LLM 专有名词
量化(Quantization)
基础知识
LLM 大模型的量化技术主要是通过对模型参数进行压缩和量化,从而降低模型的存储和计算复杂度。具体来说如下:
- 参数压缩:通过将模型中的浮点数参数转换为低精度的整数参数,量化技术可以实现参数的压缩。这不仅可以减少模型所需的存储空间,还可以降低模型加载的时间。
- 计算加速:由于低精度整数运算的速度远快于浮点数运算,量化技术还可以通过降低计算复杂度来实现计算加速。这可以在保证模型性能的同时,提高模型的推理速度。
量化技术的三个主要目的:节省显存、加速计算、降低通讯量。
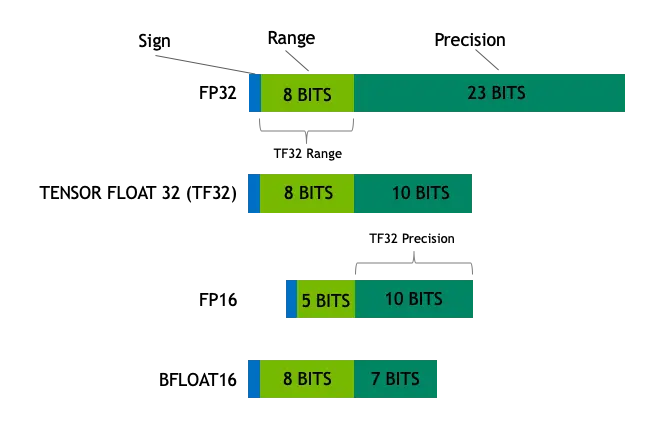
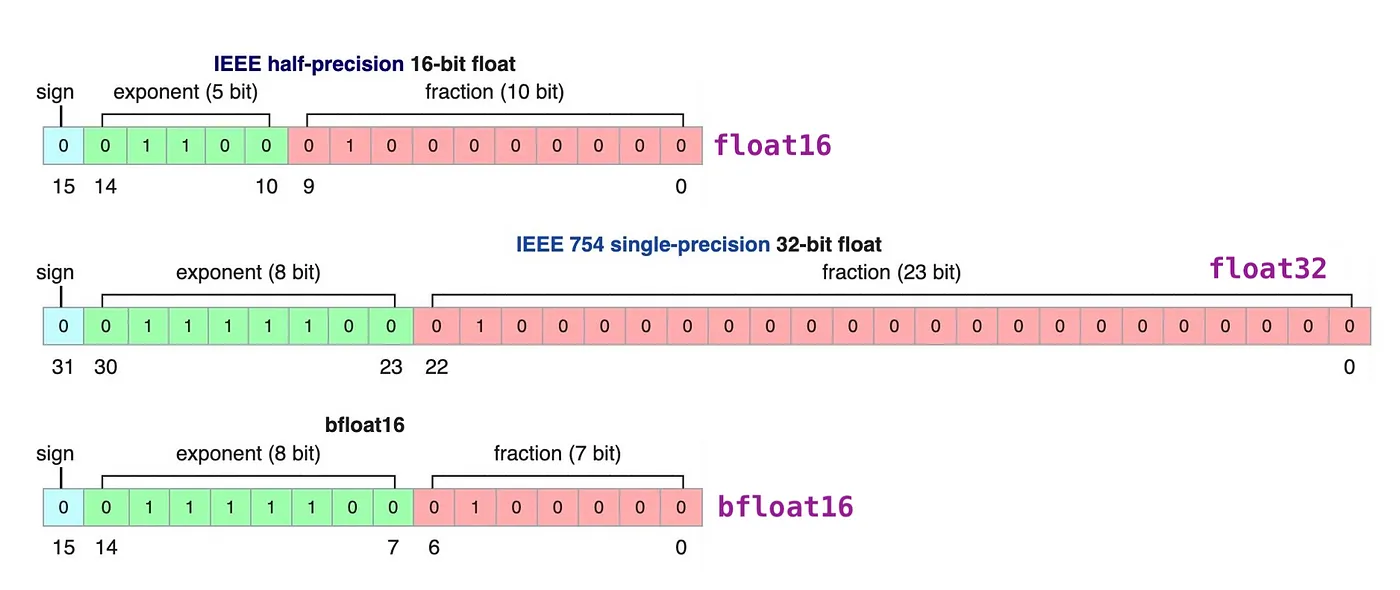
- FP32:在深度学习中,单精度浮点数格式FP32是一种广泛使用的数据格式,其可以表示很大的实数范围,足够深度学习训练和推理中使用。这种格式使用4个bytes(32bits)表示;
- Tensor Float 32: Tensor Float 32是Tensor Core支持新的数值类型,从NVIDIA A100中开始支持。A100的普通FP32的峰值计算速度为19.5TOPs,而TF32的峰值计算速度为156TOPs,提升了非常多;在深度学习中,其实我们对浮点数的表示范围比较看重,而有效数字不是那么重要。在这个前提下,TF直接就把FP32中23个分数值截短为10bits,而指数位仍为8bits,总长度为19(=1+8+10)bits。至于为什么是10bits 就够了,那是因为FP16就只有10bits用来表示分数值。而在实际测试中,FP16的精度水平已经足够应对深度学习负载,只是表示的范围不够广而已;
- FP16:FP16是一种半精度浮点格式,深度学习有使用FP16而不是FP32的趋势,因为较低精度的计算对于神经网络来说似乎并不重要。额外的精度没有任何作用,同时速度较慢,需要更多内存并降低通信速度;
- BFLOAT16:由Google开发的16位浮点格式称为“Brain Floating Point Format”,简称“bfloat16”。这个名字来源于“Google Brain”,这是谷歌的一个人工智能研究小组;FP16设计时并未考虑深度学习应用,其动态范围太窄。BFLOAT16解决了这个问题,提供与FP32相同的动态范围。其可以认为是直接将FP32的前16位截取获得的,现在似乎也有取代FP16的趋势;
量化分类
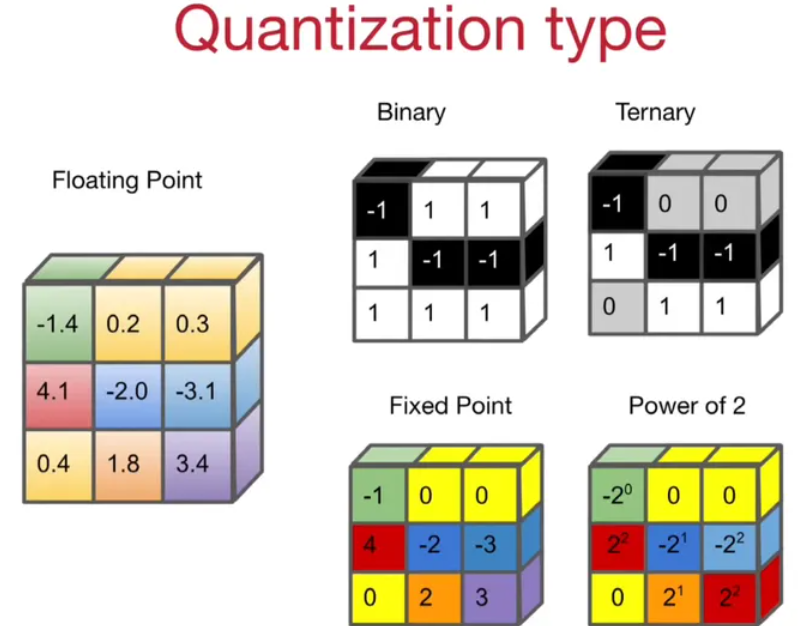
可以分为四类:二值量化(1, -1)、三值量化(-1, 0, 1)、定点数量化(INT4, INT8)、2 的指数量化。
根据量化节点的分布:可以分为均匀量化和非均匀量化。 非均匀量化可以根据待量化参数的概率分布计算量化节点。如果某一个区域参数取值较为密集,就多分配一些量化节点,其余部分少一些。这样量化精度较高,但计算复杂度也高,如下所示:
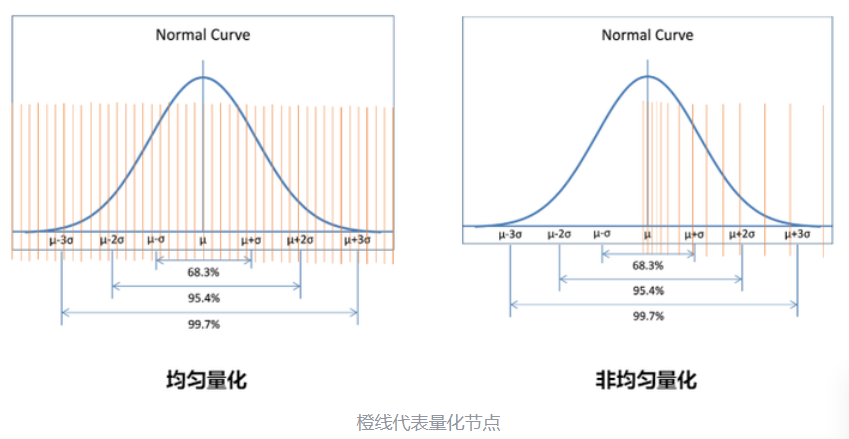
现在 LLM 主要采用的是均匀量化,它又可以分为对称量化、非对称量化。前者是后者的一种特殊情况。量化,就是要选择合适的量化系数,平衡截断误差和舍入误差。
根据量化的时机,有量化感知训练和训练后量化两条路径。
- 训练后量化,训练后量化 PTQ:将已经训练好的模型的权重转换为较低的精度,而无需任何再训练。尽管PTQ简单易实现,但由于权重值的精度损失,它可能会略微降低模型的性能。目前针对 LLM 的量化研究都集中在 Post-training quantization (PTQ),像 LLM.int8()、SmoothQuant、GPT-Q 都属于这一范畴。
对于权重而言,我们可以在推理前事先计算好量化系数,完成量化。但是对于激活(即各层的输入),它们事先是未知的,取决于具体的推理输入,会更加棘手。根据对激活的量化,分为动态与静态量化。
- 动态量化:顾名思义,这是 on-the-fly 的方式:推理过程中,实时计算激活的量化系数,对激活进行量化;
- 静态量化:与动态量化相反,静态量化在推理前就计算好激活的量化系数,在推理过程中应用即可;
- 量化感知训练:与PTQ不同,QAT在训练阶段集成了权重转换过程。这通常不会明显降低模型性能,但对计算的要求更高。QLoRA就是一种高度使用QAT的技术。
Quantization Aware Training (QAT) 量化感知训练:首先正常预训练模型,然后在模型中插入“伪量化节点”,继续微调。所谓“伪量化节点”,就是对权重和激活先量化,再反量化。这样引入了量化误差,让模型在训练过程中“感知”到量化操作,在优化 training loss 的同时兼顾 quantization error。
- 通过 QAT,可以减小量化误差,尝试用更低的位宽去量化模型。
- QAT 虽好,但插入“伪量化节点”后微调大大增加了计算成本,尤其是面对超大规模的 LLM。
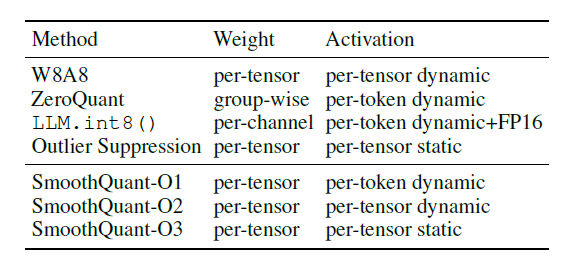
量化效果
目前发现不使用4字节FP32精度转而使用2字节BF16/FP16半精度可以获得几乎相同的推理结果,同时模型大小会减半。如果再从2字节半精度转成仅1字节的8bits数据类型,甚至4bits类型呢?
