1. DeepSeek 开源周
DeepSeek 在开源了 DeepSeek-R1 与 DeepSeek-V3 模型权重后,DeepSeek-V3 技术报告 《DeepSeek-V3 Technical Report》 中提到的很多核心技术,相继在 “DeepSeek 开源周” (2025.02.24-03.01)中亮相。
| 天数 | 项目名称 | 核心功能 | 性能指标 |
|---|---|---|---|
| Day 1 | FlashMLA | 高效的 MLA 解码内核,优化变长序列处理 | ✅ 3000 GB/s 内存带宽 ✅ 580 TFLOPS (BF16, H800 GPU) |
| Day 2 | DeepEP | 首个开源 EP 通信库,支持 MoE 模型训练/推理 | ✅ 支持 NVLink/RDMA ✅ FP8 原生调度 ✅ 低延迟推理优化 |
| Day 3 | DeepGEMM | FP8 GEMM 库,支持密集/MoE 矩阵计算 | ✅ 1350+ FP8 TFLOPS (Hopper 架构) ✅ 核心代码仅 300 行 |
| Day 4 | 并行策略优化 | • DualPipe: 双向流水线并行 • EPLB: MoE 负载均衡器 | ✅ 优化 V3/R1 训练中的计算-通信重叠 |
| Day 5 | 3FS(源神文件系统) | 高性能并行文件系统,支持 AI 训练/推理存储加速 | ✅ 6.6 TiB/s 聚合读取(180 节点) ✅ 40+ GiB/s 单客户端 KVCache 吞吐 |
| Day 6 | DeepSeek-V3/R1 推理系统 | • EP 跨节点扩展 • 计算-通信重叠 • 负载均衡 | ✅ 73.7k tokens/s 输入 ✅ 14.8k tokens/s 输出(H800) ✅ 成本利润率高达 545% |
DeepSeek 开源周地址:https://github.com/deepseek-ai/open-infra-index 。
在2025年2月24日至28日的DeepSeek开源周期间,DeepSeek集中发布了五大核心开源项目,全面覆盖AI基础设施中的计算优化、通信效率与存储加速等关键领域,构建起一套面向大规模人工智能的高性能技术底座。
- FlashMLA:专为NVIDIA Hopper架构GPU优化的多头线性注意力解码内核,显著提升推理效率,支持实时翻译与超长文本处理,大幅降低延迟。
- DeepEP:面向混合专家模型(MoE)设计的高性能通信库,通过智能调度与高效数据分发机制,显著缓解节点间通信瓶颈,加速模型训练。
- DeepGEMM:基于FP8精度的高效矩阵乘法库,针对MoE模型中的稀疏计算特性进行深度优化,极大提升了大规模矩阵运算的吞吐能力。
- DualPipe & EPLB:创新的双向流水线并行算法结合动态负载均衡工具,有效提升硬件利用率,显著改善分布式训练的效率与稳定性。
- 3FS & Smallpond:高性能分布式文件系统,支持RDMA网络与SSD存储架构,实现海量训练数据的高速读写与统一管理,夯实AI训练的数据基础。
这五大项目协同作用,从显存利用、通信瓶颈、核心算子、并行策略到数据存储,系统性地解决了大模型训练与推理中的关键挑战,共同构筑了面向下一代AI的高性能基础设施。此次开源不仅是技术成果的集中展示,更体现了DeepSeek在AI底层创新上的深厚积累。更重要的是,它彰显了一种开放、共享的技术价值观。通过将这些核心技术向全球开发者开放,DeepSeek显著降低了AI研发的门槛,让更多研究者和开发者能够站在巨人的肩膀上进行创新。
DeepSeek的开源实践证明:通过算法创新与硬件级优化的深度结合,大模型推理效率可实现量级跃迁。这种"软硬协同"的技术路线,正在重塑AI基础设施的竞争格局。
2. Day 1 - FlashMLA

- 适用于 Hopper GPU 的高效 MLA 解码内核
