测试目标
- 测试下 DeepSeek R1(FP8) 使用单台 H20 机器在 aime、math500、gpqa (使用开源工具 evalscope) 数据集下进行精度测试;
- 给定输入、输出等参数,性能压测,具体可见 benchmark_vllm_060;
环境信息
- 【CPU】lscpu | grep “Model name” Model name: INTEL(R) XEON(R) PLATINUM 8563C
- 【CPU架构】lscpu | grep Architecture Architecture: x86_64
- 【MEM】free -g total: 2015
- 【HDD/SDD】lsblk NVME 3.5T * 4
- 【卡类型】nvidia-smi -q | grep -i “Product Name” H20 * 8
- 【操作系统】cat /etc/os-release CentOS Linux 7 (Core)
- 【内核】uname -r 5.10.0-1.0.0.41
- 【GPU CUDA】nvidia-smi -q | grep -i “Version” 12.2
- 【GPU 驱动】nvidia-smi -q | grep -i “Driver Version” 535.216.03
- 【Docker】docker version 20.10.5
机器配置
H20(8*96G)
[root@xxxx ~]# nvidia-smi
Thu Mar 20 20:47:18 2025
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.216.03 Driver Version: 535.216.03 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA H20 Off | 00000000:22:00.0 Off | 0 |
| N/A 27C P0 75W / 500W | 0MiB / 97871MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 1 NVIDIA H20 Off | 00000000:34:00.0 Off | 0 |
| N/A 27C P0 72W / 500W | 0MiB / 97871MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 2 NVIDIA H20 Off | 00000000:48:00.0 Off | 0 |
| N/A 28C P0 73W / 500W | 0MiB / 97871MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 3 NVIDIA H20 Off | 00000000:5A:00.0 Off | 0 |
| N/A 27C P0 72W / 500W | 0MiB / 97871MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 4 NVIDIA H20 Off | 00000000:9B:00.0 Off | 0 |
| N/A 28C P0 73W / 500W | 0MiB / 97871MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 5 NVIDIA H20 Off | 00000000:AE:00.0 Off | 0 |
| N/A 26C P0 72W / 500W | 0MiB / 97871MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 6 NVIDIA H20 Off | 00000000:C2:00.0 Off | 0 |
| N/A 29C P0 74W / 500W | 0MiB / 97871MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 7 NVIDIA H20 Off | 00000000:D7:00.0 Off | 0 |
| N/A 27C P0 72W / 500W | 0MiB / 97871MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
[root@xxxx ~]# nvidia-smi topo -m
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 NIC0 NIC1 NIC2 NIC3 NIC4 NIC5 NIC6 NIC7 NIC8 CPU Affinity NUMA Affinity GPU NUMA ID
GPU0 X NV18 NV18 NV18 NV18 NV18 NV18 NV18 NODE PIX NODE NODE NODE SYS SYS SYS SYS 0-51,104-155 0 N/A
GPU1 NV18 X NV18 NV18 NV18 NV18 NV18 NV18 NODE NODE PIX NODE NODE SYS SYS SYS SYS 0-51,104-155 0 N/A
GPU2 NV18 NV18 X NV18 NV18 NV18 NV18 NV18 NODE NODE NODE PIX NODE SYS SYS SYS SYS 0-51,104-155 0 N/A
GPU3 NV18 NV18 NV18 X NV18 NV18 NV18 NV18 NODE NODE NODE NODE PIX SYS SYS SYS SYS 0-51,104-155 0 N/A
GPU4 NV18 NV18 NV18 NV18 X NV18 NV18 NV18 SYS SYS SYS SYS SYS PIX NODE NODE NODE 52-103,156-207 1 N/A
GPU5 NV18 NV18 NV18 NV18 NV18 X NV18 NV18 SYS SYS SYS SYS SYS NODE PIX NODE NODE 52-103,156-207 1 N/A
GPU6 NV18 NV18 NV18 NV18 NV18 NV18 X NV18 SYS SYS SYS SYS SYS NODE NODE PIX NODE 52-103,156-207 1 N/A
GPU7 NV18 NV18 NV18 NV18 NV18 NV18 NV18 X SYS SYS SYS SYS SYS NODE NODE NODE PIX 52-103,156-207 1 N/A
NIC0 NODE NODE NODE NODE SYS SYS SYS SYS X NODE NODE NODE NODE SYS SYS SYS SYS
NIC1 PIX NODE NODE NODE SYS SYS SYS SYS NODE X NODE NODE NODE SYS SYS SYS SYS
NIC2 NODE PIX NODE NODE SYS SYS SYS SYS NODE NODE X NODE NODE SYS SYS SYS SYS