实际上,对于大模型最常见的就是8bits量化(FP8/INT8)和4bits量化(FP4/NF4/INT4);量化通过减少每个模型权重所需的位数,显著降低了模型的大小。模型一个典型的场景是将权重从FP16(16位浮点)减少到INT4(4位整数)。同时,在内存中传输时,也显著降低了带宽占用。这允许模型在更便宜的硬件上或以更高的速度运行。通过降低权重的精度,LLM的整体质量也会受到一些影响。
研究表明,这种影响因所使用的技术而异,较大的模型受到精度变化的影响较小。更大的型号(超过70B)即使转换为4bits也能保持其性能。一些技术,如NF4,表明对其性能没有影响。因此,对于这些较大的型号,4bits似乎是性能和大小/速度之间的最佳折衷,而对于较小的型号,8bits量化可能更好。较大的模型(如超过70B)使用4bit量化其性能没有影响。较小的模型使用8bit量化可能更好。
下面以 Qwen-7B-Chat 为例展示INT8和INT4量化的效果;
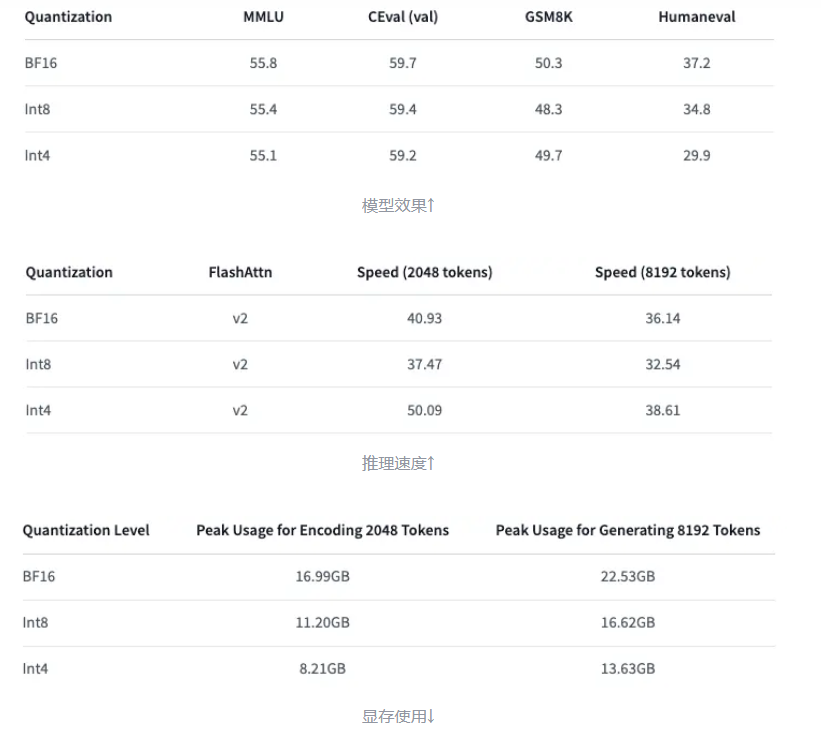
并行策略(Parallelism Strategies)
随着深度学习模型的不断增大,单个计算节点(例如单个 GPU)的计算和内存能力逐渐成为了限制训练效率和模型规模的瓶颈。为了应对这些挑战,深度学习社区提出了多种并行计算策略,其中包括数据并行(Data Parallelism)、模型并行(Model Parallelism)和张量并行(Tensor Parallelism)、流水线并行、多种策略混合并行等;
- 张量并行(Tensor Parallelism):是一种细粒度的并行策略,它通过将张量的计算切分成多个部分,并在多个设备上并行计算来加速训练过程。张量并行通常与数据并行和模型并行结合使用。
- 实现原理:将矩阵乘法 A * B 拆分为多个子矩阵。例如,将 A 按列拆分,B 按行拆分,分配到不同 GPU 上计算。
- 例子:在 GPT-3 中,将 175B 参数的模型拆分到 8 张 GPU 上,每张 GPU 计算部分参数。
- 流水线并行(Pipeline Parallelism):
- 实现原理:将模型的不同层分配到不同设备上。例如,设备 1 计算第 1-10 层,设备 2 计算第 11-20 层。
- 例子:在 Megatron-LM 中,将 100 层的模型拆分到 10 台设备上,每台设备计算 10 层。
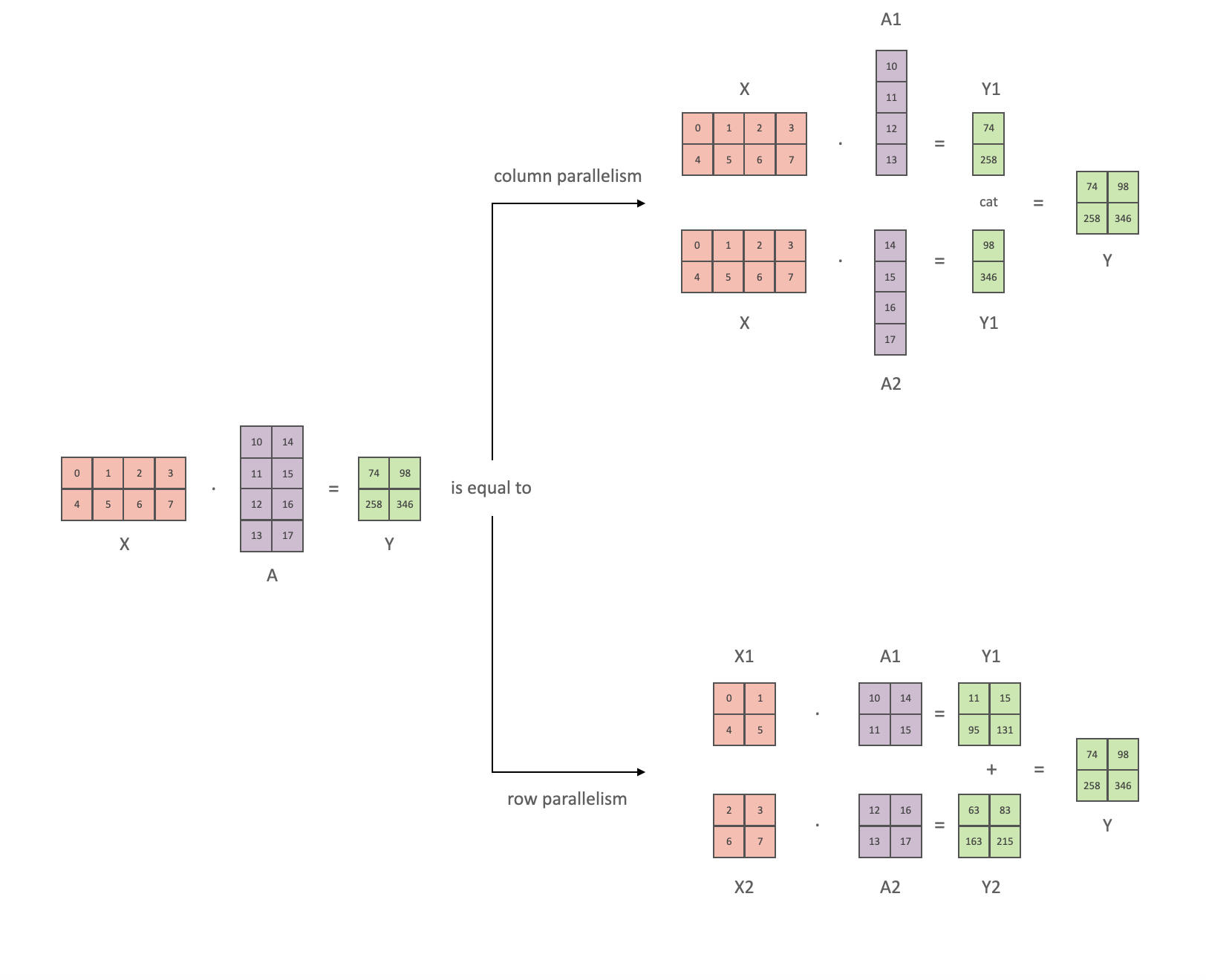
- 数据并行(Data Parallelism):是最常见的并行训练策略之一,它通过将数据集拆分成多个小批次(mini-batch),并将这些小批次分配给不同的计算设备(如不同的 GPU),以此来加速训练。
- 实现原理:将输入数据拆分到多个设备上。例如,将 1000 条数据分配到 10 张 GPU 上,每张 GPU 处理 100 条数据。
- 例子:在 BERT 训练中,使用数据并行加速训练。
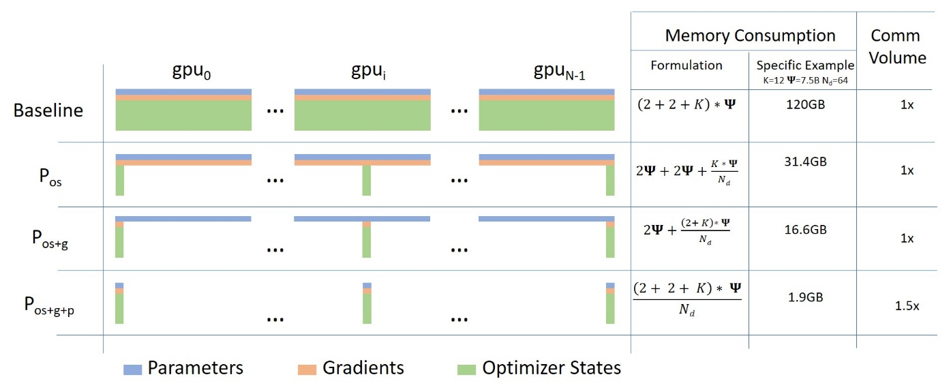
- 模型并行(Model Parallelism):当模型的规模非常大,以至于无法在单个设备的内存中存储时,可以采用模型并行策略。与数据并行不同,模型并行通过将模型的不同部分分配到多个设备上进行计算,而不是将数据拆分。
- 实现原理:模型并行是一种将深度学习模型的结构拆分为多个独立部分,并将这些部分分配到不同计算设备(如GPU)的并行策略。每个设备负责处理整个输入数据的特定模型部分,通过设备间通信传递中间结果(如激活值)。
- 垂直拆分:将模型的不同层组分配到不同设备。例如,前5层在GPU1,后5层在GPU2,前向传播时数据依次传递。
- 组件拆分:将模型的不同功能模块分配到不同设备。例如,在Transformer模型中,编码器在GPU1,解码器在GPU2。
- 例子:
- AlexNet(2012):由于当时单个GPU显存不足,将网络的前半部分(卷积层)和后半部分(全连接层)分配到两块GPU上,实现了最早的模型并行。
- Transformer 大模型:将模型的编码器层分配到GPU1,解码器层分配到GPU2,每个设备处理完整输入数据但仅执行部分计算。
- 混合专家模型(MoE):将不同的专家子模型分配到不同设备,通过门控网络动态路由输入数据。
- 实现原理:模型并行是一种将深度学习模型的结构拆分为多个独立部分,并将这些部分分配到不同计算设备(如GPU)的并行策略。每个设备负责处理整个输入数据的特定模型部分,通过设备间通信传递中间结果(如激活值)。
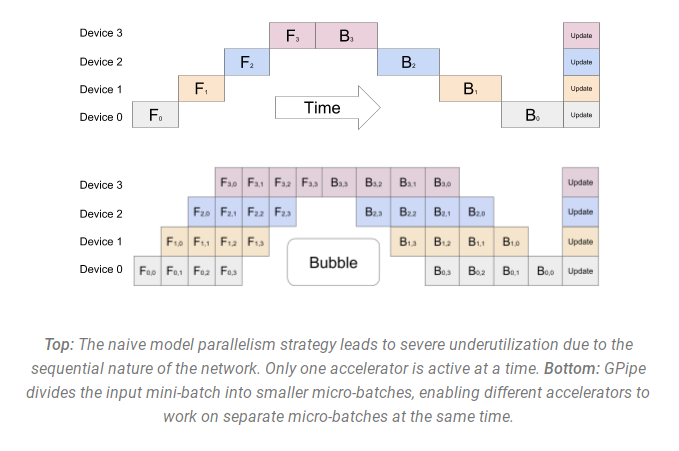
- 混合并行(Hybrid Parallelism)
- 实现原理:结合多种并行策略以应对超大规模模型训练。例如:
- 模型并行 + 数据并行:将模型拆分到多台服务器,每台服务器内部使用数据并行。
- 张量并行 + 流水线并行:在单层内拆分张量(张量并行),同时将不同层分配到不同设备(流水线并行)。
- 例子:
- GPT-3(175B):使用 张量并行(单层拆分) + 流水线并行(层间拆分) + 数据并行(多副本) 的三级混合并行策略。
- Megatron-Turing NLG(530B):结合张量并行(层内拆分)和流水线并行(层间拆分),支持万亿参数模型训练。
- 实现原理:结合多种并行策略以应对超大规模模型训练。例如:
模型并行 vs. 其他并行策略对比:
| 策略类型 | 拆分维度 | 通信需求 | 适用场景 |
|---|---|---|---|
| 模型并行 | 模型结构(层/模块) | 高(传递激活值) | 单设备无法容纳整个模型(如单个GPU显存不足) |
| 张量并行 | 单层内的张量计算 | 中(All-Reduce) | 超大参数矩阵运算(注意力头/FFN层) |
| 流水线并行 | 模型层 + 数据批次 | 中(微批次调度) | 超深层模型训练(千层Transformer) |
| 数据并行 | 输入数据批次 | 高(梯度同步) | 大规模数据训练(多GPU/TPU集群) |