- 针对可变长度序列进行了优化,在生产中经过实战测试
- 🔗 FlashMLA GitHub 存储库 FlashMLA GitHub Repo
- ✅ BF16 支持
- ✅ 分页 KV 缓存(块大小 64)
- ⚡ 性能:3000 GB/s 内存受限 | H800 上的 BF16 580 TFLOPS 计算绑定
FlashMLA通过一系列创新的优化措施,显著提升了NVIDIA Hopper GPU在处理可变长序列时的性能和效率。其分页KV缓存管理、异步内存拷贝和双模式执行引擎等特性,不仅提高了显存利用率和内存带宽,还降低了整体延迟。与传统的MHA机制相比,FlashMLA通过低秩压缩和旋转位置编码等技术,减少了内存访问开销,同时提升了模型对长距离依赖关系的捕捉能力,这些优化使得FlashMLA在处理大规模语言模型推理任务时表现出色,特别是在长对话和文档分析等场景中。
FlashMLA与其他相近计算方法对比如下所示:
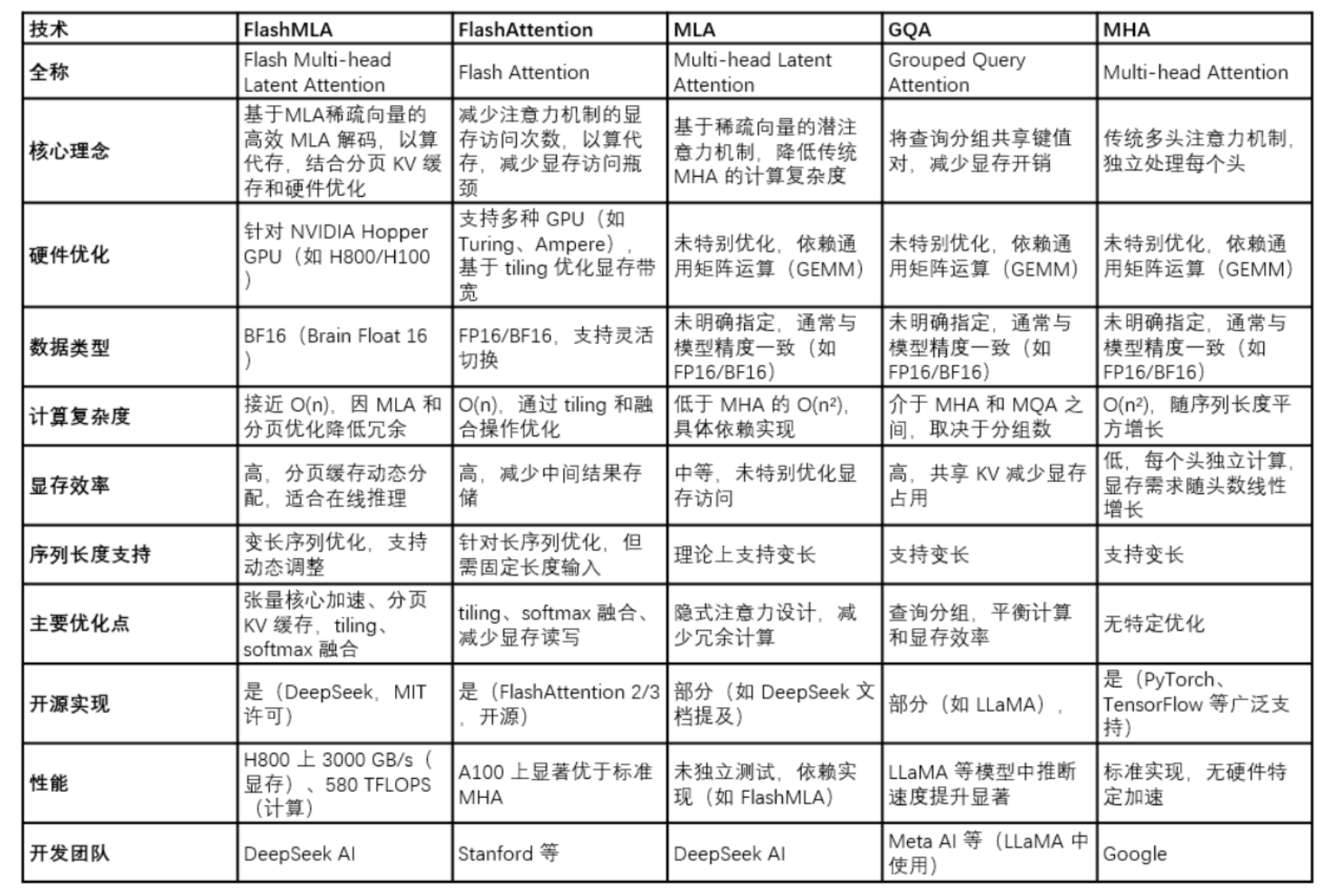
FlashMLA 是 DeepSeek 团队在 AI 性能优化领域的重要成果,实现了在英伟达 Hopper 架构 GPU 的高效 Inference。其价值在于:
- 1)通过开源鼓励开发者优化或适配其他硬件(如 AMD GPU 和其他 AI 芯片)。
- 2)鼓励开发者实现与现有加速框架(如 vLLM、SGLang 等)的集成。
3. Day 2 - DeepEP

- 很高兴推出 DeepEP - 第一个用于 MoE 模型训练和推理的开源 EP 通信库。
- 🔗 DeepEP GitHub 存储库 DeepEP GitHub Repo
- ✅ 高效和优化的 all-to-all 通信
- ✅ NVLink 和 RDMA 的节点内和节点间支持
- ✅ 用于训练和推理预填充的高吞吐量内核
- ✅ 用于推理解码的低延迟内核
- ✅ 原生 FP8 调度支持
- ✅ 灵活的 GPU 资源控制,用于计算通信重叠
DeepEP 是由 deepseek-ai (深度求索)开发的一个开源项目。DeepEP 针对混合专家(MoE)+ 专家并行(EP)模型架构设计的通信库。MoE 是由多个专家子网络组成的大模型,通过门控网络决定输入分配给哪个专家。
DeepEP 提供高吞吐量和低延迟的 all-to-all GPU 内核,包括 MoE 分发(dispatch)和合并(combine)。该库支持 FP8 等低精度运算,特别适用于 DeepSeek 系列模型(如 DeepSeek-V2、V3 和 R1)。
DeepEP 具备以下关键技术:
- 1)高吞吐量、低延迟的 all-to-all GPU 内核,专门优化的分派和组合操作。确保数据在多个 GPU 之间快速传输,减少通信时间。
- 2)支持低比特操作,如 FP8 格式,显著降低计算和存储需求,提升整体效率。
- 3)针对非对称域带宽转发(如从 NVLink 域到 RDMA 域),提供优化内核,适合训练和推理 Prefill 任务。允许直接内存访问,减少 CPU 介入。DeepEP 的优化确保数据在不同域之间高效传输,特别适用于大规模混合卡的分布式训练。
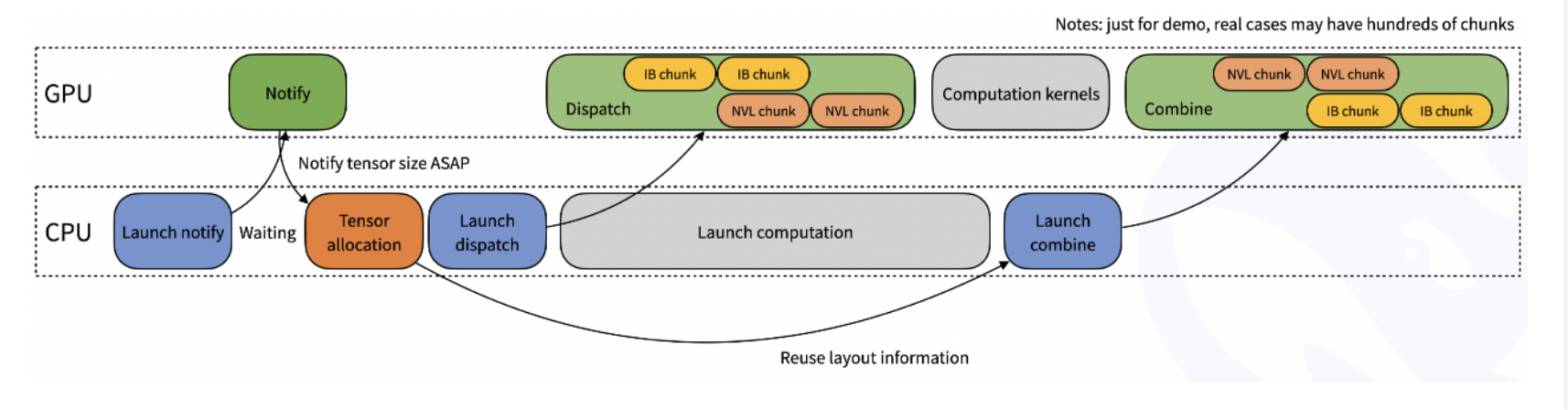
DeepEP通过高效的通信内核和优化策略,显著提升了MoE架构在分布式训练和推理任务中的性能。 其异构带宽优化、低延迟内核和通信-计算重叠机制,使其在大规模分布式环境中表现出色。 未来,随着硬件和网络技术的不断发展,DeepEP有望在更多领域发挥重要作用。
4. Day 3 - DeepGEMM

- DeepGEMM 简介 - 一个 FP8 GEMM 库,支持密集 GEMM 和 MoE GEMM,为 V3/R1 训练和推理提供支持。
- 🔗 DeepGEMM GitHub 存储库 DeepGEMM GitHub Repo
