Deepseek R1 推理资源需求
- 量化与 FP8 动态转换:
- 暂不考虑量化技术;
- FP8 动态转换因性能损失较大,不推荐使用。因此,默认情况下,不具备 FP8 计算单元的显卡无法运行 FP8 模型。
- Deepseek 模型显存需求:
- Deepseek 是原生 FP8 模型,其显存占用约等于参数量(671B 参数约占用 700GB 显存),无需额外乘 2。但运行该模型需要推理设备具备 FP8 计算单元。
- 除模型本身外,还需预留上下文和并发所需的 KV Cache,约 200-300GB。并发需求的 KV Cache 无上限。
- 对于具备 FP8 计算单元的设备,显存需求至少为 1TB;对于仅支持 BF16 的设备(如 A100),模型显存占用将翻倍至 1.4TB,上下文显存需求同样增加,总显存需求约 1.6TB 以上。因此,A100 不推荐用于 Deepseek 推理。
- 硬件性能与互联需求:
- 模型推理对卡间互联带宽要求较低,Fine-tune 阶段亦如此,仅训练阶段对带宽有较高需求。
- GB200 未列入推荐方案,主要因其价格昂贵、货源稀缺且散热设计存在潜在问题。
- 硬件迭代与趋势:
- 显卡迭代速度较快,A100 因缺乏 FP8 计算单元,在 Deepseek 推理场景中已显落后。Blackwell 架构引入原生 FP4 计算单元,若未来出现强开源 FP4 模型,H100/H200 亦可能面临淘汰。
- 模型推理仅依赖特定计算单元,未来可能出现专为推理设计的硬件。
- 配置与成本:
- 所列配置仅能满足基本运行需求,并发性能支持数十人规模,更大规模需进一步扩展硬件配置。
总体而言,Deepseek 推理对硬件要求较高,需投入较大成本,适合具备实力的机构或企业部署。
下面,给大家普及 NVIDIA 基础知识,如硬件类型/厂家、NVIDIA 显卡系列、SXM 与 PCIe、DeepSeek R1 资源需求示例等;
硬件类型/厂家
| 系列 | 纯 CPU 推理 | Nvidia 显卡 | AMD 显卡 | 华为显卡 |
|---|---|---|---|---|
| 优点 | 成本最低 | 性能最好,而且结果可预测 | 价格比 Nvidia 平台稍低,性能良好,官方表明支持 Deepseek 推理 | 硅基流动说他家用华为的卡做的推理,感觉工具链应该是能跑起来 |
| 缺点 | 速度太慢,而且并发性能衰减大 | 价格高 | AMD 驱动等各种工具链还在频繁更新优化性能 | 资料少,很难获得支持,可能要折腾 |
NVIDIA 显卡系列
| 系列 | Pascal | Volta | Turing | Ampere | Ada | Hopper | Blackwell |
|---|---|---|---|---|---|---|---|
| 发布时间 | 2016 | 2017 | 2018 | 2020 | 2022 | 2022 | 2024 |