权重(Weights)
在大模型(如 GPT、BERT、Transformer 等)中,权重(Weights) 是模型的核心组成部分,决定了模型如何对输入数据进行变换和组合。随着模型规模的不断增大,权重的存储、计算和优化成为了训练和推理的关键挑战。
定义与挑战
权重是模型中的可学习参数,通常表示为矩阵或向量。在神经网络中,权重连接了不同层之间的神经元,用于计算输入数据的加权和。
- 权重决定了输入特征对输出的贡献程度。
- 通过训练,模型学习到最优的权重,从而能够对输入数据做出准确的预测。
随着模型规模的增大,权重带来了以下挑战:
- 存储需求:
- 大模型的权重数量巨大(如 GPT-3 有 1750 亿参数),单个 GPU 或节点的内存无法容纳。
- 计算需求:
- 权重的计算(如矩阵乘法)需要大量的计算资源。
- 通信开销:
- 在分布式训练中,权重的同步和更新需要高效的通信机制。
- 优化难度:
- 大模型的权重优化需要更复杂的算法和更大的数据集。
并行计算策略与权重的结合:可见上述并行策略(Parallelism Strategies);
优化与可视化
权重通常存储在 GPU 显存或分布式存储系统中,使用混合精度训练(如 FP16)可以减少权重的存储需求。
优化点:
- 使用分布式优化器(如 ZeRO、Sharded Data Parallel)优化权重的存储和通信。
- 通过梯度裁剪、权重正则化等技术防止权重爆炸或消失。
可视化:
- 可视化权重矩阵,观察模型的学习模式。
- 例如,可视化卷积核权重,观察滤波器提取的特征。
- 分析权重的分布和变化,评估模型的训练效果。
- 例如,通过权重直方图分析模型的收敛情况。
蒸馏(Distillation)
LLM 蒸馏 (Distillation) 是一种技术,用于将大型语言模型 (LLM) 的知识转移到较小的模型中。其主要目的是在保持模型性能的同时,减少模型的大小和计算资源需求。通过蒸馏技术,较小的模型可以在推理时更高效地运行,适用于资源受限的环境。
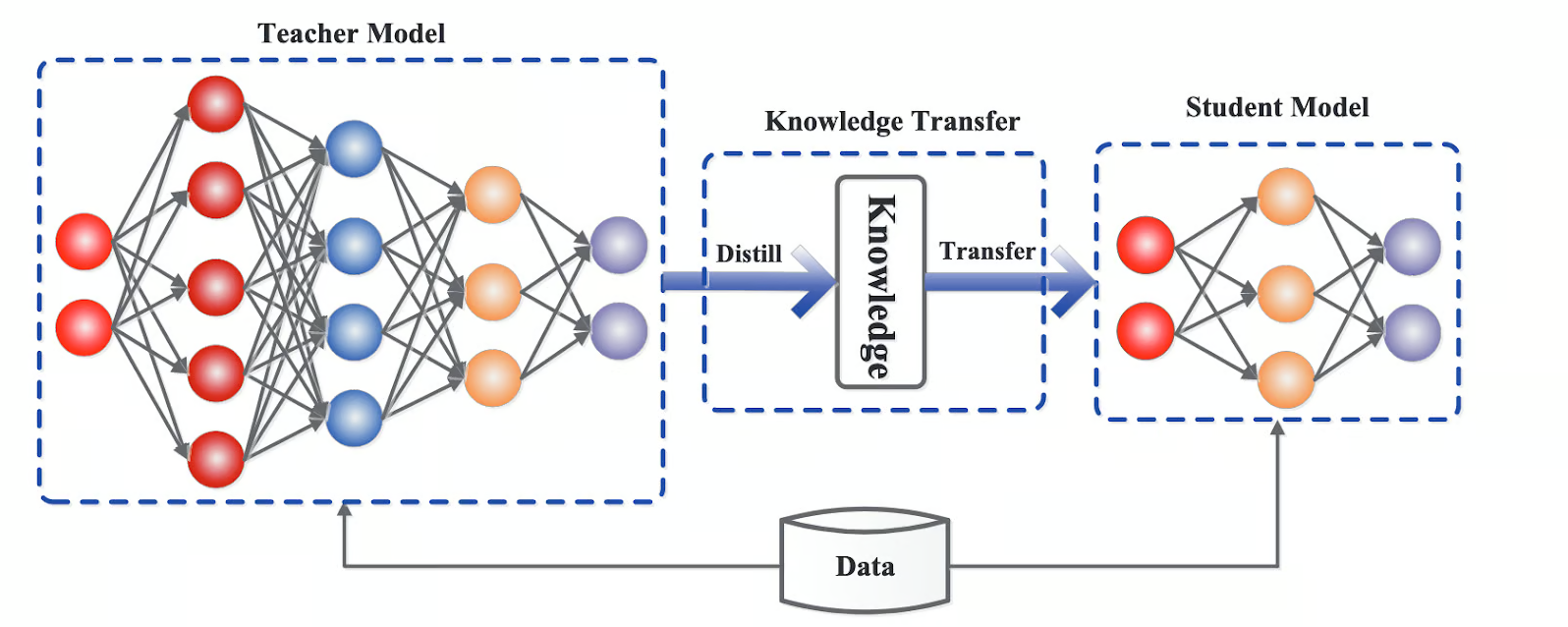
蒸馏过程
蒸馏过程通常包括以下几个步骤:
- 训练教师模型:首先训练一个大型且性能优越的教师模型。
- 生成软标签:使用教师模型对训练数据进行预测,生成软目标 (soft targets) ,这些目标包含了教师模型的概率分布信息。
- 训练学生模型:使用软目标 (soft targets) 和原始训练数据 (hard targets) 来训练较小的学生模型,使其能够模仿教师模型的行为。这种方法不仅可以提高模型的效率,还可以在某些情况下提高模型的泛化能力。
蒸馏分类
- 知识蒸馏(Knowledge Distillation):
- 实现原理:使用大模型的输出(软标签)作为监督信号。例如,大模型输出概率分布 [0.7, 0.2, 0.1],小模型学习模仿该分布。
- 例子:将 GPT-3 的知识蒸馏到 GPT-2,小模型性能接近大模型。
- 任务蒸馏(Task Distillation):
- 实现原理:使用任务特定的输出(如分类概率)作为监督信号。例如,大模型输出分类概率 [0.9, 0.1],小模型学习模仿。
- 例子:将 BERT 的任务蒸馏到 TinyBERT,小模型在分类任务上表现优异。
蒸馏问题
- 信息丢失:由于学生模型比教师模型小,可能无法完全捕捉教师模型的所有知识和细节,导致信息丢失。
- 依赖教师模型:学生模型的性能高度依赖于教师模型的质量,如果教师模型本身存在偏差或错误,学生模型可能会继承这些问题。
- 适用性限制:蒸馏技术可能不适用于所有类型的模型或任务,尤其是那些需要高精度和复杂推理的任务。
监督微调(Supervised Fine-Tuning, SFT)
微调(Fine-tuning)是一种迁移学习的方法,用于在一个预训练模型的基础上,通过在特定任务的数据上进行有监督训练,来适应该任务的要求并提高模型性能。微调利用了预训练模型在大规模通用数据上学习到的语言知识和表示能力,将其迁移到特定任务上。
下面是一般的微调步骤:
- 预训练模型选择:选择一个在大规模数据上进行预训练的模型作为基础模型。例如,可以选择一种预训练的语言模型,如BERT、GPT等。
- 数据准备:准备用于微调的特定任务数据集。这些数据集应包含任务相关的样本和相应的标签或目标。确保数据集与任务的特定领域或问题相关。
- 构建任务特定的模型头:根据任务的要求,构建一个特定的模型头(task-specific head)。模型头是添加到预训练模型之上的额外层或结构,用于根据任务要求进行输出预测或分类。例如,对于文本分类任务,可以添加一个全连接层和softmax激活函数。
- 参数初始化:将预训练模型的参数作为初始参数加载到微调模型中。这些参数可以被视为模型已经学习到的通用语言表示。
- 微调训练:使用特定任务的数据集对模型进行有监督训练。这包括将任务数据输入到模型中,计算损失函数,并通过反向传播和优化算法(如梯度下降)更新模型参数。在微调过程中,只有模型头的参数会被更新,而预训练模型的参数会保持不变。
- 调整超参数:微调过程中,可以根据需要调整学习率、批量大小、训练迭代次数等超参数,以达到更好的性能。
- 评估和验证:在微调完成后,使用验证集或测试集对微调模型进行评估,以评估其在特定任务上的性能。可以使用各种指标,如准确率、精确率、召回率等。
- 可选的后续微调:根据实际情况,可以选择在特定任务的数据上进行进一步的微调迭代,以进一步提高模型性能。
微调的关键是在预训练模型的基础上进行训练,从而将模型的知识迁移到特定任务上。通过这种方式,可以在较少的数据和计算资源下,快速构建和训练高性能的模型。
微调和参数高效微调是机器学习中用于提高预训练模型在特定任务上的性能的两种方法。
- 微调就是把一个预先训练好的模型用新的数据在一个新的任务上进一步训练它。整个预训练模型通常在微调中进行训练,包括它的所有层和参数。这个过程在计算上非常昂贵且耗时,特别是对于大型模型。