- ⚡ 在 Hopper GPU 上高达 1350+ FP8 TFLOPS
- ✅ 没有繁重的依赖,像教程一样干净
- ✅ 完全 Just-In-Time 编译
- ✅ ~300 行的核心逻辑 - 但在大多数矩阵大小中都优于专家调优的内核
- ✅ 支持密集布局和两种 MoE 布局
DeepGEMM 是一个专为 NVIDIA Hopper 架构设计的高效 FP8 矩阵乘法库,支持普通和混合专家模型(MoE)分组矩阵乘法,通过简洁的实现和即时编译技术,实现了高性能和易用性。官方开源代码链接:https://github.com/deepseek-ai/DeepGEMM。
核心亮点:
- FP8 低精度支持:DeepGEMM 最大的特色在于从架构上优先设计为 FP8 服务。传统GEMM库主要优化FP16和FP32,而DeepGEMM针对FP8的特殊性进行了优化设计。
- 极致性能与极简核心实现:DeepGEMM在NVIDIA Hopper GPU上实现了高达1350+ FP8 TFLOPS的计算性能,同时其核心代码仅有约300行
- JIT 即时编译:DeepGEMM 不是预先编译好所有可能配置的内核,而是利用 JIT 在运行时生成最佳内核。例如,根据矩阵大小、FP8尺度等参数,JIT 会即时优化指令顺序和寄存器分配。
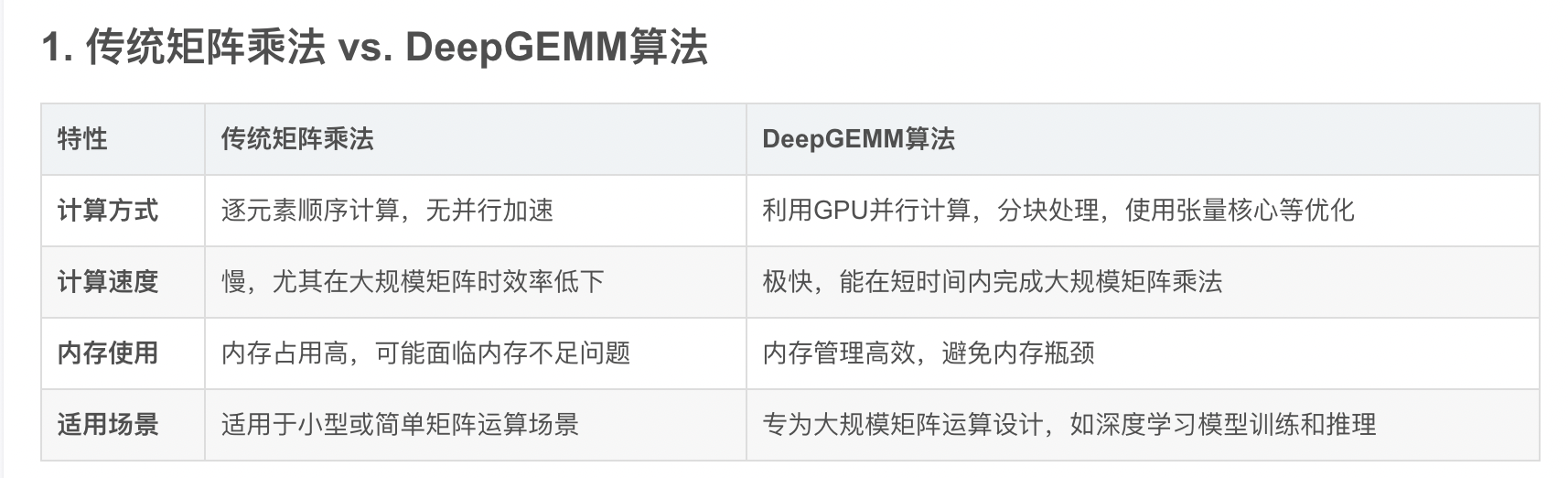
DeepGEMM 通过利用GPU的并行计算能力、优化内存访问模式以及采用先进的硬件特性,实现了矩阵乘法的高效计算。 它不仅在性能上达到了极致,还通过简洁的代码结构和即时编译技术提供了高度的灵活性和适用性。
一切都是为了从硬件中榨干每一滴性能。
5. Day 4 - Optimized Parallelism Strategies

- ✅ DualPipe - 一种双向管道并行算法,用于 V3/R1 训练中的计算通信重叠。
- 🔗 GitHub 存储库 GitHub Repo
- ✅ EPLB - 适用于 V3/R1 的专家并行负载均衡器。
- 🔗 GitHub 存储库 GitHub Repo
- 📊 分析 V3/R1 中的计算通信重叠。
- 🔗 GitHub 存储库 GitHub Repo
在大规模语言模型(LLM)的训练中,高效利用计算资源、降低通信开销以及维持负载均衡是亟待解决的关键问题。尤其在面对超大规模模型和海量数据时,传统训练方法往往难以应对。DeepSeek 团队在这一领域取得了突破性进展,其中 DualPipe 和 EPLB 作为两项核心技术,为优化大规模模型训练提供了创新解决方案。
- DualPipe 是一种创新的双向流水线并行算法。 它通过在流水线的两端同时注入微批次,实现了前向和反向传播的完全重叠,从而大幅减少了流水线空闲时间(Pipeline Bubble),显著提高了计算资源的利用率。
- EPLB(Expert Parallelism Load Balancer)则是一种专家并行负载均衡算法。 通过冗余专家策略和分组限制专家路由,优化了专家并行(EP)中的负载分配,确保不同 GPU 之间的负载均衡,提高训练效率。
- 训练和推理框架的分析数据:为了帮助社区更好地理解通信 - 计算重叠策略和底层实现细节。
DualPipe 负责提升通信效率,确保信道均衡;EPLB 则负责优化专家副本分配,确保不同 GPU 节点的负载均衡。相对前两天的 FlashMLA 和 DeepGEMM,DualPipe 与 EPLB 更多偏向于工程优化。当然这两者的工程优化也不是大部分团队可以做的。需要对信道优化和推断集群部署有很强的软硬件综合优化能力。
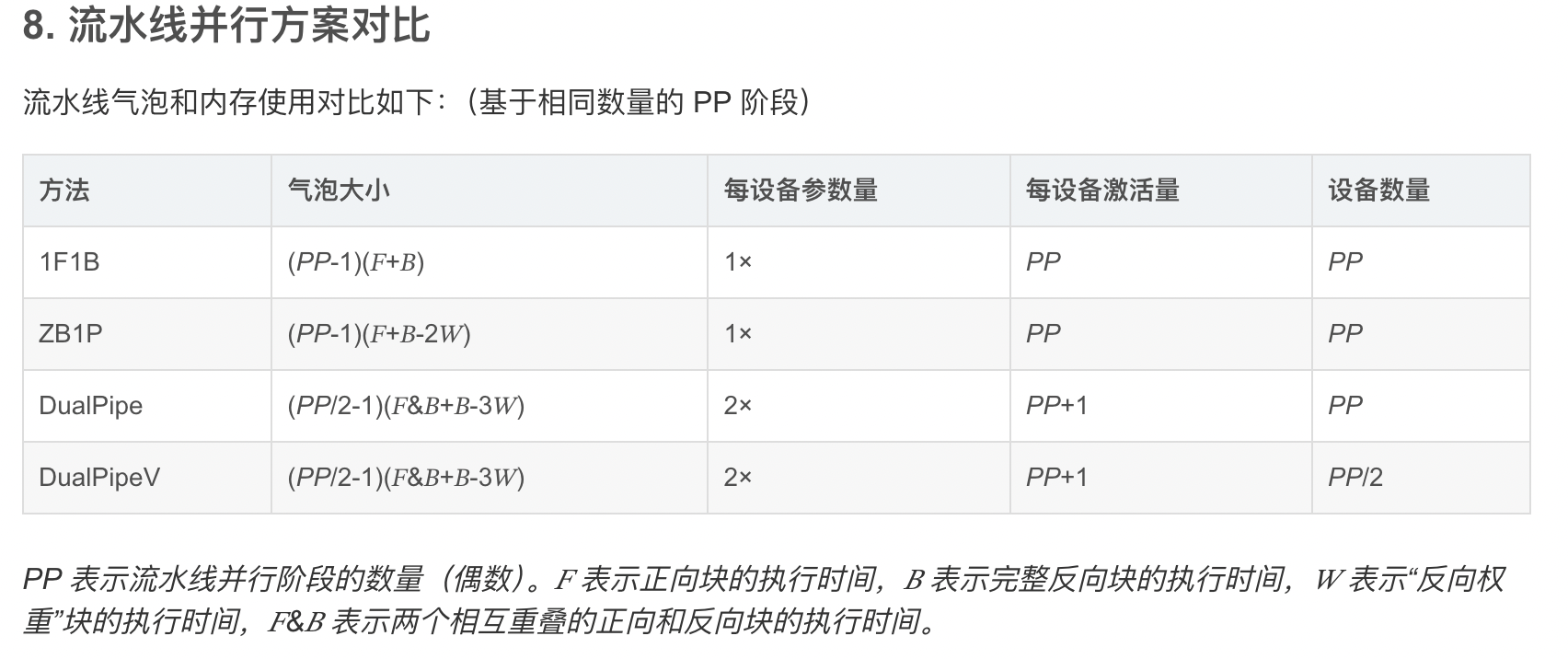
DualPipe 的架构基于 Transformer 框架,并针对流水线并行进行了深度优化。其在ZB-PP划分粒度的基础上,DualPipe做了针对前向传播与后向传播都需要计算的情况,做了更细致的拆分。