NIC3 NODE NODE PIX NODE SYS SYS SYS SYS NODE NODE NODE X NODE SYS SYS SYS SYS
NIC4 NODE NODE NODE PIX SYS SYS SYS SYS NODE NODE NODE NODE X SYS SYS SYS SYS
NIC5 SYS SYS SYS SYS PIX NODE NODE NODE SYS SYS SYS SYS SYS X NODE NODE NODE
NIC6 SYS SYS SYS SYS NODE PIX NODE NODE SYS SYS SYS SYS SYS NODE X NODE NODE
NIC7 SYS SYS SYS SYS NODE NODE PIX NODE SYS SYS SYS SYS SYS NODE NODE X NODE
NIC8 SYS SYS SYS SYS NODE NODE NODE PIX SYS SYS SYS SYS SYS NODE NODE NODE X
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
NIC Legend:
NIC0: mlx5_0
NIC1: mlx5_1
NIC2: mlx5_2
NIC3: mlx5_3
NIC4: mlx5_4
NIC5: mlx5_5
NIC6: mlx5_6
NIC7: mlx5_7
NIC8: mlx5_8
[root@xxx ~]# nvidia-smi nvlink --status -i 0
GPU 0: NVIDIA H20 (UUID: GPU-3c0f23f4-6f23-0feb-28e3-92a276556a6c)
Link 0: 26.562 GB/s
Link 1: 26.562 GB/s
Link 2: 26.562 GB/s
Link 3: 26.562 GB/s
Link 4: 26.562 GB/s
Link 5: 26.562 GB/s
Link 6: 26.562 GB/s
Link 7: 26.562 GB/s
Link 8: 26.562 GB/s
Link 9: 26.562 GB/s
Link 10: 26.562 GB/s
Link 11: 26.562 GB/s
Link 12: 26.562 GB/s
Link 13: 26.562 GB/s
Link 14: 26.562 GB/s
Link 15: 26.562 GB/s
Link 16: 26.562 GB/s
Link 17: 26.562 GB/s
⚠️ 注意:模型文件可能分为多个部分,一定要验证所有文件的完整性,避免因文件损坏导致的启动失败
下载权重
从 DeepSeek-R1 下载 DeepSeek-R1 FP8 模型文件;
下载镜像
lmsysorg/sglang:latest
测试过程
vLLM 在通用场景下表现更稳定,而SGLang在批处理场景下吞吐量略高;
运行 SGlang
docker run -itd --gpus all --shm-size 32g -p 30000:30000 -v $PWD:/workspace --ipc=host --network=host --privileged ccr-25mlx515-pub.cnc.bj.baidubce.com/cce-private/lmsysorg-sglang-latest:ea52b45be1a7 bash
运行 DeepSeek-R1 模型服务
python3 -m sglang.launch_server --model-path /workspace/DeepSeek-R1 --served-model-name DeepSeek-R1 --tp 8 --trust-remote-code --host 0.0.0.0 --port 30000 --mem-fraction-static 0.95 --max-running-requests 32 --context-length 65536 --quantization fp8 --chunked-prefill-size 4096
参考官方测试命令,启动失败,需要改成上述命令;
精度测试
gpqa
启动测试:
evalscope eval \
--model DeepSeek-R1 \
--api-url http://127.0.0.1:30000/v1 \
--api-key EMPTY \
--eval-type service \
--datasets gpqa \
--dataset-args '{"gpqa": {"local_path": "/workspace/datasets/gpqa/", "metrics_list": ["Pass@1"], "subset_list": ["gpqa_diamond"], "few_shot_num": 0}}' \
--generation-config max_tokens=20480,temperature=0.0 \
--eval-batch-size 30 \
--timeout 10000000
测试结果:
2025-03-17 02:51:28,364 - evalscope - INFO - Use default settings: > few_shot_num: 0, > few_shot_split: None, > target_eval_split: train
Predicting(gpqa_diamond): 1%| | 1/198 [02:05<6:52:52, 125.75s/it]
Predicting(gpqa_diamond): 3%|▎ | 5/198 [03:00<1:09:46, 21.69s/it]
Predicting(gpqa_diamond): 30%|███ | 60/198 [22:07<53:55, 23.45s/it]
Predicting(gpqa_diamond): 49%|████▉ | 97/198 [36:52<29:39, 17.61s/it]
Predicting(gpqa_diamond): 75%|███████▌ | 149/198 [59:19<19:43, 24.15s/it]
Predicting(gpqa_diamond): 94%|█████████▍| 187/198 [1:13:54<05:27, 29.77s/it]
Predicting(gpqa_diamond): 99%|█████████▉| 197/198 [1:22:03<00:58, 58.33s/it]
Predicting(gpqa_diamond): 100%|██████████| 198/198 [1:23:36<00:00, 25.34s/it]
2025-03-17 04:15:05,223 - evalscope - INFO - Dump predictions to ./outputs/20250317_025127/predictions/DeepSeek-R1/gpqa_gpqa_diamond.jsonl.