- 参数高效微调是一种专注于只训练预训练模型参数的子集的微调方法。这种方法包括为新任务识别最重要的参数,并且只在训练期间更新这些参数。
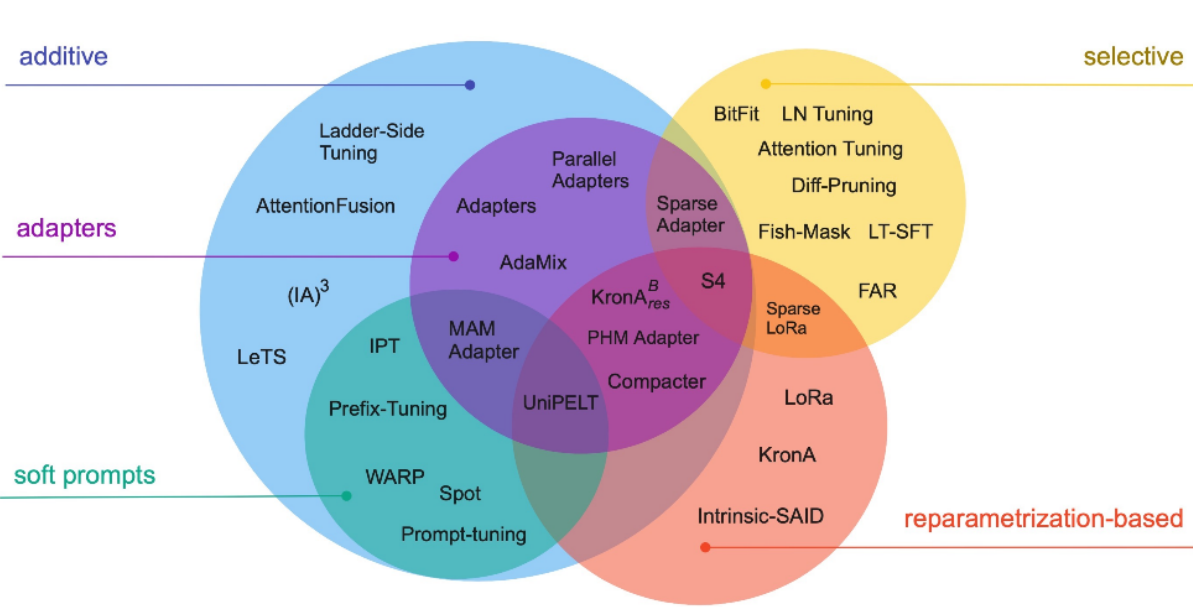
PEFT 可以显著减少微调所需的计算量。高效微调技术可以粗略分为以下三大类:增加额外参数(A)、选取一部分参数更新(S)、引入重参数化(R)。而在增加额外参数这类方法中,又主要分为类适配器(Adapter-like)方法和软提示(Soft prompts)两个小类。
强化学习(Reinforcement Learning, RL)
基础概念
强化学习(Reinforcement Learning, RL) 是机器学习的一个分支,目标是让智能体(agent)通过与环境(environment)的交互来学习最优的行为策略(policy),从而最大化某个累积回报(cumulative reward)。其核心思想是通过试错和反馈的机制,找到在每个情境下的最优决策。
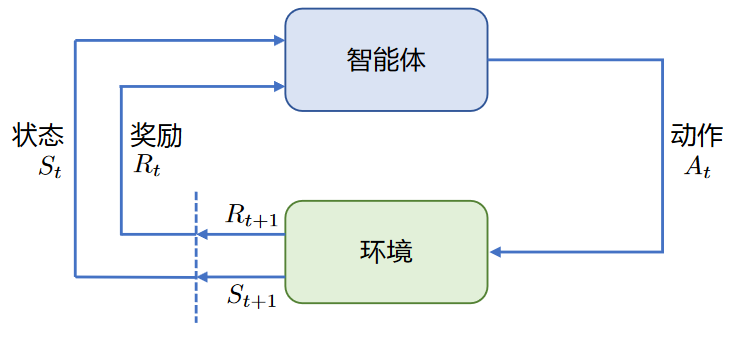
强化学习基本框架如上图所示,主要由两部分组成:智能体和环境。在强化学习过程中,智能体与环境不断交互。 智能体在环境中获取某个状态后,会根据该状态输出一个动作(Action),也称为决策(Decision)。 动作会在环境中执行,环境会根据智能体采取的动作,给出下一个状态以及当前动作所带来的奖励。智能体的目标就是尽可能多地从环境中获取奖励。
强化学习在大语言模型上的重要作用可以概括为以下几个方面:
- 强化学习比有监督学习更可以考虑整体影响:有监督学习针对单个词元进行反馈,其目标是要求模型针对给定的输入给出的确切答案。而强化学习是针对整个输出文本进行反馈,并不针对特定的词元。
- 强化学习更容易解决幻觉问题:有监督学习算法非常容易使得求知型查询产生幻觉。在模型并不包含或者知道答案的情况下,有监督训练仍然会促使模型给出答案。而使用强化学习方法,则可以通过定制奖励函数,将正确答案赋予非常高的分数,放弃回答的答案赋予中低分数,不正确的答案赋予非常高的负分,使得模型学会依赖内部知识选择放弃回答,从而在一定程度上缓解模型幻觉问题。
- 强化学习可以更好的解决多轮对话奖励累积问题:使用强化学习方法,可以通过构建奖励函数,将当前输出考虑整个对话的背景和连贯性
RLHF
RLHF 就是基于人类反馈(Human Feedback)对语言模型进行强化学习(Reinforcement Learning),一般分为以下三个步骤:
- 预训练语言模型(收集样本数据,有监督微调):在人类标注的数据上微调出来的模型叫做有监督的微调(supervised fine-tuning),这是训练出来的第一个模型;
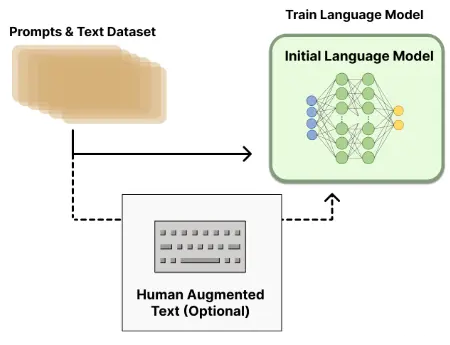
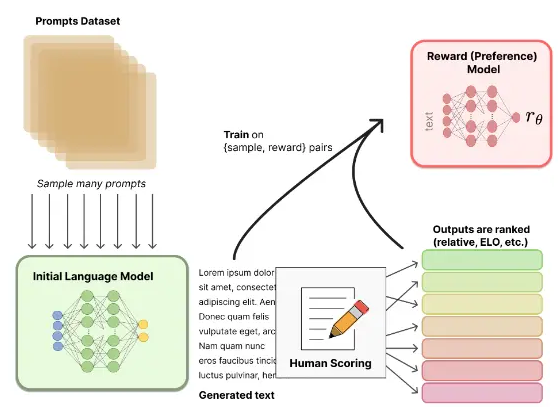
- 训练奖励模型(收集排序数据,训练奖励模型):
- 给定一个问题,让上一步训练好的预训练模型 SFT 生成答案;
- GPT 每一次预测一个词的概率,可以根据这个概率采样出很多答案;
- 这里生成了四个答案,然后把这四个答案的好坏进行人工标注,进行排序标注;
- 有了这些排序之后,再训练一个奖励模型(Reward Model,RM),这个模型是说给定 prompt 得到输出,然后对这个输出生成一个分数,可以认为这个分数是一个奖励或者是打分,使得对答案的分数能够满足人工排序的关系(大小关系保持一致),一旦这个模型生成好之后,就能够对生成的答案进行打分;
- 用强化学习微调(使用RM模型优化SFT模型):继续微调之前训练好的 SFT模型,使得它生成的答案能够尽量得到一个比较高的分数,即每一次将它生成的答案放进 RM 中打分,然后优化 SFT 的参数使得它生成的答案在 RM 中获得更高的分数。
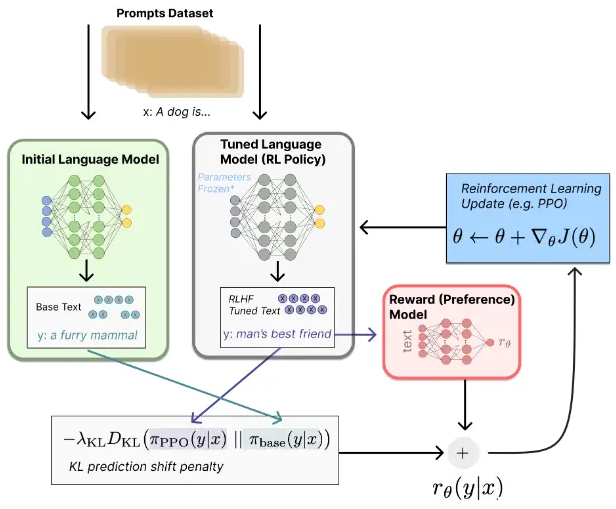
备注:两次对模型的微调:GPT3模型 → SFT模型 → RL模型,其实这里始终都是同一个模型,只是不同过程中名称不同。
- 需要SFT模型的原因: GPT3模型不一定能够保证根据人的指示、有帮助的、安全的生成答案需要人工标注数据进行微调;
- 需要RM模型的原因:标注排序的判别式标注成本远远低于生成答案的生成式标注;
- 需要RL模型的原因:在对SFT模型进行微调时生成的答案分布也会发生变化,会导致RM模型的评分会有偏差,需要用到强化学习;
NVIDIA 卡系列
NVIDIA 的显卡产品线主要分为以下几大系列,每个系列针对不同的应用场景和用户需求:
- GeForce 系列:主要面向消费者市场,适用于游戏玩家和一般用户。该系列提供高性能的图形处理能力,支持实时光线追踪(Ray Tracing)和深度学习超级采样(DLSS)等技术。最新的 GeForce RTX 50 系列基于 Blackwell 架构,型号包括 RTX 5090、5080、5070 等,价格从 $549 至 $1,999 不等。
- NVIDIA RTX 系列(原 Quadro 系列):面向专业图形工作站用户,如设计师、工程师和内容创作者。该系列显卡经过专业软件认证,提供高精度的图形处理能力,适用于 CAD、3D 渲染和视频编辑等专业应用。
- Tesla / A / H / V / B 系列:专为数据中心、高性能计算(HPC)和人工智能(AI)应用设计。这些系列的 GPU 提供强大的计算能力,适用于深度学习训练、科学计算和大规模数据处理等场景。
- TITAN 系列:定位于高端消费市场,兼顾游戏、内容创作和 AI 开发需求。TITAN 系列显卡提供卓越的性能,适合需要高计算能力的专业人士和发烧友。
- Jetson 系列:用于嵌入式系统和边缘计算,适合机器人、物联网(IoT)设备和自动驾驶等应用。Jetson 模块提供强大的 AI 推理能力,支持低功耗、高效能的计算需求。