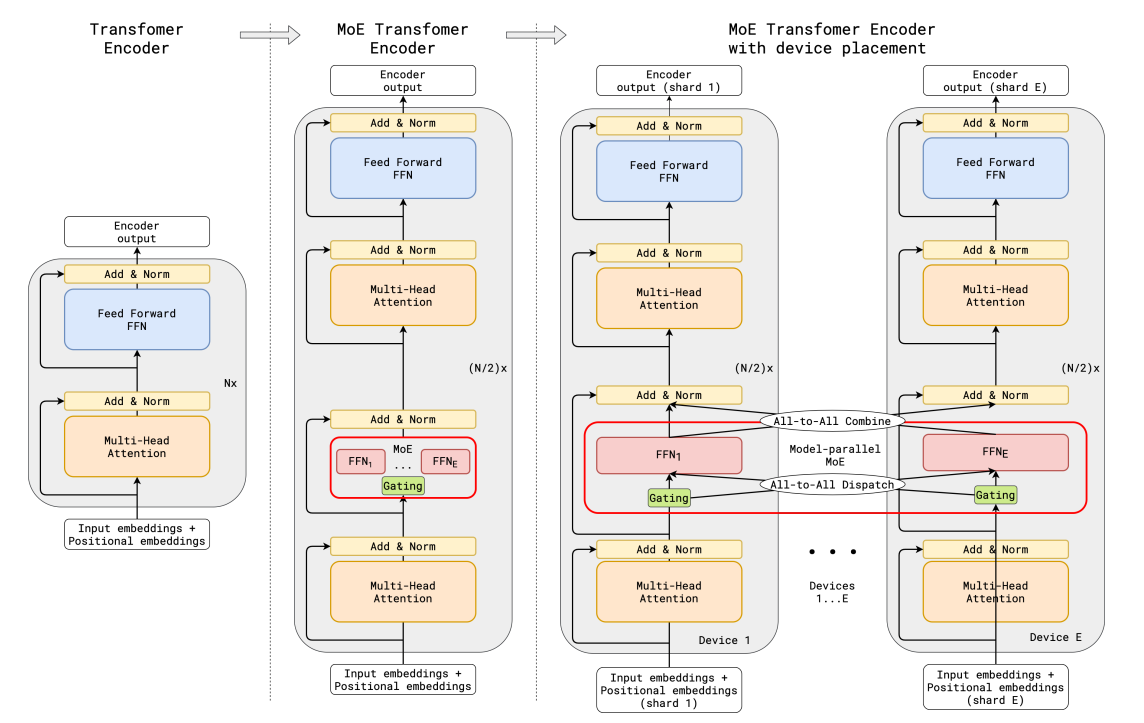
DualPipe的核心思想是在一对单独的前向和反向块中重叠计算和通信。具体来说,每个计算块被划分为四个部分:Attention、All-to-All Dispatch、MLP 和 All-to-All Combine。对于后向传播块,Attention 和 MLP 进一步细分为输入梯度计算(Backward for Input)和权重梯度计算(Backward for Weights)。

如上图所示,对于一对前向和反向块,DualPipe 通过重新排列这些组件,并手动调整专用于通信与计算的GPU SM(Streaming Multiprocessors)的比例,可以确保在执行过程中,全对全和PP通信都可以完全隐藏。

完整的DualPipe调度如图所示。它采用双向流水线调度,同时从流水线的两端输入微批次,并且可以完全重叠大量的通信。这种重叠还确保了随着模型进一步扩展,只要保持恒定的计算与通信比,仍然可以在节点间使用细粒度的专家,并实现接近零的全对全通信开销。
DualPipe 优势:
- DualPipe的流水线气泡更少,信道使用效率更高
- DualPipe将前向和后向传播中的计算和通信重叠解决了跨节点专家并行(EP)带来的繁重通信开销问题
- 在确保计算与通信比例恒定的情况下,具有很好的Scale-out能力
DualPipeV:
- DualPipeV 是由 DualPipe 通过“一分为二”的方法推导出的一种简洁的 V 形调度。如下图所示:

专家并行(Expert Parallelism,EP) 是一种在混合专家模型(Mixture of Experts,MoE)中采用的训练方法。它将模型中的不同“专家”分配到不同的计算设备上,以提高计算效率。
EPLB冗余专家策略的关键点:
- 负载检测:在线部署期间,EPLB持续收集关于各个专家负载的统计数据。这些数据用于识别哪些专家是高负载的。
- 专家复制:对于检测到的高负载专家,EPLB会在其他GPU上创建这些专家的副本,即冗余专家。目的是分散负载,避免某些GPU过载而其他GPU闲置。
- 定期调整:冗余专家的集合会定期(例如,每10分钟)根据观察到的负载进行调整,以确保负载均衡。
- 负载重分配:在确定冗余专家集之后,EPLB会根据当前的负载情况,重新安排专家在GPU之间的分布,以尽可能平衡负载,同时尽量减少跨节点的全对全通信开销。
- 动态冗余:EPLB还探索了动态冗余策略,即在每个推理步骤中,每个GPU可能承载更多的专家,但只有一部分会被激活,以进一步优化负载均衡。
总结:DualPipe是一种创新的双向流水线并行算法,旨在通过完全重叠前向和后向计算-通信阶段来提高模型训练效率,减少流水线气泡。它通过对称调度微批次,实现了高效的计算资源利用。
EPLB则是为解决专家并行中负载不均衡问题而设计的负载均衡器,通过动态调整专家分布和冗余专家策略,最大化资源利用率,适用于超大规模MoE模型。显著提升了分布式训练的性能和效率,对于处理大规模机器学习任务具有重要意义。
6. Day 5 - 3FS, Thruster for All DeepSeek Data Access

Fire-Flyer 文件系统 (3FS) - 一种并行文件系统,可利用现代 SSD 和 RDMA 网络的全部带宽。
- ⚡ 180 节点集群中的 6.6 TiB/s 聚合读取吞吐量
- ⚡ 在 25 节点集群中,GraySort 基准测试的吞吐量为 3.66 TiB/min
- ⚡ 每个客户端节点 40+ GiB/s 峰值吞吐量,用于 KVCache 查找
- 🧬 具有强一致性语义的分解架构
- ✅ 训练数据预处理,数据集加载,检查点保存/重新加载,嵌入向量搜索和KVCache查找以进行V3/R1中的推理