Reviewing(gpqa_diamond): 100%|██████████| 198/198 [00:00<00:00, 1092.30it/s]
2025-03-17 04:15:05,438 - evalscope - INFO - Dump report: ./outputs/20250317_025127/reports/DeepSeek-R1/gpqa.json
2025-03-17 04:15:05,441 - evalscope - INFO - Report table:
+-------------+-----------+---------------+--------------+-------+---------+---------+
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
+=============+===========+===============+==============+=======+=========+=========+
| DeepSeek-R1 | gpqa | AveragePass@1 | gpqa_diamond | 198 | 0.702 | default |
+-------------+-----------+---------------+--------------+-------+---------+---------+
2025-03-17 04:15:05,441 - evalscope - INFO - **** Evaluation finished on /workspace/datasets/gpqa/ ****
aime24
启动测试:
python3 -u math_eval_h20.py \
--tokenzier_dir /workspace/DeepSeek-R1 \
--model_name_or_path /workspace/DeepSeek-R1 \
--data_name aime24 \
--output_dir /workspace/h20-output/ \
--split test \
--prompt_type deepseek-math \
--num_test_sample -1 \
--max_tokens_per_call 20480 \
--seed 0 \
--temperature 0 \
--n_sampling 1 \
--top_p 1 \
--start 0 \
--end -1 \
--use_openai \
--save_outputs \
--apply_chat_template
测试结果:
100%|██████████| 28/28 [00:00<00:00, 457.67it/s]
-------------------- Epoch 0
Saved to /workspace/h20-output//1742186525.2899108/raw_result.jsonl
-------------------- Epoch 1
Unsolved samples: 0
Evaluate: 100%|██████████| 30/30 [00:00<00:00, 134.13it/s]
{'num_samples': 30, 'num_scores': 30, 'timeout_samples': 0, 'empty_samples': 0, 'acc': 83.3}
Saved to /workspace/h20-output/aime24/test_deepseek-math_-1_seed0_t0.0_s0_e-1.jsonl
aime24 avg
83.3 83.3
math500
启动测试:
python3 -u math_eval_h20.py \
--tokenzier_dir /workspace/DeepSeek-R1 \
--model_name_or_path /workspace/DeepSeek-R1 \
--data_name math500 \
--output_dir /workspace/h20-output-math500/ \
--split test \
--prompt_type deepseek-math \
--num_test_sample -1 \
--max_tokens_per_call 20480 \
--seed 0 \
--temperature 0 \
--n_sampling 1 \
--top_p 1 \
--start 0 \
--end -1 \
--use_openai \
--save_outputs \
--apply_chat_template
测试结果:
Assistant:
100%|██████████| 500/500 [00:01<00:00, 328.63it/s]
-------------------- Epoch 0