| 代表卡 | Tesla P40、GeForce GTX 1080 | Tesla V100 | Quadro RTX 6000、RTX 2080 | RTX A6000(现在 GPU)、A100、RTX 3090 | RTX 6000 Ada、L40、RTX 4090 | H100、H200 | B200、RTX 5090 |
SXM 与 PCIe
SXM 和 PCIe 是两种不同的 GPU 接口形式,主要用于连接 GPU 和主机系统。它们在设计、性能、使用场景和支持的硬件平台上有显著区别,SXM 与 PCIe 对比如下所示:
| 特性 | SXM | PCIe |
|---|---|---|
| 接口形式 | 专有接口,模块化设计 | 通用接口,标准 PCIe 插槽 |
| 带宽 | 高(支持 NVLink/NVSwitch) | 受限于 PCIe 版本(如 PCIe 4.0/5.0) |
| 互联性能 | 多 GPU 直接高速通信 | 多 GPU 通过 PCIe 总线通信 |
| 散热和功耗 | 高功耗,需要专用散热 | 功耗较低,散热设计灵活 |
| 使用场景 | 高性能计算、深度学习训练、数据中心 | 消费级、工作站、小型服务器 |
| 硬件兼容性 | 需要专用服务器(如 DGX/HGX) | 兼容大多数 PCIe 主板 |
| 价格 | 较高 | 相对较低 |
| 典型 GPU 型号 | A100 SXM4、H100 SXM5、V100 SXM2 | A100 PCIe、RTX 4090、RTX A6000 |
选择建议:
- 选择 SXM:
- 如果需要极致的性能,并且预算充足,可以选择 SXM 接口的 GPU 和专用服务器(如 DGX);
- 适合大型企业、研究机构或数据中心;
- 选择 PCIe:
- 如果需要灵活的硬件配置、较低的预算,或者主要用于推理、小型训练任务,可以选择 PCIe 接口的 GPU;
- 适合中小型企业、个人开发者或 DIY 用户;
DeepSeek R1 资源需求示例
以下方式列举了 DeepSeek R1 推理的硬件配置方案,仅供参考,具体配置需根据实际需求和预算进行调整。
| 方案 | 建议 | 概述 | 优点 | 缺点 | 总显存 | 电源 | 价格 |
|---|---|---|---|---|---|---|---|
| 双机 A100/A800 PCIe | 不推荐 | 自行购买10卡服务器两台,再单独购买 20 块 A100(甚至感觉都不够) | 1. 没有 fp8 计算单元,最近抛货比较多,价格有所降低; 2. 购买渠道比较灵活方便 | 1. Ampere 这代显卡没有 fp8 计算单元,如果跑不量化的版本,只能跑 scale 上去的 bf16,模型本身占用的显存就要翻倍(大概 1.4T),剩余给上下文和并发的 KV Cache 没多少; 2. 卡已禁售,买到的原则上都是二手,只能依靠经销商保修; 3. A100 架构放现在算比较老的了,两台纯粹是堆显存,就这可能还不太够 | 80G x 20 = 1600GB | 约 10 kW | 200w 左右 |