- 📥 3FS → GitHub - deepseek-ai/3FS: A high-performance distributed file system designed to address the challenges of AI training and inference workloads.
- ⛲ Smallpond - 3FS → https://github.com/deepseek-ai/smallpond 上的数据处理框架
Fire-Flyer File System(3FS) 是一个高性能分布式文件系统,旨在解决人工智能训练和推理工作负载的挑战。它利用现代固态硬盘(SSD)和远程直接内存访问(RDMA)网络,提供一个共享存储层,从而简化分布式应用程序的开发。
Smallpond 基于 3FS 和 DuckDB 构建,专注于 PB 级数据的快速处理。Smallpond 定位为 AI 数据的辅助工具,能够无缝集成到 3FS 的存储生态中,支持数据清洗、转换和分析等任务。
3FS 核心亮点:
- 高性能解耦架构:通过解耦架构,结合数千个 SSD 的吞吐量和数百个存储节点的网络带宽,实现高吞吐量和低延迟。
- 数据强一致性:采用 Chain Replication with Apportioned Queries (CRAQ) 技术,确保分布式环境中的数据强一致性,适合多节点并发读写。
- 多样化工作负载支持:支持数据准备、数据加载器、检查点和 KVCache 等多样化工作负载,提升 AI 应用效率。
Smallpond 核心亮点:
- 高性能查询:基于 DuckDB 的列式存储和向量化执行引擎,查询速度远超传统工具。
- 低开销:无需分布式集群支持,单机即可处理大规模数据,部署简单。
- 与 3FS 协同:直接利用 3FS 的存储能力,避免数据迁移成本,实现高效数据流水线。
总的来说,3FS 是一个高性能分布式文件系统,通过块存储、元数据管理和动态文件属性优化,实现了高效的数据存储与管理。它利用现代 SSD 和 RDMA 网络,支持高吞吐量和低延迟的数据访问,特别适合 AI 训练和推理工作负载。
Smallpond 则是基于 3FS 和 DuckDB 构建的轻量级数据处理框架,专为大规模数据处理设计。它具备高效性、易用性和无需运维的特点,支持多种数据格式和并行处理,能够显著提升数据处理效率。两者结合,为 AI 数据处理提供了强大的支持。
7. Day 6 - One More Thing: DeepSeek-V3/R1 Inference System Overview
DeepSeek-V3 / R1 推理系统的优化目标是:更大的吞吐,更低的延迟
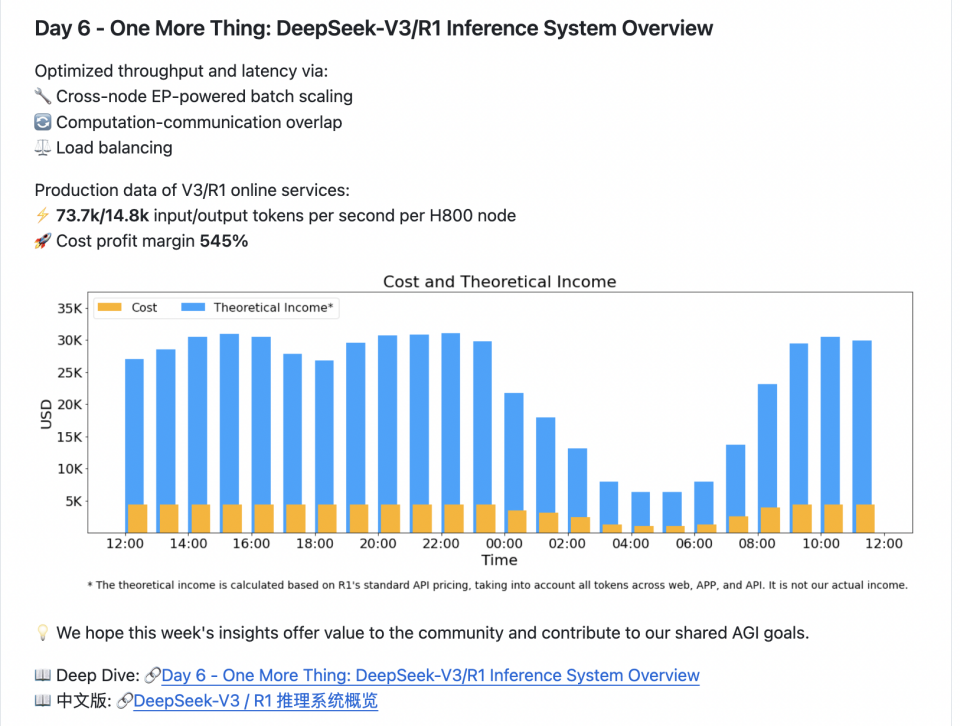
通过以下方式优化吞吐量和延迟:
- -🔧 跨节点 EP 支持的批量扩展
- 🔄 计算-通信重叠
- ⚖️ 负载均衡
V3/R1 在线服务生产数据:
- ⚡ 每个 H800 节点每秒 73.7k/14.8k 输入/输出令牌
- 🚀 成本利润率 545%
7.1. 专家并行(Expert Parallelism, EP)革命与三级负载均衡体系
采用多机多卡间的专家并行策略来达到以下目的:
- Prefill:路由专家 EP32、MLA 和共享专家 DP32,一个部署单元是 4 节点,32 个冗余路由专家,每张卡 9 个路由专家和 1 个共享专家
- Decode:路由专家 EP144、MLA 和共享专家 DP144,一个部署单元是 18 节点,32 个冗余路由专家,每张卡 2 个路由专家和 1 个共享专家
在MoE(Mixture-of-Experts)模型中,每个输入仅激活部分专家(如DeepSeek V3每层激活8/256个专家)。EP技术通过将专家分布到多GPU,实现:
- 吞吐量提升:单批次处理量扩大32-144倍
- 内存优化:单卡仅需存储部分专家参数
- 延迟降低:减少单卡计算负载
| 阶段 | 并行策略 | 节点数 | 单卡负载 |
|---|---|---|---|
| 预填充阶段 | EP32 + DP32 | 4 节点 | 9 路由专家 + 1 共享专家 |
| 解码阶段 | EP144 + DP144 | 18 节点 | 2 路由专家 + 1 共享专家 |
关键技术价值:相比传统单卡推理,EP实现数量级成本下降,H800集群效率超越英伟达H200 1.5倍
| 负载类型 | 优化目标 | 实现方法 |
|---|---|---|
| 预填充负载 | 注意力计算均衡 | 动态分配输入 token 数 |
| 解码负载 | KVCache 内存均衡 | 请求数平均分配 |
| 专家负载 | 热点专家分散 | 专家使用频率监控 + 动态迁移 |
技术亮点:通过实时监控实现<2%的负载偏差,避免木桶效应;
7.2. 通信-计算重叠优化
将请求拆分为 Micro-Batch,通过交替执行隐藏通信延迟。
- 预填充阶段:[计算MB1] -> [通信MB1][计算MB2] -> [通信MB2]
- 解码阶段:五级流水线:Attention拆分+多阶段重叠
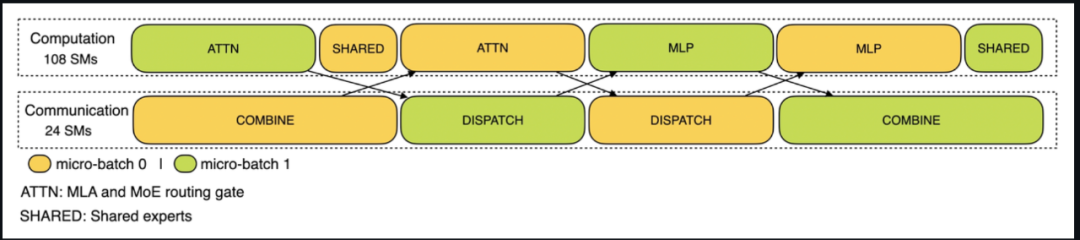
通信延迟降低40%;GPU空闲时间减少至<5%;
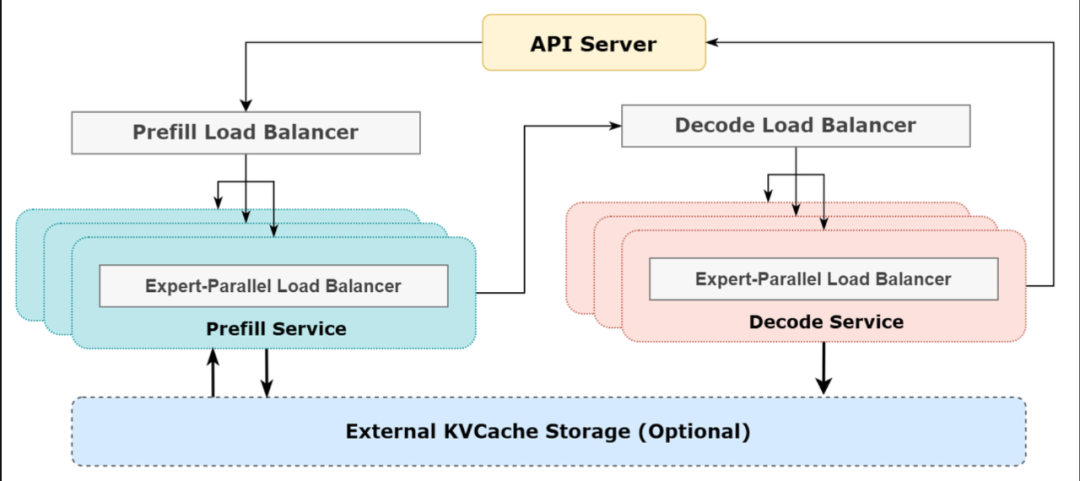
7.3. 推理系统架构优化
由于采用了很大规模的并行(包括数据并行和专家并行),如果某个 GPU 的计算或通信负载过重,将成为性能瓶颈,拖慢整个系统;同时其他 GPU 因为等待而空转,造成整体利用率下降。因此我们需要尽可能地为每个 GPU 分配均衡的计算负载、通信负载。
Prefill Load Balancer
- 核心问题:不同数据并行(DP)实例上的请求个数、长度不同,导致 core-attention 计算量、dispatch 发送量也不同
- 优化目标:各 GPU 的计算量尽量相同(core-attention 计算负载均衡)、输入的 token 数量也尽量相同(dispatch 发送量负载均衡),避免部分 GPU 处理时间过长
Decode Load Balancer
- 核心问题:不同数据并行(DP)实例上的请求数量、长度不同,导致 core-attention 计算量(与 KVCache 占用量相关)、dispatch 发送量不同
- 优化目标:各 GPU 的 KVCache 占用量尽量相同(core-attention 计算负载均衡)、请求数量尽量相同(dispatch 发送量负载均衡)
Expert-Parallel Load Balancer
- 核心问题:对于给定 MoE 模型,存在一些天然的高负载专家(expert),导致不同 GPU 的专家计算负载不均衡
- 优化目标:每个 GPU 上的专家计算量均衡(即最小化所有 GPU 的 dispatch 接收量的最大值)
- 路由层:智能请求分发
- 缓存系统:56.3%的磁盘KV缓存命中率
- 弹性调度:白天全节点推理,夜间部分节点转训练
- 精度控制:FP8通信 + BF16计算
本文深入剖析了DeepSeek发布的V3/R1推理系统。该系统以高达545%的原始成本利润率(行业标准折算后达85%)和单节点8,575 tokens/秒的惊人吞吐量,重新定义了大模型推理的性能边界。
其核心技术实现多项突破:
- 专家并行(Expert Parallelism)的革新:通过将MoE模型中的专家分布到多个GPU,显著提升吞吐量,优化显存占用,并大幅降低推理延迟;
- 通信-计算重叠优化:采用双批次流水线机制,将通信过程与计算过程高效重叠,通信延迟降低40%,GPU空闲时间控制在5%以内,极大提升硬件利用率;
- 三级负载均衡体系:覆盖预填充、解码与专家层级的精细化负载调度,实现系统整体负载偏差小于2%,有效避免“木桶效应”,保障高并发下的稳定性。
系统架构方面,DeepSeek V3/R1集成了智能路由层、高效KV缓存系统、弹性调度机制与动态扩缩容能力,构建了一套面向超大规模AI服务的高性能、高可用推理底座。
7.4. 成本评估与技术思考
DeepSeek V3 和 R1 的所有服务均使用 H800 GPU,使用和训练一致的精度,即矩阵计算和 dispatch 传输采用和训练一致的 FP8 格式,core-attention 计算和 combine 传输采用和训练一致的 BF16,最大程度保证了服务效果。
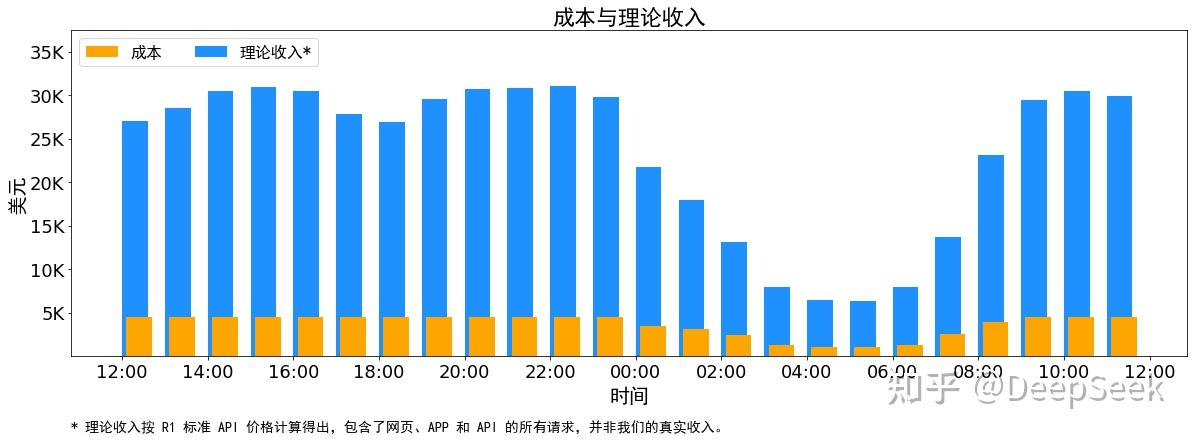
另外,由于白天的服务负荷高,晚上的服务负荷低,因此我们实现了一套机制,在白天负荷高的时候,用所有节点部署推理服务。晚上负荷低的时候,减少推理节点,以用来做研究和训练。在最近的 24 小时里(北京时间 2025/02/27 12:00 至 2025/02/28 12:00),DeepSeek V3 和 R1 推理服务占用节点总和,峰值占用为 278 个节点,平均占用 226.75 个节点(每个节点为 8 个 H800 GPU)。假定 GPU 租赁成本为 2 美金/小时,总成本为 $87,072/天。
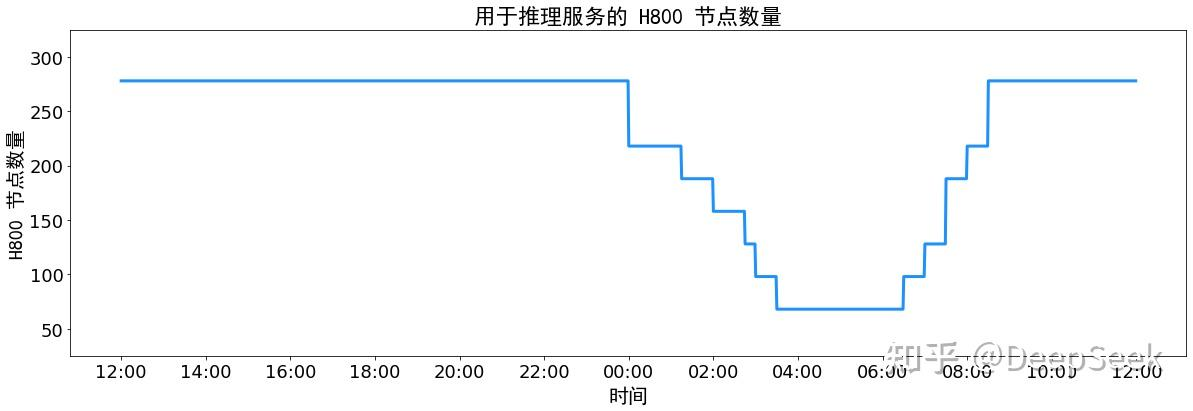
在 24 小时统计时段内,DeepSeek V3 和 R1:
- 输入 token 总数为 608B,其中 342B tokens(56.3%)命中 KVCache 硬盘缓存。
- 输出 token 总数为 168B。平均输出速率为 20~22 tps,平均每输出一个 token 的 KVCache 长度是 4989。
- 平均每台 H800 的吞吐量为:对于 prefill 任务,输入吞吐约 73.7k tokens/s(含缓存命中);对于 decode 任务,输出吞吐约 14.8k tokens/s。
以上统计包括了网页、APP 和 API 的所有负载。如果所有 tokens 全部按照 DeepSeek R1 的定价[1]计算,理论上一天的总收入为 $562,027,成本利润率 545%。
技术思考:
技术启示:
- MaaS规模效应:用户量达千万级时,边际成本骤降
- 超节点趋势:320卡紧耦合系统成为新标杆
- 精度创新:FP8+BF16混合精度实践
市场冲击:
- 价格战加速:行业成本骤然下降
- 硬件需求变化:NVLink带宽重要性凸显
- 商业模式创新:免费服务引流+API变现的组合策略
未来挑战:
- 万卡级EP系统的稳定性
- 多模态场景的扩展
- 动态稀疏性的极致优化
8. 附录
成本利润率
衡量系统经济效益的核心指标,反映单位成本所带来的利润水平。行业标准折算后,DeepSeek V3/R1推理系统的成本利润率达到 85%(原始值为545%),显著优于行业平均水平。这一数据表明,该系统在控制投入成本的同时实现了高效收益输出,具备极强的商业可持续性。
类比:如同经营一家企业,利润与成本之比越高,盈利能力越强。
吞吐量(Throughput)
衡量系统处理能力的关键性能指标。DeepSeek V3/R1推理系统单节点吞吐量可达 8,575 tokens/秒,意味着每秒可处理多达8,575个语言单元(token)。高吞吐量保障了大规模并发请求下的响应效率。
类比:相当于一条生产线每秒能产出的产品数量,越高代表产能越强。
专家并行(Expert Parallelism, EP)
在混合专家模型(MoE)中,将不同的“专家”模块分布到多个GPU上并行执行的技术。通过分散计算负载,EP有效提升系统吞吐量、优化显存使用,并显著降低延迟,实现数量级的成本下降。
类比:如同将一项复杂工程按专业分工,交由不同团队并行处理,整体效率大幅提升。
混合专家模型(Mixture-of-Experts, MoE)
一种高效的稀疏模型架构,其核心思想是“按需激活”——每个输入仅调用部分专家进行计算。例如,DeepSeek V3在每层中仅激活 8个专家(共256个),大幅减少计算开销,同时保持强大表达能力。