Saved to /workspace/h20-output-math500//1742190683.1334848/raw_result.jsonl
-------------------- Epoch 1
Unsolved samples: 0
Evaluate: 100%|██████████| 500/500 [00:00<00:00, 731.59it/s]
{'num_samples': 500, 'num_scores': 500, 'timeout_samples': 0, 'empty_samples': 1, 'acc': 96.0}
Saved to /workspace/h20-output-math500//math500/test_deepseek-math_-1_seed0_t0.0_s0_e-1.jsonl
math500 avg
96.0 96.0
性能测试
运行 SGlang
docker run -itd --gpus all --shm-size 32g -p 30000:30000 -v $PWD:/workspace --ipc=host --network=host --privileged ccr-25mlx515-pub.cnc.bj.baidubce.com/cce-private/lmsysorg-sglang-latest:ea52b45be1a7 bash
运行 DeepSeek-R1 模型服务
python3 -m sglang.launch_server --model-path /workspace/DeepSeek-R1 --served-model-name DeepSeek-R1 --tp 8 --trust-remote-code --host 0.0.0.0 --port 30000 --mem-fraction-static 0.95 --max-running-requests 32 --context-length 65536 --quantization fp8 --chunked-prefill-size 4096
参考官方测试命令,启动失败,需要改成上述命令;
下载 ShareGPT_V3_unfiltered_cleaned_split:
wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
性能测试示例如下所示:
python3 -m sglang.bench_serving \
--backend sglang \
--dataset-name random \
--dataset-path /workspace/datasets/ShareGPT_V3_unfiltered_cleaned_split.json \
--model /workspace/DeepSeek-R1 \
--random-input 5600 \
--random-output 1400 \
--random-range-ratio 0.8 \
--num-prompts 1 \
--host 0.0.0.0 \
--port 30000 \
--output-file "deepseekr1_1.json" \
--max-concurrency 1
sglang 性能测试响应数据示例如下所示:
{
"backend": "sglang",
"dataset_name": "random",
"request_rate": "Infinity",
"max_concurrency": 128,
"sharegpt_output_len": null,
"random_input_len": 3500,
"random_output_len": 1500,
"random_range_ratio": 0.7,
"duration": 577.2790666338988,
"completed": 128,
"total_input_tokens": 384124,
"total_output_tokens": 161427,
"total_output_tokens_retokenized": 160882,
"request_throughput": 0.22172984852259603,
"input_throughput": 665.4043463585444,
"output_throughput": 279.6342520113837,
"mean_e2e_latency_ms": 356288.1459405144,
"median_e2e_latency_ms": 383529.29322898854,
"std_e2e_latency_ms": 149932.69563592484,
"p99_e2e_latency_ms": 576120.2690516319,
"mean_ttft_ms": 220795.97218007257,
"median_ttft_ms": 219905.09079105686,
"std_ttft_ms": 155288.4408328424,