- DRIVE 系列:专为自动驾驶和车载系统设计,提供高级驾驶辅助系统(ADAS)和自动驾驶所需的计算平台。该系列 GPU 支持复杂的传感器处理和 AI 计算,确保车辆的安全与智能化。
数据中心 & AI 训练/推理
| 型号 | 架构 | FP64 | TF32 | FP16 | BF16 | INT8 | FP8 | 中国特供版 |
|---|---|---|---|---|---|---|---|---|
| H100 | Hopper | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | H800 |
| H800 | Hopper | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ |
| H200 | Hopper | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ |
| B100 | Blackwell | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ |
| B200 | Blackwell | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ |
| A100 | Ampere | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | A800 |
| A800 | Ampere | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ |
| V100 | Volta | ✓ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ |
专业工作站 & 渲染
| 型号 | 架构 | FP64 | TF32 | FP16 | BF16 | INT8 | FP8 | 中国特供版 |
|---|---|---|---|---|---|---|---|---|
| RTX 6000 Ada | Ada | ✗ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ |
| RTX A6000 | Ampere | ✗ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ |
| RTX 5000 Ada | Ada | ✗ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ |
消费级游戏 & 创意
| 型号 | 架构 | FP64 | TF32 | FP16 | BF16 | INT8 | FP8 | 中国特供版 |
|---|---|---|---|---|---|---|---|---|
| RTX 4090 | Ada | ✗ | ✓ | ✓ | ✓ | ✓ | ✗ | RTX 4090D |
| RTX 4090D | Ada | ✗ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ |
| RTX 4080 | Ada | ✗ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ |
| RTX 3090 | Ampere | ✗ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ |
| RTX 2080 Ti | Turing | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ |
计算加速 & 推理
| 型号 | 架构 | FP64 | TF32 | FP16 | BF16 | INT8 | FP8 | 中国特供版 |
|---|---|---|---|---|---|---|---|---|
| T4 | Turing | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ |
| A2 | Ampere | ✗ | ✗ | ✓ | ✓ | ✓ | ✗ | ✗ |
FP8 支持:仅 H100、H200、B100、B200 支持 FP8,适用于 AI 训练 & 推理。中国特供版:
- A800(A100 降规版):降低 NVLink 及带宽限制。
- H800(H100 降规版):降低 NVLink 带宽,适用于中国市场。
- RTX 4090D(RTX 4090 降规版):CUDA 核心减少,适应中国法规。
……
LLM 推理框架
大语言模型(LLM)推理框架是用于高效运行和部署大语言模型的工具,旨在优化推理速度、资源利用率和硬件兼容性。以下是几种主流的大语言模型推理框架及其特点:
常见开源框架
vLLM
特点:
- 高性能:通过创新的 PagedAttention 技术,显著提升推理速度和吞吐量。
- 支持量化:支持 FP8 和 BF16 推理模式,未来将支持 INT4/8 量化。
- 分布式推理:支持张量并行和流水线并行,适合大规模模型部署。
- 易用性:提供简单的 API 接口,支持快速部署。
适用场景:需要高吞吐量和大规模分布式推理的场景。
SGLang
特点:
- 多词元预测:支持多词元预测(Multi-Token Prediction),提升推理效率。
- 硬件兼容性:支持 AMD GPU 和 NVIDIA GPU,提供 FP8 和 BF16 推理模式。
- 灵活性:适用于本地和云端部署,支持动态负载均衡。
适用场景:需要高性能推理和多硬件兼容性的场景。
Llama.cpp
特点:
- 轻量级:专注于 CPU 推理,无需 GPU 支持。
- 量化支持:支持 INT4/8 和 FP16 量化,显著降低内存占用。
- 本地部署:适合在资源受限的环境中运行。
适用场景:本地开发、边缘设备或低资源环境。
TensorRT-LLM
特点:
- 高效推理:基于 NVIDIA TensorRT 优化,提供极致的推理性能。
- 量化支持:支持 BF16 和 INT4/8 量化,未来将支持 FP8。
- 硬件支持:专为 NVIDIA GPU 设计,充分利用硬件加速。
适用场景:需要极致性能的 NVIDIA GPU 环境。
Ollama
特点:
- 轻量级:专注于小型模型和轻量级部署。
- 易用性:提供简单的 API 接口,适合快速集成。
- 资源友好:适合在资源受限的环境中运行。
适用场景:小型项目或边缘设备部署。
DeepSpeed-Inference
特点:
- 分布式推理:支持大规模模型的分布式推理,优化内存和计算资源。
- 量化支持:支持 FP16 和 INT8 量化。
- 灵活性:适用于多种硬件环境。
适用场景:需要分布式推理和高资源利用率的场景。
Hugging Face Transformers
特点:
- 易用性:提供丰富的预训练模型和简单易用的 API。
- 社区支持:拥有庞大的社区和文档支持。
- 灵活性:支持多种硬件和推理后端(如 PyTorch、TensorFlow)。
适用场景:快速原型开发和小规模部署。
FastAPI + ONNX Runtime
特点:
- 跨平台支持:通过 ONNX Runtime 支持多种硬件后端。
- 高效推理:优化模型推理速度,支持量化。
- 易集成:结合 FastAPI 提供高效的 Web 服务。
适用场景:需要跨平台支持和高效 Web 服务的场景。
总结
| 框架 | 硬件支持 | 量化支持 | 并行支持 | 适用场景 |
|---|---|---|---|---|
| vLLM | NVIDIA GPU | FP8、BF16 | 张量/流水线并行 | 高吞吐量、大规模推理 |
| SGLang | AMD GPU、NVIDIA | FP8、BF16 | 张量并行 | 高性能推理、多硬件兼容 |
| Llama.cpp | CPU | INT4/8、FP16 | 无 | 本地开发、低资源环境 |
| TensorRT-LLM | NVIDIA GPU | BF16、INT4/8 | 无 | NVIDIA GPU 极致性能 |
| Ollama | CPU、GPU | FP16 | 无 | 轻量级部署、边缘设备 |
| DeepSpeed-Inference | 多硬件 | FP16、INT8 | 分布式推理 | 大规模分布式推理 |
| Hugging Face Transformers | 多硬件 | FP16、INT8 | 无 | 快速原型开发、小规模部署 |
| FastAPI + ONNX Runtime | 多硬件 | FP16、INT8 | 无 | 跨平台支持、Web 服务 |
LLM 框架选型建议:
- 高性能需求:选择vLLM或SGLang;
- 轻量级部署:选择Llama.cpp或Ollama;
- NVIDIA GPU 优化:选择TensorRT-LLM;
- 分布式推理:选择DeepSpeed-Inference;
- 快速开发:选择Hugging Face Transformers或FastAPI + ONNX Runtime。
SGLang
SGLang https://github.com/sgl-project/sglang 是一个专注于高效服务大型语言模型(LLM)和视觉语言模型(VLM)的开源框架,通过协同设计优化的后端运行时与灵活的前端语言,显著提升了模型交互速度与控制能力。以下是其核心特性的总结:
核心架构
- 高效后端运行时
- RadixAttention:通过基数树管理键值(KV)缓存,实现跨请求的前缀复用,减少冗余计算与内存占用。
- 连续批处理与并行优化:动态调整批量大小以提升 GPU 利用率,支持张量并行(TP)、数据并行(DP)及专家并行(EP),尤其适合混合专家模型(MoE)。
- 量化与加速:支持 INT4、FP8、AWQ、GPTQ 等多种量化方法,结合 FlashInfer 内核优化计算效率,降低显存占用。
- 结构化输出解码:采用压缩有限状态机技术,加速 JSON 等结构化输出生成,速度提升最高达 3 倍。
- 灵活前端语言
- 提供类 Python 的编程接口,支持链式生成调用、多轮对话控制流、多模态输入(文本+图像/视频)及外部工具集成。
- 兼容 OpenAI API,便于迁移现有应用,支持流式响应与复杂提示工程。
生态支持
- 广泛模型兼容性支持主流生成模型(如 Llama 3、Qwen、DeepSeek)和多模态模型(如 LLaVA、LLaVA-NeXT、Yi-VL),并支持自定义模型扩展。
- 多模态应用示例,例如通过 LLaVA-NeXT 模型实现图像描述生成,结合 OpenAI 兼容 API 简化开发流程。
性能优势
- 相比 TensorRT-LLM、vLLM 等框架,SGLang 在多种任务(如逻辑推理、检索增强生成)中实现了最高 6.4 倍吞吐量提升。
- 在处理高分辨率图像时,显存占用稳定(如 70G 显存处理 2560x2560 图像仅需 3.26 秒),显著优于纯 Transformer 实现。
部署与扩展
- 灵活部署方式
- 支持 Docker 快速部署,提供预构建镜像及 Kubernetes。
- 通过 SkyPilot 实现跨云平台一键部署,支持自动扩缩容与故障恢复。
- 分布式扩展支持多节点张量并行,例如在 2 个节点上部署 405B 参数模型,结合 FP8 量化降低通信开销。
社区应用
- 开源社区活跃,提供详细文档、教程及定期线上会议,生态项目包括 SGLang-UI(用户界面库)和 SGLang-Physics(物理引擎扩展)。
- 学术论文与性能测试数据公开,便于开发者深入理解其设计原理。
SGLang 凭借其高效运行时、灵活编程接口及广泛模型支持,成为部署复杂 LLM/VLM 应用的优选框架,尤其适合需要低延迟、高吞吐的场景(如实时交互 AI 助手、多模态分析)。
vLLM

核心技术
- PagedAttention 内存管理
- 通过分页式 KV 缓存管理(类似操作系统虚拟内存机制),解决传统注意力机制中内存碎片化和过度预留的问题,减少 60%-80% 的内存浪费,提升吞吐量 2.2-24 倍。
- 支持内存块共享(如并行采样中共享提示词缓存),降低多序列生成时的内存占用。
- 动态批处理(Continuous Batching)
- 实时合并请求为动态批次,提高 GPU 利用率,避免静态批处理的低效等待。
- 优化的 CUDA 内核
- 结合 FlashAttention、XFormers 等加速库,优化计算效率,支持 FP8、INT4/AWQ/GPTQ 等量化方法。
性能优势
- 吞吐量对比
- 相比 HuggingFace Transformers(HF)提升 14-24 倍,比 HuggingFace TGI 高 2.2-3.5 倍。
- 例如,LLaMA-13B 模型在 A100 GPU 上,vLLM 处理并发请求的响应时间缩短至传统方法的 1/30。
- 内存效率
- 显存占用降低 50%,支持更大批次处理(如 Qwen-14B 模型并发优化效果达 30 倍)。
- 并发处理能力:
- 实测 Qwen-14B 模型在 100 并发下响应时间从 385 秒优化至 11 秒11。
生态支持
- 广泛模型兼容性:
- 支持主流架构如 LLaMA、GPT-2/3、Qwen、Baichuan 等,覆盖 50+ HuggingFace 模型家族。
- 无缝集成自定义模型,支持 trust-remote-code 参数加载非标准架构。
- OpenAI API 兼容性:
- 提供类 OpenAI 的 RESTful API 接口(如 /v1/chat/completions),便于现有应用迁移。
- 量化与分布式推理:
- 支持张量并行(Tensor Parallelism)和多 GPU 分布式推理(通过 Ray 框架),适配昇腾(Ascend)、鲲鹏(KunPeng)等国产硬件平台。
部署与扩展
- 快速部署:
- 单行命令启动服务:
python -m vllm.entrypoints.openai.api_server --model lmsys/vicuna-7b-v1.3
- 支持 Docker 容器化部署,提供 CUDA 12.1 基础镜像及显存优化配置。
- 生产级扩展:
- 多 GPU 分布式服务(如
--tensor-parallel-size 4指定 GPU 数量),结合 Ray 框架实现跨节点扩展。 - 华为昇腾适配案例中,完成 Euler 系统与 NPU 的兼容性验证,推动国产硬件生态发展。
- 多 GPU 分布式服务(如
社区应用
- Chatbot Arena 与 Vicuna 后端:作为 LMSYS 的默认推理引擎,日均处理 30K 请求,峰值达 60K,GPU 使用量减少 50%。
- 企业级应用:腾讯、华为、字节、百度等厂商推荐用于实时问答、推荐系统等场景,结合流式输出(Streaming)优化用户体验。
vLLM https://github.com/vllm-project/vllm 凭借 PagedAttention 和动态批处理技术,其开源生态活跃,支持广泛模型与硬件平台,并通过优化显著降低运营成本,成为大模型推理领域的标杆框架,尤其适合高并发、低延迟的在线服务场景。
LLM 结果评估
大语言模型(LLM)评测是LLM开发和应用中的关键环节,是评估LLM性能、鲁棒性、偏见、幻觉等方面的重要手段。LLM评测的目标是通过一系列的评测任务和指标,全面、客观地评估LLM的性能,为LLM的研发、应用和部署提供参考。
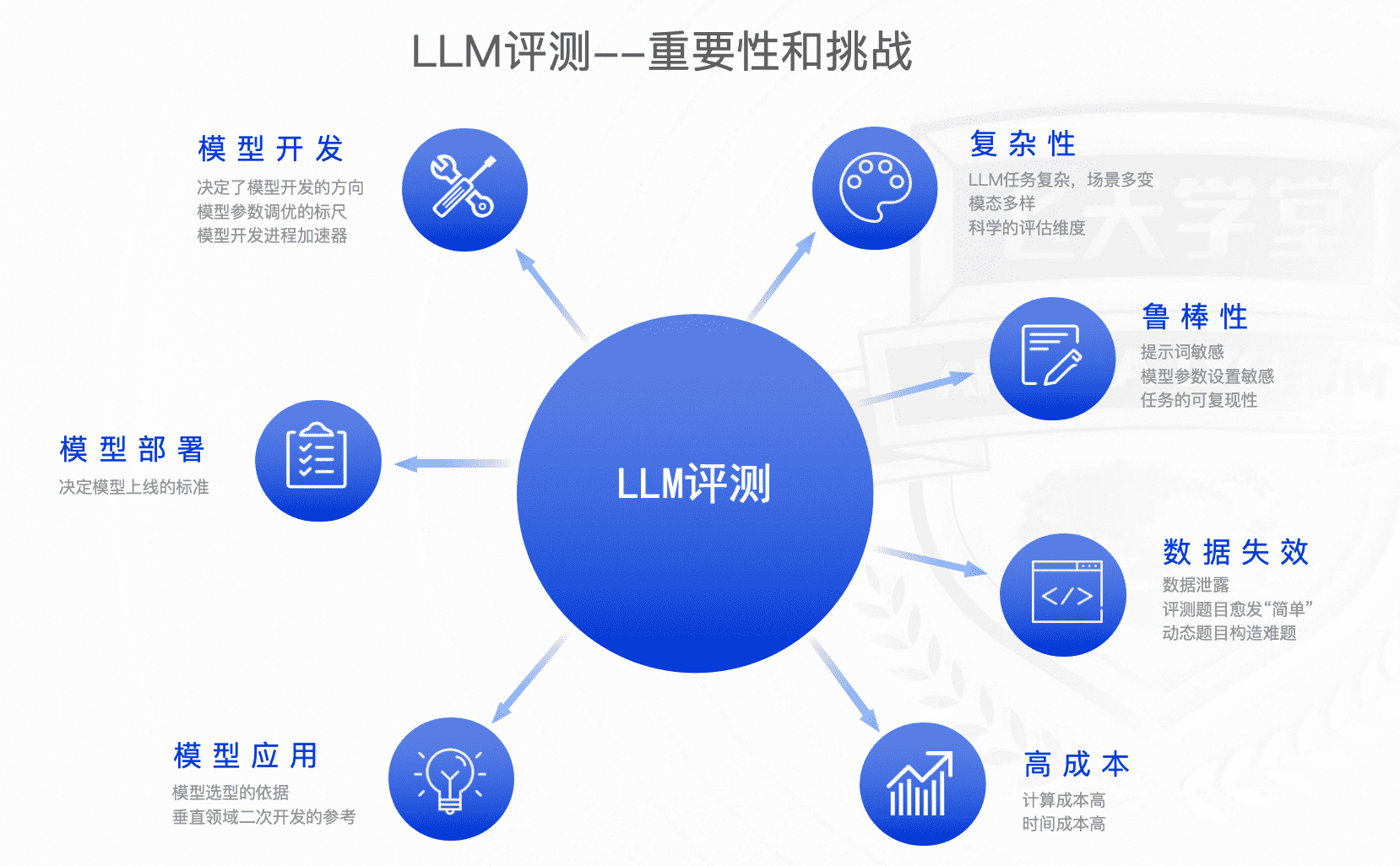
目前评测方法可以分为人工评测和自动评测,其中,自动评测技术相比人工评测来讲,具有效率高、一致性好、可复现、鲁棒性好等特点,逐渐成为业界研究的重点。模型的自动评测技术可以分为rule-based和model-based两大类;
性能指标
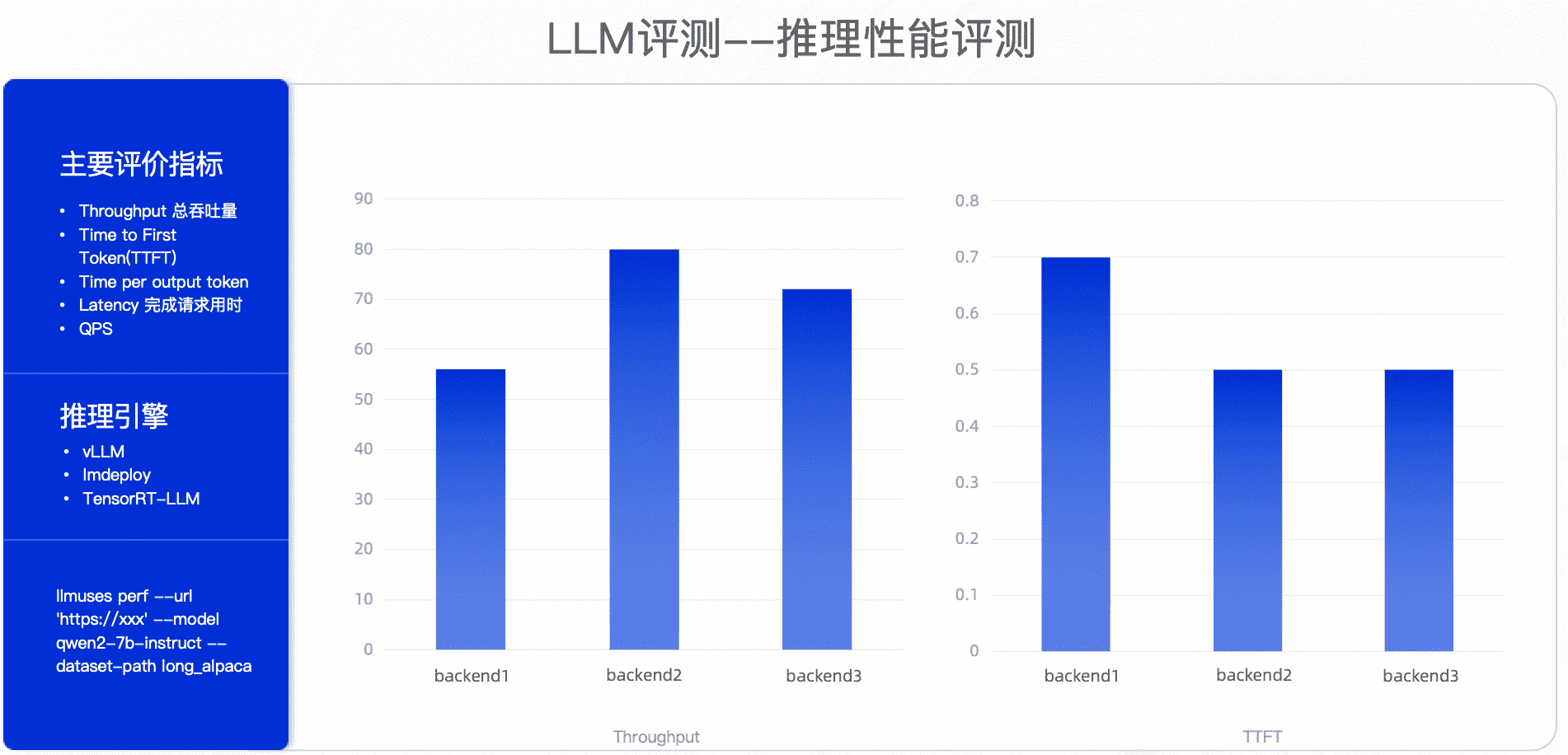
| 类别 | 指标 | 描述 |
|---|---|---|
| 效率 | 吞吐量(Throughput) | 单位时间内处理的请求数量。 |
| 延迟(Latency) | 单个请求从输入到输出所需的时间。 | |
| 响应时间(Response Time) | 从用户发起请求到收到完整响应的时间。 | |
| 并发能力(Concurrency) | 模型在同时处理多个请求时的表现。 | |
| 资源使用 | GPU/CPU 使用率 | 模型推理时 GPU/CPU 的资源占用情况。 |
| 内存占用(Memory Usage) | 模型运行时占用的内存大小。 | |
| 显存利用率(GPU Memory) | GPU 显存的使用情况。 | |
| 磁盘 I/O | 模型加载权重或处理数据时的磁盘读写性能。 | |
| 稳定性 | 错误率(Error Rate) | 在高压下模型返回错误结果或失败请求的比例。 |
| 崩溃率(Crash Rate) | 系统在高压下崩溃或不可用的概率。 | |
| 恢复时间(Recovery Time) | 系统在崩溃或异常后恢复正常运行的时间。 | |
| 扩展性 | 水平扩展能力 | 增加节点或实例后,系统性能的提升情况。 |
| 垂直扩展能力 | 增加单个节点的资源后,系统性能的提升情况。 | |
| 成本 | 单位请求成本 | 处理单个请求所需的计算资源成本。 |
| 资源利用率 | 计算资源的利用率,是否存在资源浪费。 | |
| 用户感知 | 用户体验 | 在高压下,用户是否感知到延迟或质量下降。 |
| 服务可用性 | 系统在高压下是否仍然可用。 |
测试示例
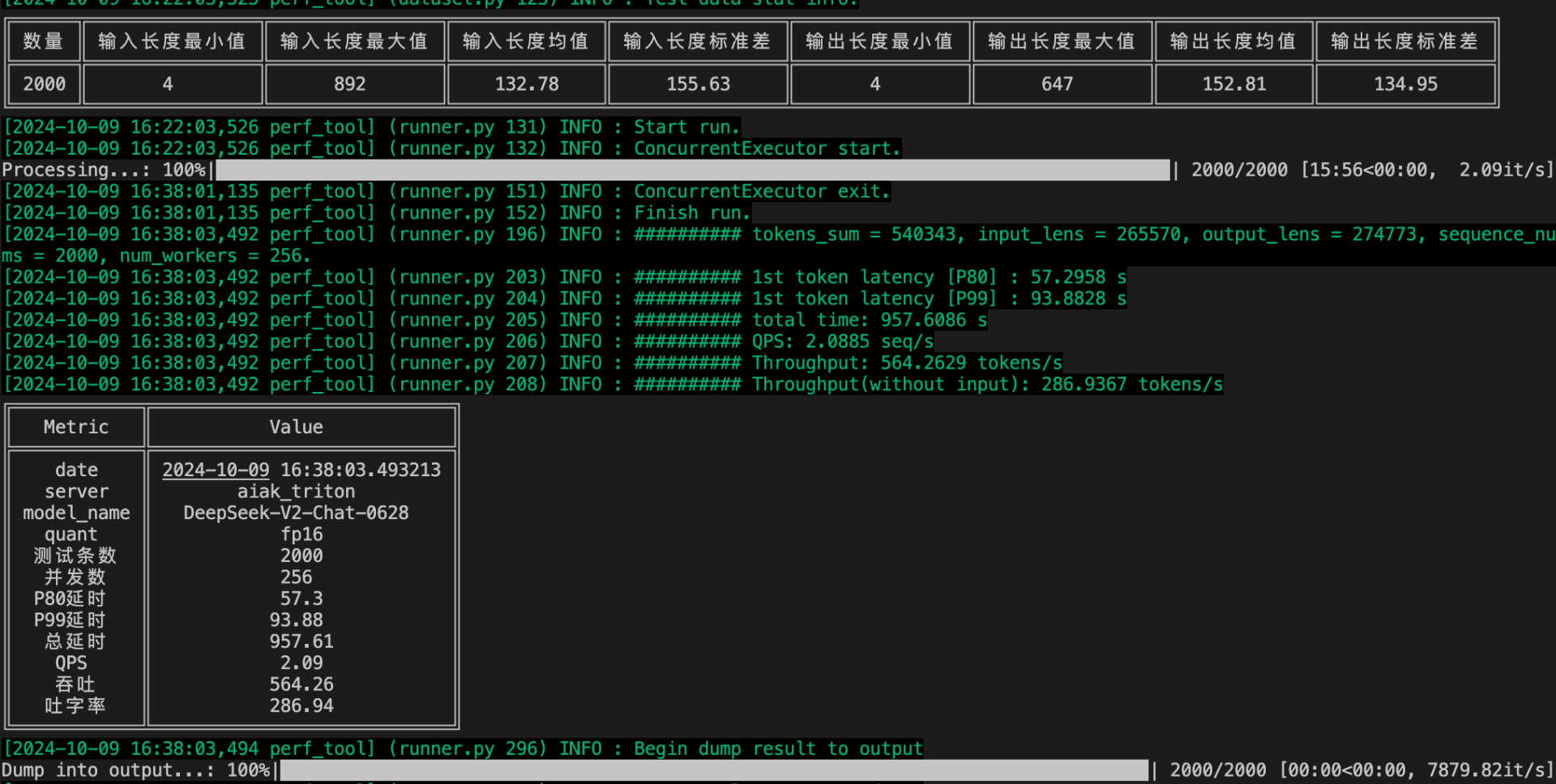
| 特征 | 含义 |
|---|---|
| 数据集包含条数 | 数据集中总样本数量 |
| 输入长度最小值 | 数据集中单条 prompt 长度的最小值 |
| 输入长度最大值 | 数据集中单条 prompt 长度的最大值 |
| 输入长度均值 | 数据集中所有 prompt 长度的平均数 |
| 输入长度标准差 | 数据集中所有 prompt 长度的标准差分布 |
| 输出长度最小值 | 数据集中单条 prompt 生成结果长度的最小值 |
| 输出长度最大值 | 数据集中单条 prompt 生成结果长度的最大值 |
| 输出长度均值 | 数据集中所有 prompt 生成结果长度的平均数 |
| 输出长度标准差 | 数据集中所有 prompt 生成结果长度的标准差分布 |
字段描述:
| 指标 | 含义 | 计算方法 |
|---|---|---|
| quant | 量化精度,具体为 fp16 或 Smoothquant 等 | - |
| 测试条数 | 数据集包含条数 | - |
| 并发数 | 同时响应的请求数量 | - |
| P80 延时 | 首 token 延时,80 分位 | 从输入 prompt 的第一个 token 到生成第一个 token 的时间,取第 80% 的值 |
| P99 延时 | 首 token 延时,99 分位 | 同上,取第 99% 的值 |
| 总延时 | 所有任务处理完成总耗时 | - |
| QPS | 端到端并发量(每秒处理完成几条) | QPS = sequence_nums / total_time |
| 吞吐 | 每秒处理 token 数(包括输入) | Throughput = tokens_sum / total_time |
| 吐字率 | 每秒处理 token 数(不包括输入) | Throughput = output_lens / total_time |
查看的性能指标【输入与输出定长】如下图所示:
============ Serving Benchmark Result ============
Successful requests: 100
Benchmark duration (s): 24.44
Total input tokens: 25600
Total generated tokens: 25600
Request throughput (req/s): 4.09
Input token throughput (tok/s): 1047.38
Output token throughput (tok/s): 1047.38
---------------Time to First Token----------------
Mean TTFT (ms): 5345.94
Median TTFT (ms): 5455.80
P99 TTFT (ms): 5543.46
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 74.84
Median TPOT (ms): 74.38
P99 TPOT (ms): 75.34
---------------Inter-token Latency----------------
Mean ITL (ms): 95.40
Median ITL (ms): 72.77
P99 ITL (ms): 241.22
==================================================
vLLM 官方提供类似的性能压测工具,可参考:vllm-project/benchmarks。
精度测试
大模型推理精度测试是指评估模型在推理阶段(即模型部署后实际使用时)的输出结果是否准确、可靠,是否符合预期目标。 推理精度测试的核心是验证模型在实际应用场景中的表现,确保其输出结果在语义、逻辑和任务目标上与真实值或期望值一致。
主要内容
- 任务相关精度指标:
- 根据模型的具体任务(如分类、生成、问答等),使用相应的指标评估输出结果的准确性。
- 例如:
- 分类任务:准确率(Accuracy)、F1 分数(F1 Score)、AUC-ROC 等。
- 生成任务:BLEU、ROUGE、METEOR、BERTScore 等。
- 问答任务:Exact Match(EM)、F1 分数(F1 Score)。
- 回归任务:均方误差(MSE)、平均绝对误差(MAE)。
- 输出一致性:
- 测试模型在相同输入下是否能够产生一致的输出。
- 例如:多次运行模型,检查输出是否稳定。
- 边界条件测试:
- 测试模型在极端或异常输入下的表现。
- 例如:
- 输入为空或非常短。
- 输入包含噪声、拼写错误或特殊字符。
- 输入超出模型训练数据的分布(OOD,Out-of-Distribution)。
- 语义正确性:
- 评估模型输出是否符合语义逻辑。
- 例如:
- 生成任务中,输出是否流畅、连贯。
- 问答任务中,答案是否与问题相关且正确。
- 上下文理解能力:
- 测试模型是否能够正确理解上下文并生成合理的输出。
- 例如:
- 在多轮对话中,模型是否能够记住上下文并做出合理回应。
- 在长文本生成中,模型是否能够保持逻辑一致性。
- 多样性和创造性:
- 对于生成任务,测试模型输出是否具有多样性,避免重复或模板化。
- 例如:
- 使用 Distinct-N 或 Self-BLEU 评估生成文本的多样性。
- 偏差和公平性:
- 测试模型输出是否存在偏见或不公平现象。
- 例如:
- 检查模型在不同性别、种族、文化背景下的输出是否公平。
- 使用偏差检测工具或人工评估。
测试步骤
- 准备测试数据集:
- 使用真实场景中的数据或构建高质量的测试集。
- 确保测试集覆盖多种场景、边界条件和异常情况。
- 定义评估指标:
- 根据任务类型选择合适的评估指标。
- 例如:分类任务使用准确率,生成任务使用 BLEU 或 ROUGE。
- 运行模型推理:
- 在测试集上运行模型,记录输出结果。
- 计算指标:
- 根据定义的指标计算模型的表现。
- 人工评估(可选):
- 对于生成任务或复杂任务,人工评估输出结果的准确性、流畅性和相关性。
- 分析结果:
- 识别模型的强项和弱项。
- 针对问题提出改进建议。