类比:如同一个大型项目,由多个专业小组组成,但每次只让最合适的小组参与,避免资源浪费。
Micro-Batch(微批次)
将一个请求拆分为更小的数据单元进行处理的技术手段。结合双批次流水线机制,micro-batch 可实现计算与通信的高效重叠,有效隐藏延迟,提升系统整体利用率。
类比:把一大份任务切成小块,交替流水作业,让各个环节始终“不停工”。
通信-计算重叠优化
通过流水线调度等技术,将原本串行的通信与计算过程并行化,使通信发生在计算过程中,从而降低通信等待时间达 40%,并将GPU空闲率控制在 <5%,极大提升硬件利用率。
类比:做饭时一边炒菜一边洗碗备料,时间利用最大化。
三级负载均衡体系
一套精细化的动态负载管理机制,覆盖三大关键维度:
- 预填充阶段负载均衡:动态分配输入token数量,避免长文本阻塞;
- 解码阶段负载均衡:平均分配生成请求,防止节点过载;
- 专家级负载均衡:监控各专家使用频率,动态迁移热点专家,避免局部瓶颈。最终实现系统负载偏差 <2%,彻底缓解“木桶效应”。
路由层(Routing Layer)
推理系统中的智能调度中枢,负责根据输入内容和模型结构,将请求精准分发到对应的专家或计算单元。其决策直接影响系统效率与资源利用率。
类比:如同快递分拣中心,自动识别包裹目的地并分配至正确的运输线路。
缓存系统(KV Cache)
用于存储注意力机制中键值对(Key-Value)的高速缓存系统。DeepSeek推理系统的磁盘KV缓存命中率达到 56.3%,意味着超过一半的请求无需重复计算,可直接复用历史结果,显著降低延迟与计算开销。
类比:像一个常用物品收纳柜,多数时候能快速取用,无需重新准备。
弹性调度(Elastic Scheduling)
根据业务负载周期动态调整计算资源用途的策略。例如,DeepSeek系统在白天全节点用于推理服务,夜间则将部分节点切换至训练任务,实现资源全天候高效利用。
类比:工厂白天全力生产,晚上利用闲置产能进行设备维护或新产品试制。
精度控制(Precision Control)
采用 FP8通信 + BF16计算 的混合精度方案,在保证模型推理精度的前提下,大幅降低通信带宽和计算资源消耗,实现性能与精度的最优平衡。
类比:根据不同工序选择合适精度的工具——精细操作用高精度仪器,粗加工则用高效工具,兼顾效率与质量。
动态扩缩容(Dynamic Scaling)
根据实时负载自动增减计算节点数量的能力。例如,DeepSeek V3/R1系统在日间峰值使用 278个节点,夜间低谷缩减至 180个节点,并通过基于LSTM的负载预测模型实现前瞻性扩容,保障服务稳定性与资源经济性。
类比:商场根据季节和客流变化灵活调整营业面积与员工数量,做到“按需用人、按量开店”。
MaaS(模型即服务,Model-as-a-Service)
一种以AI模型为核心的服务模式,用户通过API调用即可获得强大智能能力。当用户规模达到千万级时,边际成本急剧下降,形成显著的规模效应。
类比:类似共享出行平台——用户越多,单次服务成本越低,平台效益越高。
超节点趋势(Ultra-Node Trend)
指由 320 张GPU卡 构成的高耦合、低延迟、紧集成的“超节点”架构正成为大模型推理的新标准。这种架构强调硬件间的深度协同,满足大模型对通信效率和算力密度的极致要求。
类比:建造摩天大楼时,不再依赖松散拼接的模块,而是采用一体化高强度结构,支撑更大负荷。
动态稀疏性(Dynamic Sparsity)
在模型推理过程中,根据输入特征动态选择需要激活的计算路径,仅对关键部分进行运算,跳过冗余计算,从而显著提升计算效率与能效比。
类比:学习时只聚焦重点章节,跳过已掌握内容,实现“精准学习”,事半功倍。
9. 参考
Day 1
Day 2
Day 3
Day 4
Day 5
Day 6