| 单台 DGX H200 | 最推荐 | 能买到的最新最快的 Nvidia 官方平台 | 1. 有原生 fp8 计算单元,比 A100 架构更新,推理速度快; 2. 单机,不需要考虑双机互联的带宽瓶颈问题; 3. Nvidia 整机方案可靠性比较好 | 1. 货少,价格不透明,可能比较贵; 2. 显卡使用专有接口连接至主板,非 PCIe 接口,不好升级和更换; 3. 一体化程度比较高,又是走私产品,一旦发生意外硬件损坏感觉会比较难修 | 141G x 8 = 1128GB | 约 8 kW | 285w 左右 |
| 单机8卡 H200 SXM | 最推荐 | 最适中的方案 | 1. 周边配置可以选低一点,价格会比 DGX H200 便宜; 2. 单机,不需要考虑双机互联的带宽瓶颈问题 | 1. 卡已禁售,买到的原则上都是二手,只能依靠经销商保修 | 141G x 8 = 1128GB | 约 8 kW | 245w 左右 |
| 双机 H100/H800 SXM/PCIe | 推荐 | 主流方案之一 | 1. 有原生 fp8 计算单元,比 A100 架构更新,推理速度快; 2. 购买渠道比较灵活方便 | 1. 卡已禁售,买到的原则上都是二手,只能依靠经销商保修 | 80G x 16 = 1280GB | 约 10 kW | 大概差不多价格 |
| 国行 H40 SXM 双机 | 不是很推荐 | 好处就是全部都是正规渠道完整保修 | 1. 未禁售,货源可靠,有完整保修; 2. 好购买 | 1. H40 中国特供卡,而且连 Nvidia 官网都没清单; 2. 虽然有 fp8 计算单元,但是性能被砍很多 | 96G x 16 = 1536GB | - | 220w 左右 |
| AMD MI300x 整机 | 一般推荐 | 属于是钱足够的话我是不想用,钱不够的话不是不能用 | 1. 有还算比较稳定货源; 2. 有成功跑起来的案例和测试数据; 3. AMD 官方自己站台了是支持 Deepseek | 1. AMD 的驱动比较草台,可能会有一些驱动导致的上游问题; 2. ROCm 推理 AMD 官方是推荐用 SGLang,SGLang 本身还不是非常成熟,活跃更新中,跑 Deepseek 要不可避免使用测试版本 | 192G x 8 = 1536GB | - | 200w 左右 |
| 华为 910B/910C | 不是很推荐 | 硅基流动说他们用的华为,有成功案例 | - | 1. 资料很少,而且华为自己就不怎么喜欢对外提供资料; 2. 910B 和 C 都不支持 fp8,显存占用也是很大 | - | - | - |
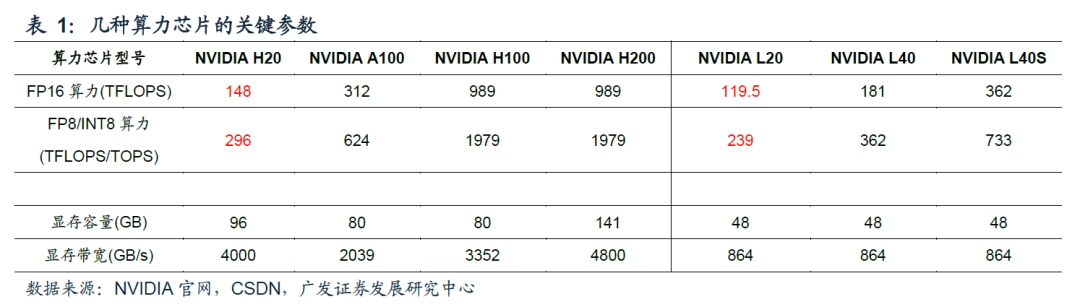
H20(大坑货)
运行示例
- 昇腾 910B 部署满血 DeepSeek-R1(BF16) 可参考华为官网,DeepSeek-R1。
- 单机 8 卡 H200 SXM 配置如下所示:
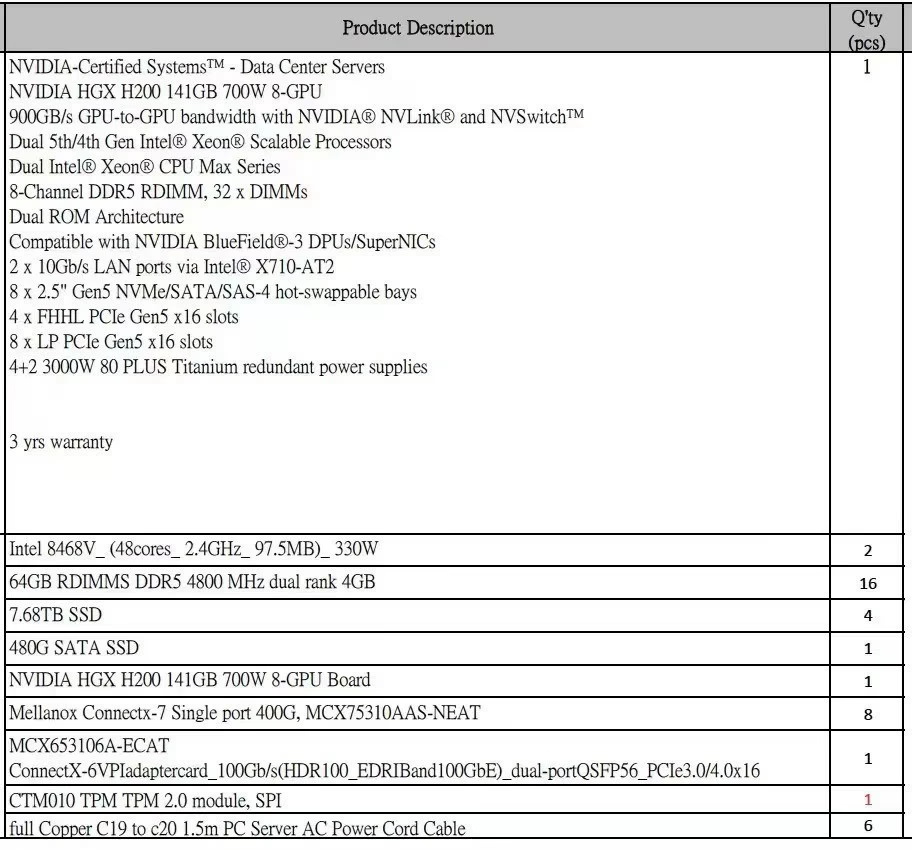
如果跑 DeepSeek 量化模型,那另说,在此不叙述;