"p99_ttft_ms": 461669.7295173723,
"mean_tpot_ms": 107.60915398548093,
"median_tpot_ms": 107.54734916891869,
"std_tpot_ms": 28.123959275677496,
"p99_tpot_ms": 119.76204162723829,
"mean_itl_ms": 107.5221331570835,
"median_itl_ms": 91.4815510623157,
"std_itl_ms": 970.5097010946142,
"p95_itl_ms": 93.53254092857242,
"p99_itl_ms": 737.1417707297951,
"concurrency": 78.99971662978685,
"accept_length": null
}
测试脚本,如下所示:
#!/usr/bin/bash
all_length=(
"3500 1500"
"3000 400"
)
prompt_num=(1 4 8 16 32 64 80 128 256 350 512)
random_range_ratios=(0.7 0.8)
for length in "${all_length[@]}"
do
for i in "${prompt_num[@]}"
do
input_len=$(echo $length | cut -d' ' -f1)
output_len=$(echo $length | cut -d' ' -f2)
for ratio in "${random_range_ratios[@]}"
do
python3 -m sglang.bench_serving \
--backend sglang \
--dataset-name random \
--dataset-path /workspace/datasets/ShareGPT_V3_unfiltered_cleaned_split.json \
--model /workspace/DeepSeek-R1 \
--random-input ${input_len} \
--random-output ${output_len} \
--random-range-ratio ${ratio} \
--num-prompts ${i} \
--host 0.0.0.0 \
--port 30000 \
--output-file "tp${i}_in${input_len}_out${output_len}_ratio${ratio}.json" \
--max-concurrency ${i}
done
done
done
收集测试结果:
import json
import os
import csv
import re
import argparse
fieldnames = ["prompt_num", "concurrency", "random_input_len", "random_output_len", "total_input_tokens", "total_output_tokens", "duration", "request_throughput", "mean_e2e_latency_ms", "median_e2e_latency_ms", "std_e2e_latency_ms", "p99_e2e_latency_ms", "mean_ttft_ms", "median_ttft_ms", "p99_ttft_ms", "mean_tpot_ms", "median_tpot_ms", "p99_tpot_ms", "mean_itl_ms", "median_itl_ms", "p99_itl_ms", "input_output_throughput(tok/s)" ,"input_throughput(tok/s)", "output_throughput(tok/s)"]
def main(args):
data = []
for _, _, files in os.walk(args.dir):
for file in files:
pattern = r'tp(\d+)_in(\d+)_out(\d+)_ratio([\d.]+)\.json'
match = re.match(pattern, file)
if match:
#print(match.group(0), match.group(1), match.group(2), match.group(3), match.group(4))
prompt_num = int(match.group(1))
con = int(match.group(1))
input_length = int(match.group(2))
output_length = int(match.group(3))
else:
