架构 | 参数规模 | 核心能力 | 关键技术 |
|---|---|---|---|---|
| DeepSeek-R1 | 混合专家(MoE) | 总参数671B 激活参数37B/token 支持128K上下文 | • 对标GPT-4o/Claude 3.5 Sonnet • 数学/编程任务领先 • 完整开源支持 | • 动态负载均衡 • 多词元预测(MTP) • FP8混合精度训练(成本$557万) |
| DeepSeek-V3 | 纯强化学习(RL) | 671B基础版 1.5B-70B蒸馏版 | • 无需SFT直接RL优化 • 数学/编程达OpenAI o1水平 | • 群组相对策略优化(GRPO) • 双奖励机制(准确度+格式) |
| Janus-Pro-7B | 多模态统一架构 | 7B参数 单卡部署(≥24GB) | • 视觉问答超GPT-4V • 文生图质量优于DALL·E 3 • 逆向图像生成代码 | • 自回归多模态框架 • 企业级隐私保障 • 本地部署方案 |
| DeepSeek-VL2 | MoE视觉架构 | 未披露 | • 梗图解析 • 多图生成故事 | • 视觉编码解耦设计 • 多模态任务冲突缓解 |
| DeepSeek-V2.5 | 融合对话与代码 | 未披露 | • 通用对话+代码生成 • 防御越狱攻击 | • 支持Function Calling • 多语言API接口 • FIM补全机制 |
| 蒸馏模型系列 | 轻量级推理模型 | 1.5B/7B/14B/32B/70B | • 继承R1推理能力 • 部分版本超GPT-4o • 开源商用 | • 知识蒸馏技术 • 边缘设备适配 |
DeepSeek的模型集合覆盖语言、推理、多模态三大领域,核心优势在于高性能、低成本、全开源,其技术突破包括:
- 训练效率 FP8混合精度 + DualPipe流水线并行 + 千卡集群线性加速效率92%
- 推理优化 RL直接策略优化 + 多词元预测加速解码
- 多模态融合 自回归框架统一模态交互 + 视觉-语言耦合参数共享
DeepSeek-R1
入门介绍
DeepSeek 推出了推理模型 DeepSeek-R1-Zero 和 DeepSeek-R1:
- DeepSeek-R1-Zero:该模型通过大规模强化学习(RL)训练而成,无需监督微调(SFT)作为前置步骤,在推理任务中展现了卓越的性能。通过RL训练,DeepSeek-R1-Zero 自然涌现出许多强大且有趣的推理行为。然而,它也面临一些挑战,例如无限重复、可读性差、语言混杂等问题。
- DeepSeek-R1:为了解决这些问题并进一步提升推理性能,在RL训练前引入了冷启动数据。DeepSeek-R1 在数学、代码和通用推理任务中达到了与 OpenAI-o1 相当的水平。
开源贡献:
- 开源了 DeepSeek-R1-Zero 和 DeepSeek-R1 的完整模型权重。
- 基于 Llama 和 Qwen 架构,还提供了6个从 DeepSeek-R1 蒸馏的轻量级模型。
- 性能突破:其中,DeepSeek-R1-Distill-Qwen-32B 在多项基准测试中超越了 OpenAI-o1-mini,为稠密模型(Dense Model)树立了新的性能标杆。
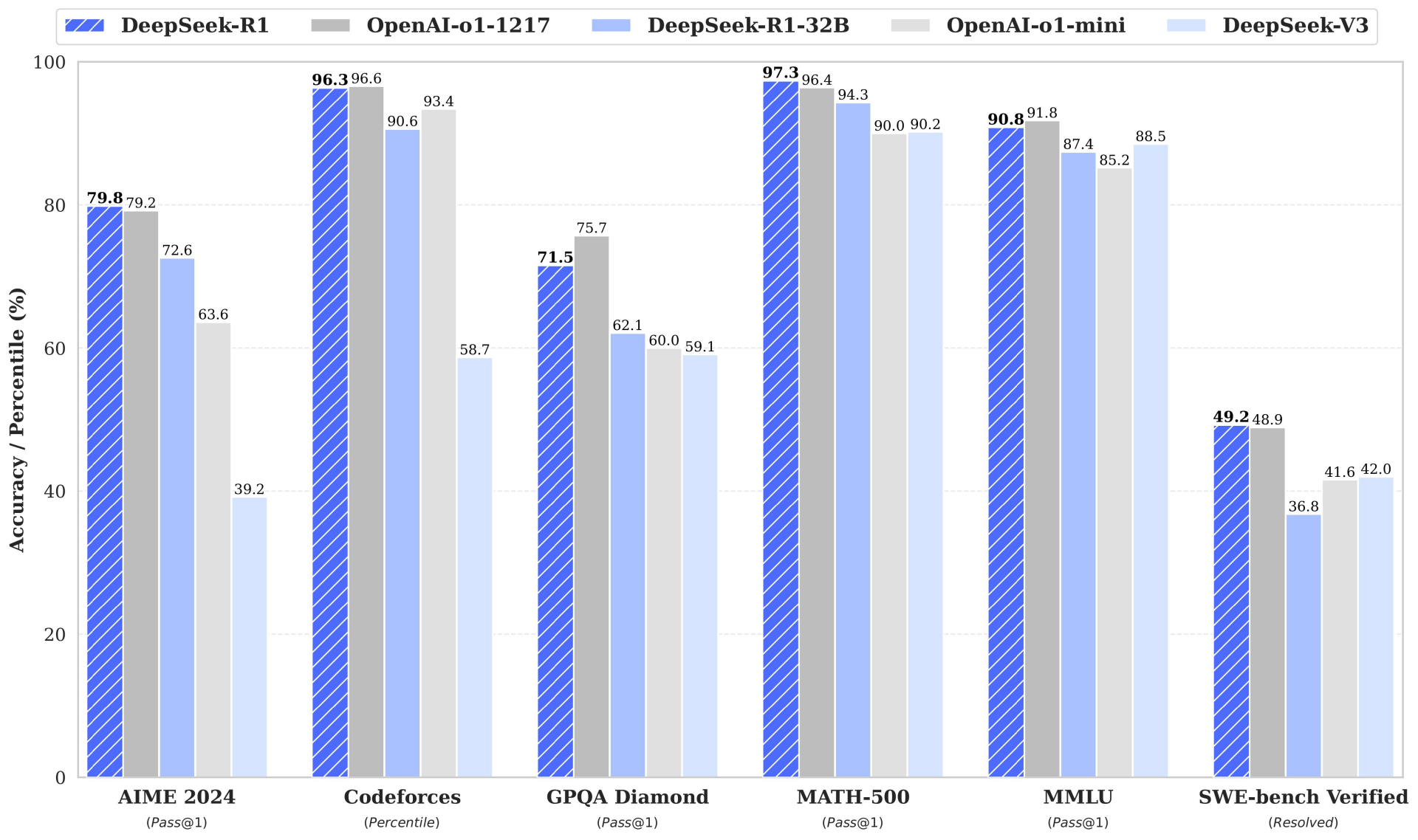
精读简要
- Post-Training:基于大规模强化学习的模型优化;
DeepSeek 直接在基础模型上应用强化学习(RL),而无需依赖监督微调(SFT)作为前置步骤。这种方法使得模型能够探索思维链(CoT)来解决复杂问题,从而开发出了 DeepSeek-R1-Zero。DeepSeek-R1-Zero 展现了自我验证、反思以及生成长思维链的能力,这标志着研究领域的一个重要里程碑。值得注意的是,这是首个公开的研究成果,验证了大语言模型(LLMs)的推理能力可以完全通过强化学习激励,而无需依赖监督微调(SFT)。这一突破为未来在该领域的进一步发展铺平了道路。
DeepSeek 还介绍了开发 DeepSeek-R1 的流程。该流程包含两个RL阶段,旨在发现更优的推理模式并与人类偏好对齐,以及两个SFT阶段,作为模型推理和非推理能力的种子,这一流程将通过创建更好的模型为行业带来益处。
- 蒸馏:小模型也可以很强大
DeepSeek 证明了大模型的推理模式可以通过蒸馏技术迁移到小模型中,从而使这些小模型的性能优于直接通过强化学习(RL)在小模型上发现的推理模式。开源的 DeepSeek-R1 及其API将为研究社区提供支持,帮助未来蒸馏出更优秀的小模型。
DeepSeek 利用 DeepSeek-R1 生成的推理数据,对研究社区广泛使用的多个稠密模型进行了微调。评估结果表明,经过蒸馏的小型稠密模型在基准测试中表现优异。DeepSeek 向社区开源了基于 Qwen2.5 和 Llama3 系列的蒸馏模型,参数规模包括 1.5B、7B、8B、14B、32B 和 70B 的检查点。
DeepSeek-R1-Zero和DeepSeek-R1是基于DeepSeek-V3-Base模型进行训练的。
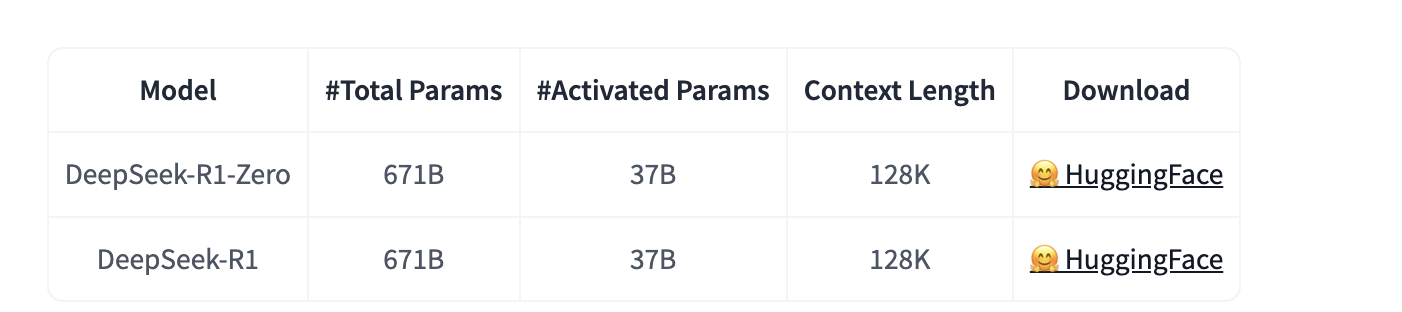
DeepSeek-R1-Distill 模型是基于开源模型进行微调的,使用了DeepSeek-R1生成的样本。DeepSeek对这些模型的配置和分词器进行了轻微调整。

商业协议
DeepSeek 及模型权重遵循 MIT 许可证。DeepSeek-R1 系列支持商业用途,允许任何形式的修改和衍生作品,包括但不限于用于蒸馏训练其他大语言模型(LLMs)。请注意以下事项:
- DeepSeek-R1-Distill-Qwen-1.5B、DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Qwen-14B 和 DeepSeek-R1-Distill-Qwen-32B 是基于 Qwen-2.5 系列开发的,其原始许可证为 Apache 2.0,现使用 DeepSeek-R1 生成的 80 万条样本进行了微调。
- DeepSeek-R1-Distill-Llama-8B 是基于 Llama3.1-8B-Base 开发的,其原始许可证为 llama3.1 许可证。
- DeepSeek-R1-Distill-Llama-70B 是基于 Llama3.3-70B-Instruct 开发的,其原始许可证为 llama3.3 许可证。
本地部署
DeepSeek-R1 与 DeepSeek-V3 可以通过以下硬件和开源社区软件进行本地部署:
- DeepSeek-Infer Demo:DeepSeek 提供了一个简单轻量的演示,支持 FP8 和 BF16 推理。
- SGLang:全面支持 DeepSeek-V3 模型的 BF16 和 FP8 推理模式。
- LMDeploy:支持高效的 FP8 和 BF16 推理,适用于本地和云端部署。
- TensorRT-LLM:目前支持 BF16 推理和 INT4/8 量化,FP8 支持即将推出。
- vLLM:支持 DeepSeek-V3 模型的 FP8 和 BF16 模式,适用于张量并行和流水线并行。
- AMD GPU:通过 SGLang 支持在 AMD GPU 上以 BF16 和 FP8 模式运行 DeepSeek-V3 模型。
- 华为昇腾 NPU:支持在华为昇腾设备上运行 DeepSeek-V3。
DeepSeek-R1-Distill 模型的使用方式与 Qwen 或 Llama 模型相同,如下所示:
vLLM:
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768 --enforce-eager
# 或者如下启动命令
python3 -m vllm.entrypoints.openai.api_server --host 0.0.0.0 --port 12345 --max-model-len 65536 --trust-remote-code --tensor-parallel-size 8 --quantization moe_wna16 --gpu-memory-utilization 0.90 --kv-cache-dtype fp8_e5m2 --calculate-kv-scales --served-model-name deepseek-reasoner --model /workspace/DeepSeek-R1-awq
SGLang:
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --trust-remote-code --tp 2
配置说明
扒一扒 DeepSeek 开源文件,如下所示:
-rw-r--r-- 1 root root 1729 Feb 12 14:13 config.json
-rw-r--r-- 1 root root 10556 Feb 12 14:13 configuration_deepseek.py
drwxr-xr-x 2 root root 4096 Feb 12 14:11 figures
-rw-r--r-- 1 root root 171 Feb 12 14:13 generation_config.json
-rw-r--r-- 1 root root 1064 Feb 12 14:12 LICENSE
-rw-r--r-- 1 root root 5234139343 Feb 12 14:17 xxxxx.safetensors
.............................................................
-rw-r--r-- 1 root root 75769 Feb 12 14:19 modeling_deepseek.py
-rw-r--r-- 1 root root 8898324 Feb 12 14:08 model.safetensors.index.json
-rw-r--r-- 1 root root 18582 Feb 12 14:17 README.md
-rw-r--r-- 1 root root 3584 Feb 12 14:25 tokenizer_config.json
-rw-r--r-- 1 root root 7847602 Feb 12 14:13 tokenizer.json
- 模型权重 (.safetensors)
- xxx.safetensors
- 作用:存储神经网络的参数(如权重和偏置),是 DeepSeek 训练好的模型核心数据。
- 格式:.safetensors 是一种高效、安全的张量存储格式,比 .bin 更快,避免了 pickle 相关的安全问题。
- 配置文件
- config.json:定义模型架构(如层数、隐藏单元、注意力头数等)。
- generation_config.json:控制文本生成参数(如最大长度、温度、top-k、top-p 等)。
- tokenizer_config.json:定义分词器的相关参数。
- 模型代码
- modeling_deepseek.py:实现模型的 前向传播(forward),定义了模型的结构。
- configuration_deepseek.py:模型的初始化配置,加载参数用的。
- tokenizer.json:存储分词器(Tokenizer),用于将文本转换为模型可理解的 token。
- 附加文件
- README.md:文档说明。
- LICENSE:开源许可证。
- figures/:可能包含模型架构或训练过程的可视化图表。
config.json 的配置文件如下所示:
{
"architectures": [
"DeepseekV3ForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"auto_map": {
"AutoConfig": "configuration_deepseek.DeepseekV3Config",
"AutoModel": "modeling_deepseek.DeepseekV3Model",
"AutoModelForCausalLM": "modeling_deepseek.DeepseekV3ForCausalLM"
},
"aux_loss_alpha": 0.001,
"bos_token_id": 0,
"eos_token_id": 1,
"ep_size": 1,
"first_k_dense_replace": 3,
"hidden_act": "silu",
"hidden_size": 7168,
"initializer_range": 0.02,
"intermediate_size": 18432,
"kv_lora_rank": 512,
"max_position_embeddings": 163840,
"model_type": "deepseek_v3",
"moe_intermediate_size": 2048,
"moe_layer_freq": 1,
"n_group": 8,
"n_routed_experts": 256,
"n_shared_experts": 1,
"norm_topk_prob": true,
"num_attention_heads": 128,
"num_experts_per_tok": 8,
"num_hidden_layers": 61,
"num_key_value_heads": 128,
"num_nextn_predict_layers": 1,
"pretraining_tp": 1,
"q_lora_rank": 1536,
"qk_nope_head_dim": 128,
"qk_rope_head_dim": 64,
"quantization_config": {
"activation_scheme": "dynamic",
"fmt": "e4m3",
"quant_method": "fp8",
"weight_block_size": [
128,
128
]
},
"rms_norm_eps": 1e-06,
"rope_scaling": {
"beta_fast": 32,
"beta_slow": 1,
"factor": 40,
"mscale": 1.0,
"mscale_all_dim": 1.0,
"original_max_position_embeddings": 4096,
"type": "yarn"
},
"rope_theta": 10000,
"routed_scaling_factor": 2.5,
"scoring_func": "sigmoid",
"seq_aux": true,
"tie_word_embeddings": false,
"topk_group": 4,
"topk_method": "noaux_tc",
"torch_dtype": "bfloat16",
"transformers_version": "4.46.3",
"use_cache": true,
"v_head_dim": 128,
"vocab_size": 129280
}
模型架构
| 参数 | 值 | 技术说明 |
|---|---|---|
| model_type | deepseek_v3 | 模型系列标识,代表第三代深度搜索架构 |
| architectures | [“DeepseekV3ForCausalLM”] | 自回归文本生成专用架构 |
| num_hidden_layers | 61 | 深层Transformer结构(约2倍于Llama3-70B) |
| hidden_size | 7168 | 隐藏层维度(Llama3两倍:Llama3-70B为8192) |
| intermediate_size | 18432 | FFN层扩展维度(计算公式:hidden_size * 2.57) |
| vocab_size | 129280 | 支持多语言的大词表(含中文/代码/数学符号) |
注意力机制
| 参数 | 值 | 技术特性 |
|---|---|---|
| num_attention_heads | 128 | 多头注意力机制(每头维度56) |
| num_key_value_heads | 128 | Key-Value头数(与注意力头1:1对应) |
| attention_dropout | 0.0 | 关闭注意力随机丢弃(提升推理稳定性) |
| qk_nope_head_dim | 128 | 标准注意力头维度 |
| qk_rope_head_dim | 64 | 带旋转位置编码的头维度 |
位置编码 (RoPE)
| 参数 | 值 | 实现细节 |
|---|---|---|
| max_position_embeddings | 163840 | 支持163K tokens长上下文(≈12万汉字) |
| rope_theta | 10000 | 位置编码基频参数 |
| rope_scaling.type | yarn | 采用YAReN(Yet Another RoPE Extension)扩展方法 |
| rope_scaling.factor | 40 | 位置编码扩展系数(原始4096→扩展163840) |
| rope_scaling.beta_fast | 32 | 高频分量衰减系数 |
| rope_scaling.beta_slow | 1 | 低频分量保持系数 |
专家混合系统 (MoE)
| 参数 | 值 | 设计特点 |
|---|---|---|
| n_routed_experts | 256 | 专家总数(每层) |
| num_experts_per_tok | 8 | 每个token路由8个专家 |
| topk_group | 4 | 专家选择分组数 |
| routed_scaling_factor | 2.5 | 专家输出加权系数 |
量化与优化
| 参数 | 值 | 实现方案 |
|---|---|---|
| torch_dtype | bfloat16 | 基础训练精度 |
| quantization_config | FP8 | 支持动态8位浮点量化 |
| q_lora_rank | 1536 | Query投影矩阵低秩适配 |
| kv_lora_rank | 512 | Key-Value投影低秩优化 |
tokenizer_config.json 配置文件如下所示:
{
"add_bos_token": true,
"add_eos_token": false,
"bos_token": {
"__type": "AddedToken",
"content": "<|begin▁of▁sentence|>",
"lstrip": false,
"normalized": true,
"rstrip": false,
"single_word": false
},
"clean_up_tokenization_spaces": false,
"eos_token": {
"__type": "AddedToken",
"content": "<|end▁of▁sentence|>",
"lstrip": false,
"normalized": true,
"rstrip": false,
"single_word": false
},
"legacy": true,
"model_max_length": 16384,
"pad_token": {
"__type": "AddedToken",
"content": "<|end▁of▁sentence|>",
"lstrip": false,
"normalized": true,
"rstrip": false,
"single_word": false
},
"sp_model_kwargs": {},
"unk_token": null,
"tokenizer_class": "LlamaTokenizerFast",
"chat_template": "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% set ns = namespace(is_first=false, is_tool=false, is_output_first=true, system_prompt='', is_first_sp=true) %}{%- for message in messages %}{%- if message['role'] == 'system' %}{%- if ns.is_first_sp %}{% set ns.system_prompt = ns.system_prompt + message['content'] %}{% set ns.is_first_sp = false %}{%- else %}{% set ns.system_prompt = ns.system_prompt + '\\n\\n' + message['content'] %}{%- endif %}{%- endif %}{%- endfor %}{{ bos_token }}{{ ns.system_prompt }}{%- for message in messages %}{%- if message['role'] == 'user' %}{%- set ns.is_tool = false -%}{{'<|User|>' + message['content']}}{%- endif %}{%- if message['role'] == 'assistant' and 'tool_calls' in message %}{%- set ns.is_tool = false -%}{%- for tool in message['tool_calls'] %}{%- if not ns.is_first %}{%- if message['content'] is none %}{{'<|Assistant|><|tool▁calls▁begin|><|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<|tool▁call▁end|>'}}{%- else %}{{'<|Assistant|>' + message['content'] + '<|tool▁calls▁begin|><|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<|tool▁call▁end|>'}}{%- endif %}{%- set ns.is_first = true -%}{%- else %}{{'\\n' + '<|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<|tool▁call▁end|>'}}{%- endif %}{%- endfor %}{{'<|tool▁calls▁end|><|end▁of▁sentence|>'}}{%- endif %}{%- if message['role'] == 'assistant' and 'tool_calls' not in message %}{%- if ns.is_tool %}{{'<|tool▁outputs▁end|>' + message['content'] + '<|end▁of▁sentence|>'}}{%- set ns.is_tool = false -%}{%- else %}{% set content = message['content'] %}{% if '</think>' in content %}{% set content = content.split('</think>')[-1] %}{% endif %}{{'<|Assistant|>' + content + '<|end▁of▁sentence|>'}}{%- endif %}{%- endif %}{%- if message['role'] == 'tool' %}{%- set ns.is_tool = true -%}{%- if ns.is_output_first %}{{'<|tool▁outputs▁begin|><|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- set ns.is_output_first = false %}{%- else %}{{'<|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- endif %}{%- endif %}{%- endfor -%}{% if ns.is_tool %}{{'<|tool▁outputs▁end|>'}}{% endif %}{% if add_generation_prompt and not ns.is_tool %}{{'<|Assistant|>'}}{% endif %}"
}