print(f"File {file} does not match the pattern")
continue
with open(os.path.join(args.dir, file), 'r') as f:
result = json.load(f)
data.append(
{
"prompt_num": prompt_num,
"concurrency": con,
"random_input_len": result['random_input_len'],
"random_output_len": result['random_output_len'],
"total_input_tokens": result['total_input_tokens'],
"total_output_tokens": result['total_output_tokens'],
"duration": result['duration'],
"request_throughput": result['request_throughput'],
"mean_e2e_latency_ms": result['mean_e2e_latency_ms'],
"median_e2e_latency_ms": result['median_e2e_latency_ms'],
"std_e2e_latency_ms": result['std_e2e_latency_ms'],
"p99_e2e_latency_ms": result['p99_e2e_latency_ms'],
"mean_ttft_ms": result['mean_ttft_ms'],
"median_ttft_ms": result['median_ttft_ms'],
"p99_ttft_ms": result['p99_ttft_ms'],
"mean_tpot_ms": result['mean_tpot_ms'],
"median_tpot_ms": result['median_tpot_ms'],
"p99_tpot_ms": result['p99_tpot_ms'],
"mean_itl_ms": result['mean_itl_ms'],
"median_itl_ms": result['median_itl_ms'],
"p99_itl_ms": result['p99_itl_ms'],
"input_output_throughput(tok/s)": result['input_throughput'] + result['output_throughput'],
"input_throughput(tok/s)": result['input_throughput'],
"output_throughput(tok/s)": result['output_throughput'],
}
)
data.sort(key=lambda x: x["concurrency"])
output_file = os.path.join(args.dir, 'summary.csv')
with open(output_file, 'w', newline='') as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(data)
print(f"CSV file saved to {output_file}")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--dir", type=str, help="Directory containing JSON result files")
args = parser.parse_args()
main(args)
测试结果
DeepSeek R1 FP8 + 单机 H20
DeepSeek R1 FP8 + 单机 H20 精度测试结果如下所示:
aime24 83.3
math500 96.0
gpqa:70.2
DeepSeek R1 FP8 + 单机 H20 性能测试结果如下所示:
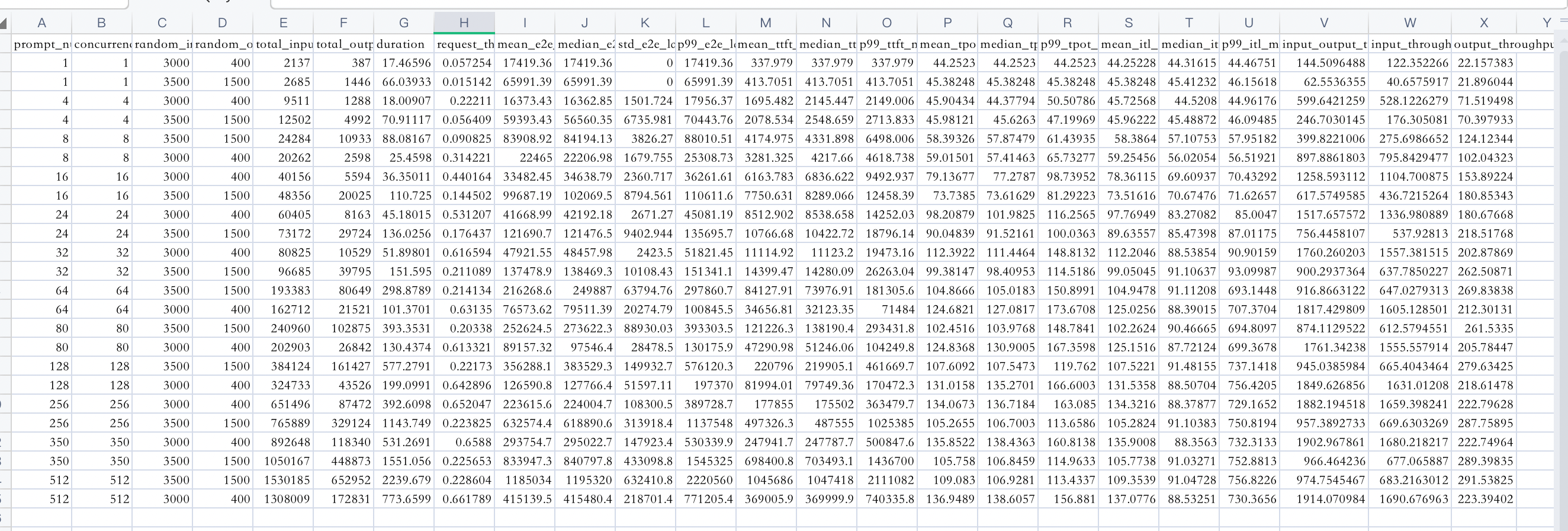
random-range-ratio 等于 0.7 的测试结果:
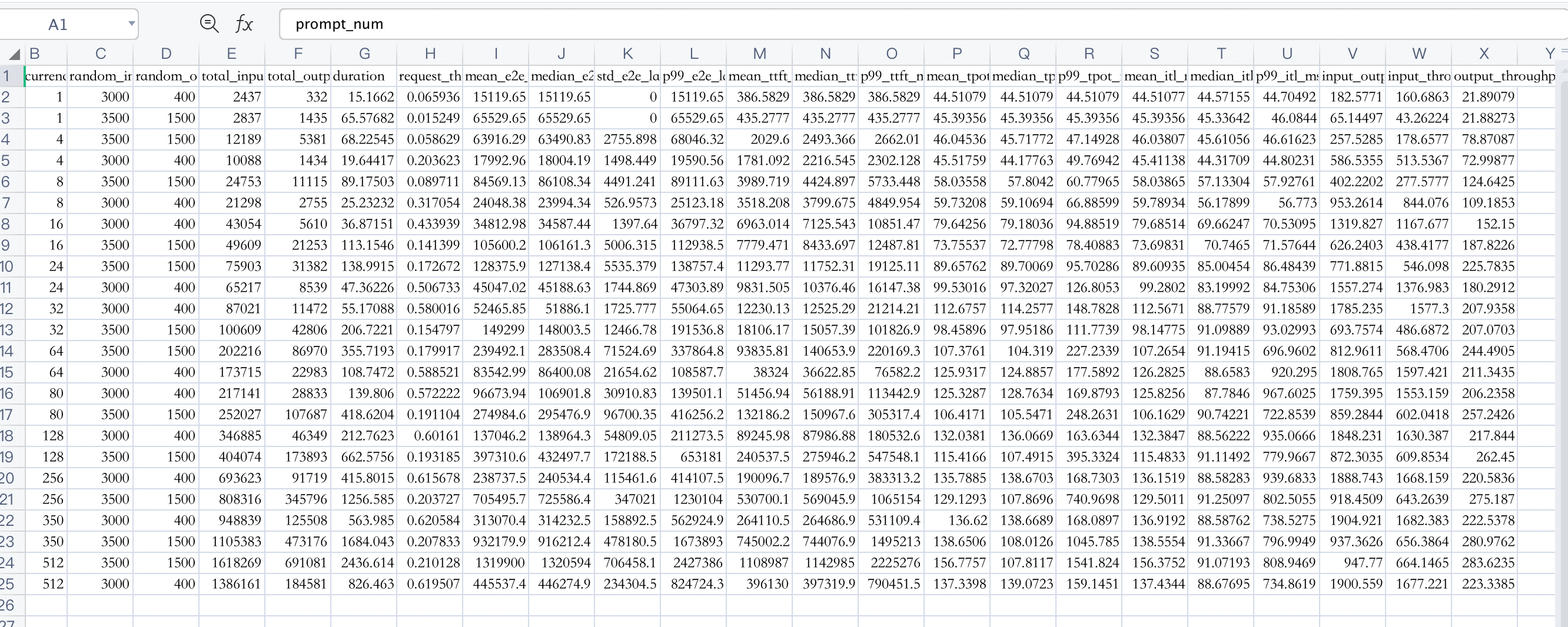
random-range-ratio 等于 0.8 的测试结果:
DeepSeek-R1-Block-INT8 + 单机 H20
同理按照上述操作,测试下 DeepSeek-R1-Block-INT8 + 单机 H20 的性能。
DeepSeek-R1-Block-INT8 + 单机 H20 精度测试结果如下所示:
aime24 0.702
math500 95.6
gpqa:76.7
DeepSeek-R1-Block-INT8 + 单机 H20 性能测试结果如下所示:
random-range-ratio 等于 0.7 的测试结果: