1. 语言模型训练和推理
一般来说,语言模型旨在对于人类语言的内在规律进行建模,从而准确预测词序列中未来(或缺失)词或词元(Token)的概率。根据所采用技术方法的不同,针对语言模型的研究工作可以分为以下四个主要发展阶段:
- 统计语言模型(Statistical Language Model, SLM)
- 神经语言模型(Neural Language Model, NLM)
- 预训练语言模型(Pre-trained Language Model, PLM)
- 大语言模型(Large Language Model, LLM)
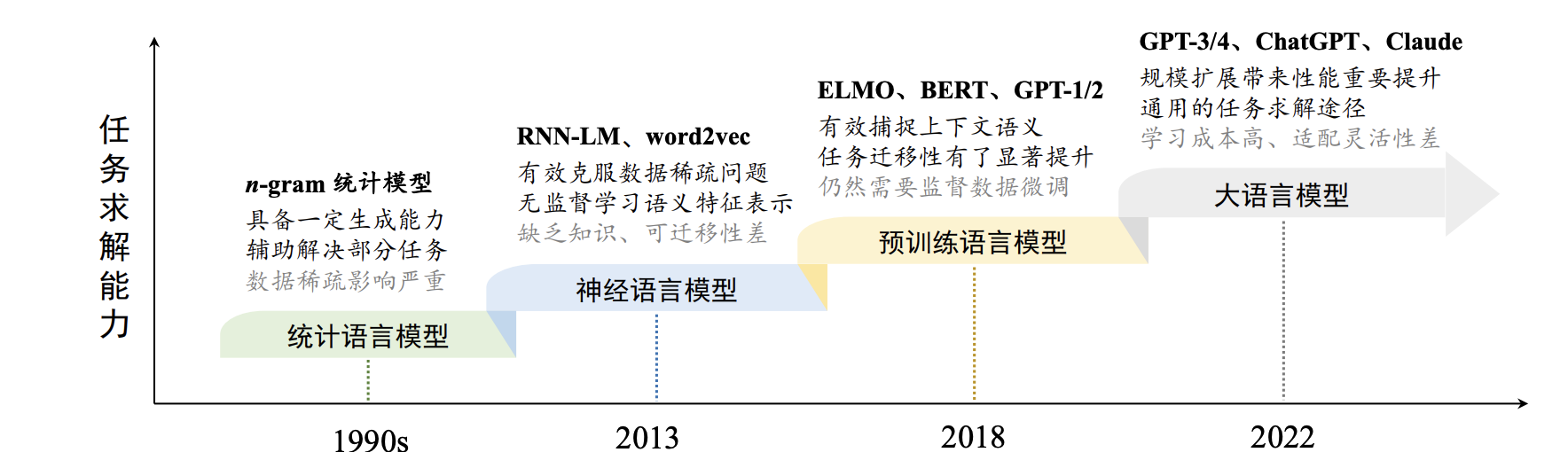
早期的统计语言模型主要被用于(或辅助用于)解决一些特定任务,主要以信息检索、文本分类、语音识别等传统任务为主。随后,神经语言模型专注于学习任务无关的语义表征,旨在减少人类特征工程的工作量,可以大范围扩展语言模型可应用的任务。进一步,预训练语言模型加强了语义表征的上下文感知能力,并且可以通过下游任务进行微调,能够有效提升下游任务(主要局限于自然语言处理任务)的性能。随着模型参数、训练数据、计算算力的大规模扩展,最新一代大语言模型的任务求解能力有了显著提升,能够不再依靠下游任务数据的微调进行通用任务的求解。
大语言模型:研究人员发现,通过规模扩展(如增加模型参数规模或数据规模)通常会带来下游任务的模型性能提升,这种现象通常被称为“扩展法则”(Scaling Law)。大规模的预训练语言模型在解决复杂任务时表现出了与小型预训练语言模型(例如 330M 参数的 BERT 和 1.5B 参数的 GPT-2)不同的行为。例如,GPT-3 可以通过“上下文学习”(In-Context Learning, ICL)的方式来利用少样本数据解决下游任务,而 GPT-2 则不具备这一能力。这种大模型具有但小模型不具有的能力通常被称为“涌现能力”(Emergent Abilities)。为了区别这一能力上的差异,学术界将这些大型预训练语言模型命名为“大语言模型”(Large Language Model, LLM)。
接下来给大家普及 Transformer 架构。
2. Transformer 架构
2.1. 基本概念
Transformer 是⼀种完全基于注意⼒机制(Self-Attention)的神经⽹络模型,由 Vaswani 等⼈在 2017 年提出,标志着⾃然语⾔处理领域的⼀个重要突破。Transformer 解决了 RNN(循环神经⽹络)和 CNN(卷积神经⽹络)在处理⻓序列时的效率和性能问题,特别是在捕捉全局依赖关系、并⾏计算以及克服梯度消失等⽅⾯表现出⾊。
2.2. 核心架构
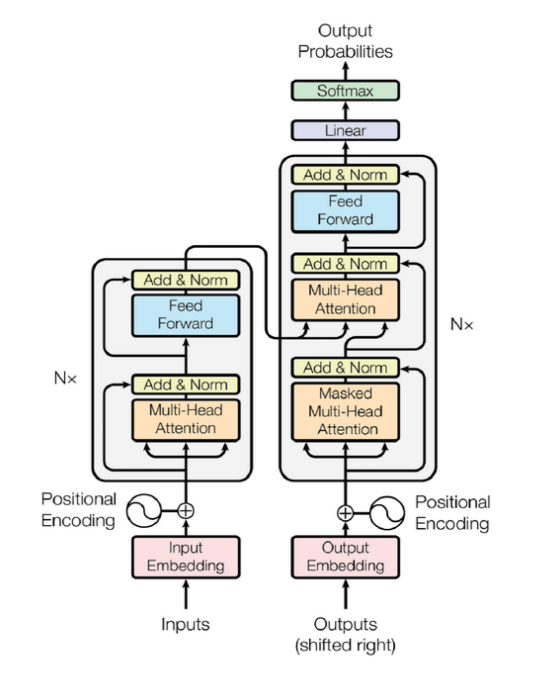
Transformer 的架构基于经典的 Encoder-Decoder 结构,其中编码器(Encoder)和解码器(Decoder)各⾃承担了不同的任务,分⼯明确,如下所示:
- 编码器(Encoder)- 理解输⼊序列:编码器的任务是对输⼊序列(例如⼀段⽂本或⼀段⾳频)进⾏编码,提取其中的特征和上下⽂信息,并将其转化为更⾼维的隐状态表⽰(hidden states),即语义向量。编码器通过⾃注意⼒机制(Self-Attention)和前馈神经⽹络(Feed-Forward Network)捕捉输⼊序列中各个位置之间的依赖关系,⽣成能够反映序列全局上下⽂的表⽰。
- 解码器(Decoder)- ⽣成⽬标序列:解码器的任务是根据编码器⽣成的隐状态表⽰,以及已经⽣成的⽬标序列部分(在训练时⽬标序列是已知的,在推理时是逐步⽣成的),⽣成最终的⽬标输出序列(例如翻译后的⽂本)。解码器不仅要关注编码器输出的全局语义信息,还需要通过⾃注意⼒机制在⽬标序列中引⼊依赖,使其在⽣成新词时考虑到已经⽣成的词。
总结:编码器负责对输⼊⽂本进⾏编码,⽣成上下⽂向量。解码器根据编码器的输出,⽣成⽬标序列中的每个词。
Encoder(编码器) 组成部分:每个编码器层由两个主要⼦层组成,分别为多头⾃注意⼒机制(Multi-Head Self-Attention Mechanism)和位置前馈神经⽹络(Position-Wise Feed-Forward Neural Network):
- 多头⾃注意⼒机制(Multi-Head Self-Attention) 它通过 并⾏地计算多个⾃注意⼒头,使模型能够从不同的⻆度对输⼊序列进⾏信息聚合。对于每个输⼊词的表⽰,模型通过对⽐该词与其他所有词的相关性来捕获其上下⽂关系。这个过程通过查询(Query)、键(Key)和值(Value)的点积来实现。计算过程为:
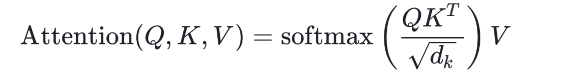
其中, dk 是查询和键向量的维度,⽤于归⼀化点积结果以防⽌梯度过⼤或过⼩。
- 前馈神经⽹络(Position-Wise Feed-Forward Network) 这个部分独⽴地应⽤于每个位置的词向量表⽰,包含两个全连接层,中间加⼊ ReLU 激活函数:
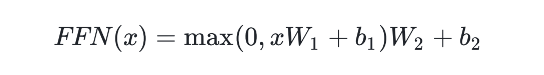
通过对每个位置独⽴应⽤相同的前馈⽹络,编码器可以在保留序列结构的同时,对每个词进⾏⾮线性变换。
- 残差连接与层归⼀化(Residual Connections & Layer Normalization) 每个⼦层都会加⼊残差连接,并且在通过⼦层前进⾏层归⼀化,以解决梯度消失和加速模型收敛。残差连接帮助维持信息流动,避免深层⽹络中信息的丢失。归⼀化公式为:
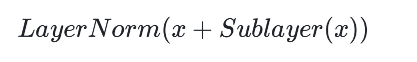
Decoder(解码器) 组成部分:解码器除了具有与编码器相似的多头⾃注意⼒机制和前馈神经⽹络外,还多了⼀个编码器 - 解码器注意⼒层(Encoder-Decoder Attention Layer):
- 多头⾃注意⼒机制(Masked Multi-Head Self-Attention) 为了确保模型在预测下⼀个词时,只能利⽤之前⽣成的词,加⼊了掩码机制(Masking)。掩码操作将未来词的注意⼒权重置为负⽆穷,防⽌模型获取不应访问的信息。
- 编码器 - 解码器注意⼒层(Encoder-Decoder Attention Layer) 该层作⽤是通过编码器输出的上下⽂向量,关注输⼊序列中的相关部分,来帮助解码器⽣成与输⼊相对应的⽬标序列。
- 前馈神经⽹络(Feed-Forward Network) 与编码器中的结构相同,独⽴地应⽤于解码器中每个词的表⽰上。
相同点:
- 基础模块:均由多层 Self-Attention + Feed Forward Network 组成。
- 残差连接 & Layer Normalization:每个子层(注意力、FFN)后都有残差连接和归一化。
- 多头注意力机制:均使用多头注意力(Multi-Head Attention)捕捉上下文依赖。
不同点:
| 模块 | Encoder | Decoder |
|---|---|---|
| Self-Attention | 全上下文注意力 (可看到输入的所有位置) | Masked Self-Attention (只能看到当前位置及之前的词,防止信息泄漏) |
| Cross-Attention | 无 | 有 (通过 Encoder-Decoder Attention 关联编码器输出) |
| 输入依赖 | 仅处理输入序列 (如源语言句子) | 依赖编码器输出 + 已生成的目标序列 (如翻译结果的前缀) |
与 RNN 不同,Transformer 摒弃了序列顺序的递归处理⽅式,避免了序列⻓度增⻓带来的信息传递瓶颈。在 RNN 中,信息依赖于时间步⻓逐步传递,导致序列过⻓时早期信息容易衰减,且⽆法并⾏处理,训练时间较⻓。CNN 虽然可以通过卷积核来捕捉局部特征,但它的感受也有限,很难处理序列中的远程依赖。相⽐之下,Transformer 通过全局的注意⼒机制,允许每个位置的词语直接关注序列中的其他所有位置,实现了更⾼效的⻓程依赖捕捉。这样不仅提升了模型处理⻓序列的能⼒,还有效减少了序列信息丢失问题。
将句子 “The cat sat on the mat” 翻译为 “猫坐在垫子上”。
RNN 的串行处理:
- 必须逐步处理输入:先读 “The” → 生成隐藏状态 → 读 “cat” → 更新隐藏状态 → 依此类推。
- 输出也是逐词生成:“猫” → “坐” → “在”… 无法并行。
- 瓶颈:长句子依赖关系容易丢失(如 “sat” 和 “The cat” 的关联),且计算效率低。
Transformer 的并行处理(QKV 矩阵):
- 同时处理整个输入序列:[“The”, “cat”, “sat”, “on”, “the”, “mat”] 通过 Self-Attention 直接建模所有词的关系(例如 “sat” 和 “cat” 的关联)。
- 输出解码时,虽然生成是顺序的,但训练阶段可以通过并行计算所有目标词(“猫”、“坐”、“在”…)的损失。
- 优势:GPU 可同时计算所有位置的注意力权重,大幅加速训练。
Transformer 的架构⽀持⼤规模并⾏计算(受益于 NVIDIA 并行计算能力),因为它不需要像 RNN 那样逐步处理序列数据,⽽是可以同时处理整个输⼊序列。 这⼤⼤提⾼了训练效率,尤其在处理海量数据和复杂任务时表现优异。
总结:Transformer 通过引⼊注意⼒机制和并⾏计算,解决了传统序列模型的效率问题,已经成为 NLP 领域的主流架构。
Transformer 就像一群人在玩传话游戏:
- 每个人(Token):句子里的每个字/词先变成数字向量(比如“猫”=[0.2, 0.6]);
- 看全场(Attention):每个人传话,会先扫一眼全场所有人,决定重点听谁的话(比如“ 吃” 更关注 “猫” 和 “鱼”);
- 分工合作(多头):分成多组(头),每组关注不同信息(一组看“谁在吃”,一组看“吃什么”);
- 记笔记(Feed Forward):听完大家的话后,自己消化一下,更新自己的内容;
- 层层传递(多层):这样一层层传下去,每一轮都让信息更准确;
核心关键:不用死记顺序(RNN 的缺点),而是随时动态关注全场重要信息,像人一样灵活理解上下文。
3. 训练 GPT 助手
根据 OpenAI 所公开的信息,OpenAI 所使用的大规模语言模型构建流程主要包含四个阶段:预训练、有监督微调、奖励建模、强化学习。这四个阶段都需要不同规模数据集合以及不同类型的算法,会产出不同类型的模型,同时所需要的资源也有非常大的差别。通常来说,pre-training -> SFT -> RM -> RL 是典型的大模型训练过程。下图展示从预训练开始逐步训练出一个 GPT 助手的步骤;

每个阶段的详细内容如下:
预训练阶段(Pretraining Stage)(使用了数千块GPU,耗费数月时间训练)
- 数据集(Dataset):使用来自互联网的原始文本数据,数据量达到万亿级别的单词(tokens)。这些数据量巨大但质量较低,涵盖了各种类型的内容;
- 算法(Algorithm):模型通过预测文本序列中的下一个token来进行训练,这是标准的自回归语言模型训练方式;
- 模型(Model):基础模型(Base Model),经过预训练的基础语言模型,例如 GPT、LLaMA、DeepSeek-Base-V3 等模型,经过数月使用成千上万块GPU训练而成;
有监督微调阶段(Supervised Finetuning Stage)(使用了1到100块GPU,耗时数天进行训练)
- 数据集(Dataset):由人工编写的理想助手响应数据集,包含约1到10万个问题及其响应值,数据量相对较少,但质量非常高;
- 算法(Algorithm):继续通过语言建模的方式,对模型进行微调,专注于学习这些高质量的问答;
- 模型(Model): 在基础模型的基础上,通过有监督微调训练得到的模型(微调模型),模型可以用于更具体的任务并部署;
奖励建模阶段(Reward Modeling Stage)(使用了1到100块GPU,耗时数天进行训练 )
- 数据集(Dataset): 使用由人工编写的10万到100万个回答的好坏对比数据。这些数据量虽然较少,但质量非常高,用于训练模型区分高质量和低质量的回答;
- 算法(Algorithm): 训练奖励模型(二值分类 Binary Classification),预测根据用户偏好进行奖励的结果。该模型用来评估和指导模型生成更好的回答;
- 模型(Model): 通过二值分类训练得到的奖励模型(RM Model),它不能独立部署,主要用于强化学习阶段的模型优化;
强化学习阶段(Reinforcement Learning Stage)(使用了1到100块GPU,耗时数天进行训练,可进行部署和实际应用)
- 数据集(Dataset):使用由人工编写的约1到10万个提示语句进行训练。数据量较少但质量很高,帮助模型在特定上下文中生成更优质的响应;
- 算法(Algorithm):强化学习使用奖励模型指导生成 token,通过生成使奖励最大化的token序列来优化模型的表现;
- 模型(Model): 经过强化学习训练的最终模型(强化学习模型RL Model),初始化自微调模型,并利用奖励模型进行优化。这些模型可以在实际应用中部署,如 ChatGPT、Claude等;
接着介绍与 token 化相关的一些基本概念,然后概述语言模型的预训练和推理过程,以及它们与下一个 token 预测的关系。
4. 预测下一个 token
要理解大语言模型(LLM),首先要理解它的本质,无论预训练、微调还是在推理阶段,核心都是 next token prediction,也就是以 自回归 的方式 从左到右 逐步生成文本。
要理解下一个 token 预测,可能遇到的第一个问题是:什么是 token?简而言之,token 是指文本中的一个词或者子词,给定一句文本,进入语言模型前首先要做的是对原始文本进行 tokenizer,也就是把一个文本序列拆分为离散的 token 序列。
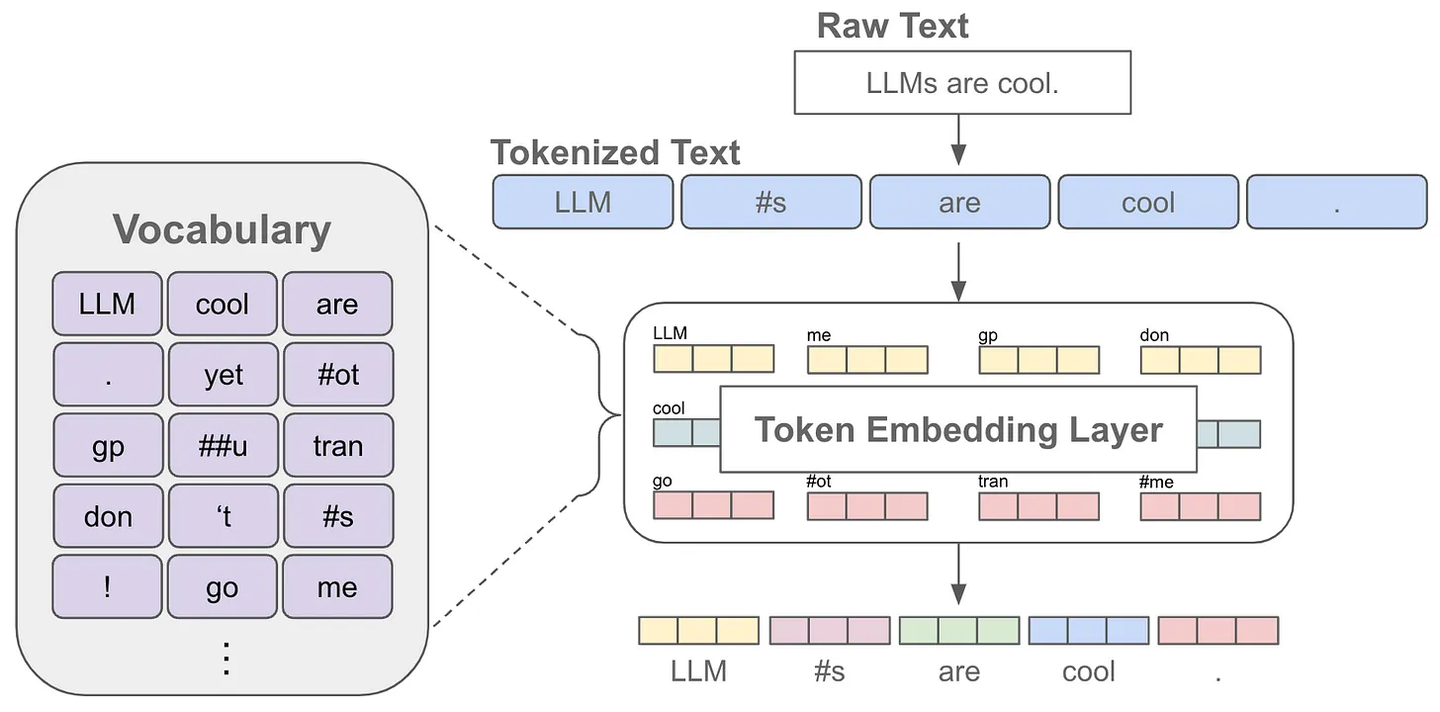
其中,tokenizer 是在无标签的语料上训练得到的一个 token 数量固定且唯一的分词器,这里的 token 数量就是大家常说的词表,也就是语言模型知道的所有 tokens。tokenizer 存在多种不同的标记化技术,比如 BPE、BBPE。BPE(字节对编码)和 BBPE(字节级 BPE)是两种流行的标记化技术:BPE 基于字符合并高频子词(如将"unhappy"拆分为[“un”,“happy”]),适合单语言场景并保留语义。而 BBPE 先将文本转换为UTF-8字节序列再应用 BPE(如汉字"你"拆分为 3 个字节),以 256 字节的基础单元实现多语言通用支持(如GPT-4),词表更小但可能增加序列长度。
关键差异在于 BPE 依赖字符级处理(需定制词表),BBPE 通过字节级操作天然兼容所有语言和符号(如 emoji),成为大模型跨语言处理的首选,但需权衡语义粒度与计算效率。
当我们对文本进行分词后,每个 token 对应一个 embedding,这也就是语言模型中的 embedding 层,获得某个 token 的 embedding 就类似一个查表的过程。
我们知道文本序列是有顺序的,而常见的语言模型都是基于注意力机制的 Transformer 结构,无法自动考虑文本的前后顺序,因此需要手动加上位置编码,也就是每个位置有一个位置 embedding,然后和对应位置的 token embedding 进行相加。
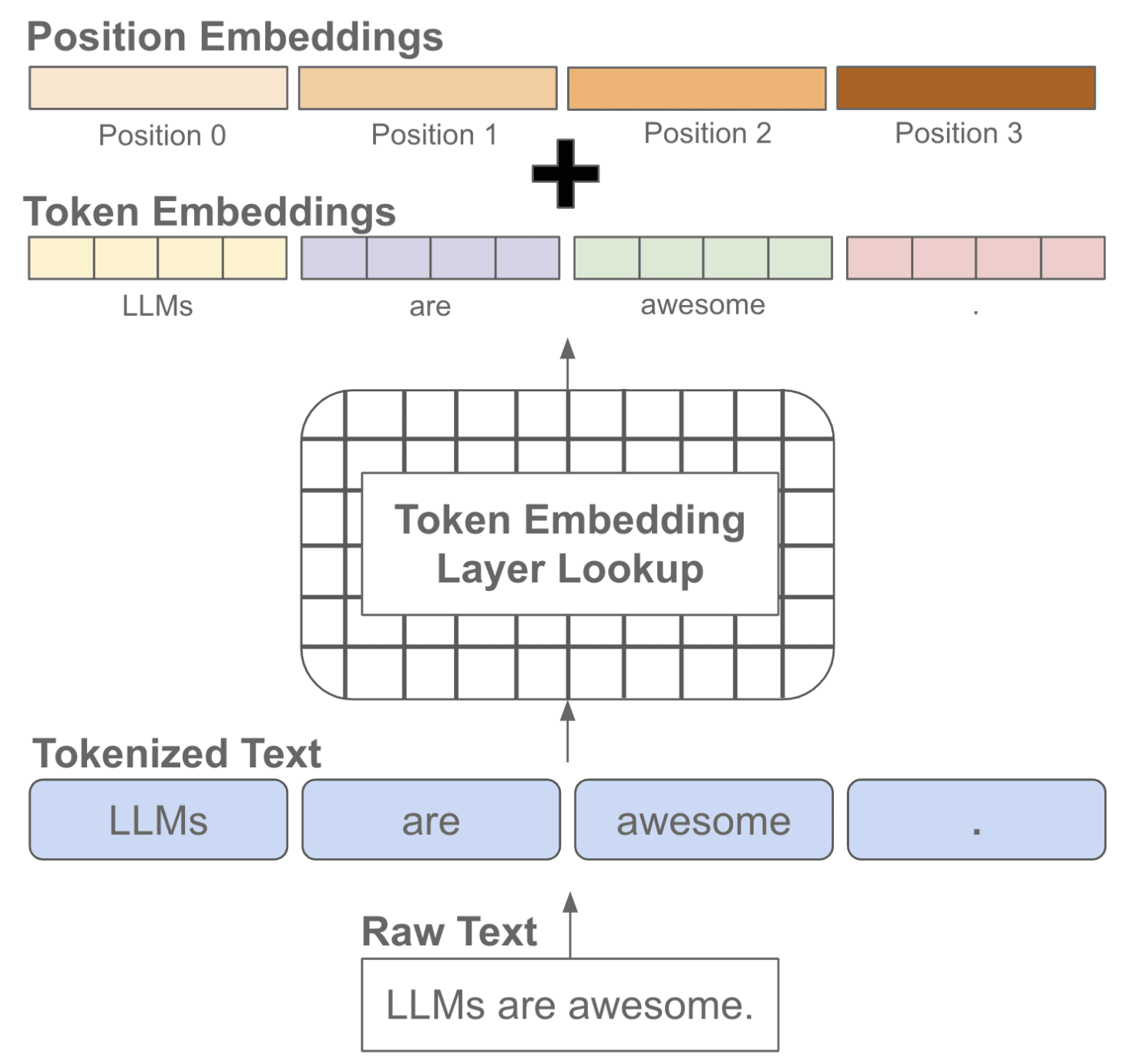
因为自注意力操作无法表示每个 token 的位置,通过添加位置嵌入,允许 Transformer 中的自注意力层在学习过程中将每个 token 的位置用作相关特征。将位置信息注入自注意力,从而产生了 RoPE 技术。 在模型训练或推理阶段大家经常会听到 上下文长度 这个词,它指的是模型训练时接收的 token 训练的最大长度。上下文长度大小(通常在 1K 到 8K 个 token 之间)通常是根据硬件和内存限制选择的,如果在训练阶段只学习了一个较短长度的位置 embedding,那模型在推理阶段就不能够适用于较长文本(因为它没见过长文本的位置编码)。为了解决该问题,大家最近又开发了 ALiBi 等技术,以便能够推断出比训练期间看到的更长的输入。
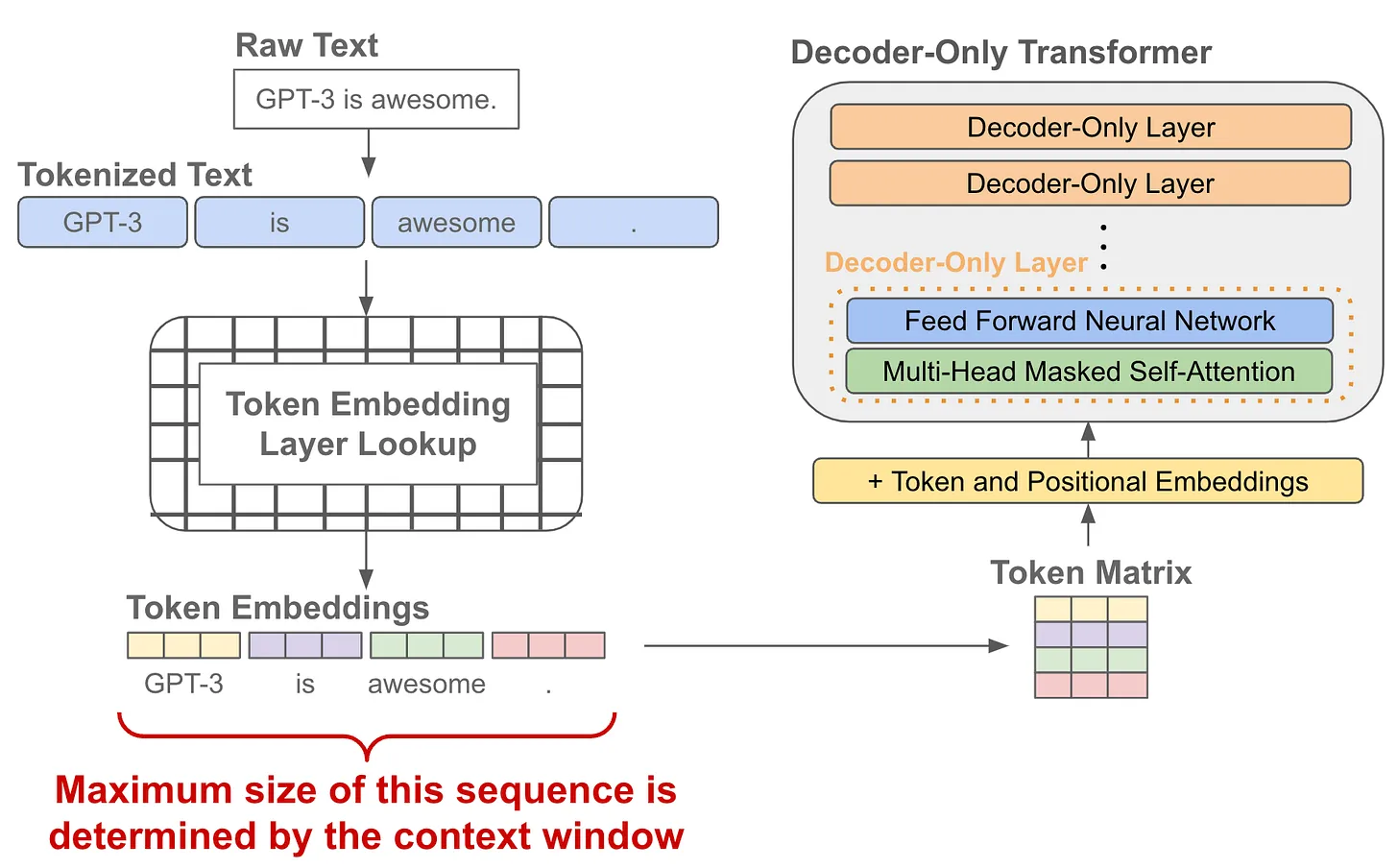
当我们有了 token embedding 和 位置 embedding 后,将它们送入一个 decoder-only 的 Transformer 模型,它会在每个 token 的位置输出一个对应的 embedding。
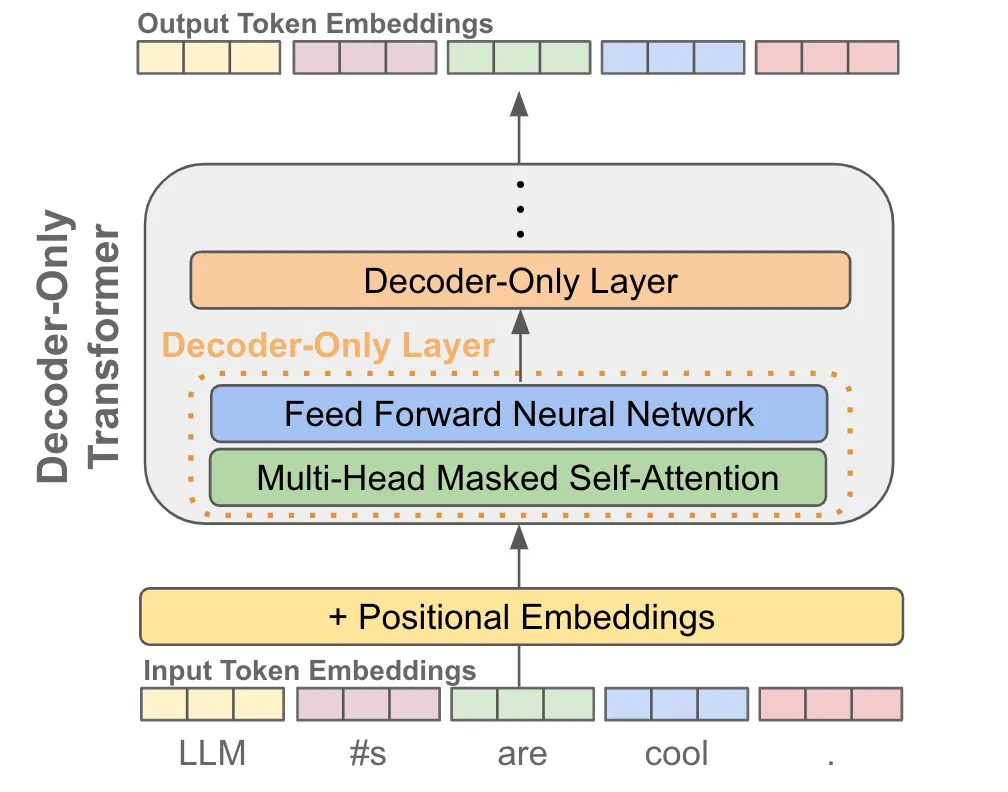
有了每个 token 的一个输出 embedding 后,就可以拿它来做 next token prediction,其实就是当作一个分类问题来看待。
- 首先把 输出 embedding 送入一个 线性层,输出的维度是词表的大小,就是让预测这个 token 的下一个 token 属于词表的“哪一类”;
- 为了将输出概率归一化,需要再进行一个 softmax 变换;
- 训练时就是最大化这个概率使得它能够预测真实的下一个 token;
- 推理时就是从这个概率分布中采样下一个 token;
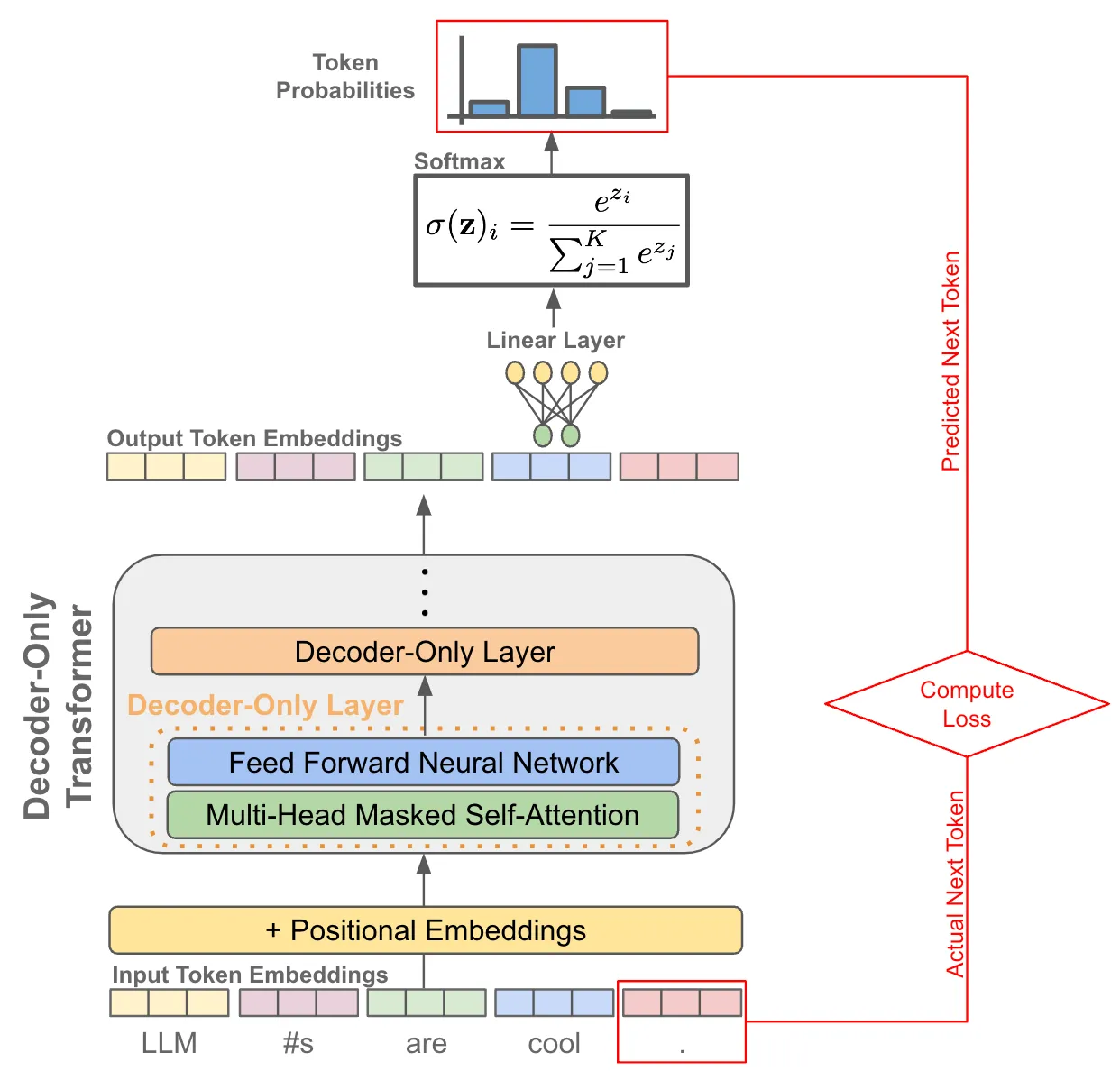
训练阶段:因为有 causal 自注意力的存在,可以一次性对一整个句子每个 token 进行下一个 token 的预测,并计算所有位置 token 的 loss 函数,可以使用仅解码器转换器的单次前向传递对整个序列执行下一个标记预测。
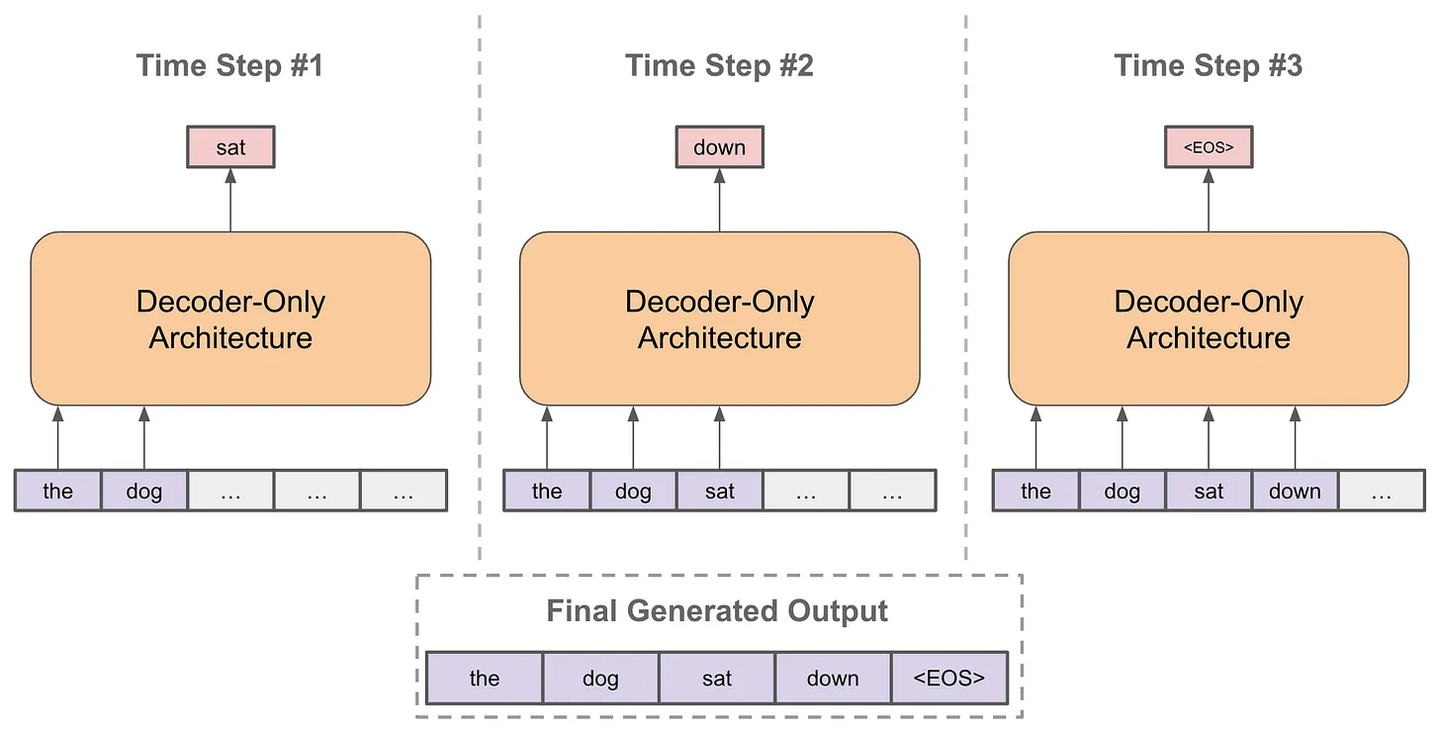
推理阶段:以自回归的方式进行预测。
- 每次预测下一个 token;
- 将预测的 token 拼接到当前已经生成的句子上;
- 再基于拼接后的句子进行预测下一个 token;
- 不断重复直到结束;
推理阶段总结:实际上如何从该概率分布中选择下一个 token?在预测下一个 token 时,每次我们都有一个概率分布用于采样,但是根据不同场景选择采样策略会略有不同,贪婪策略、核采样、Top-k 采样等,另外经常会看到 Temperature 这个概念,它是用来控制生成的随机性的,温度系数越小越稳定。
总结:大语言模型(LLM)的核心是通过自回归方式逐词预测(next token prediction)。文本首先被 tokenizer 拆分为词或子词(如 BPE、BBPE 技术),每个 token 对应一个嵌入向量,并加入位置编码(如 RoPE)以保留顺序信息。模型基于 Transformer 结构,训练时通过注意力机制学习上下文关系,输出每个 token 的下一个词概率分布(softmax 归一化)。推理时采用自回归生成,通过采样策略(如 Top-k)和温度系数控制随机性。ALiBi 技术解决了长文本位置编码的外推问题,使模型能处理超越训练长度的输入。整个过程本质是序列条件概率建模,通过海量数据学习语言的统计规律。
5. 专业名词
传统机器学习:传统机器学习是通过算法从数据中学习规律以完成预测或决策的技术,适用于数据量适中、任务明确且需高可解释性的领域(金融风控、推荐系统),依赖特征工程,与深度学习相比计算成本低但泛化能力较弱;核心分为以下三类:
- 监督学习(如SVM、决策树):利用标注数据训练模型,解决分类(如疾病诊断)和回归(如销量预测)问题;
- 无监督学习(如 K-means、PCA):从无标签数据中发现结构,应用于聚类(客户分群)和降维(数据可视化);
- 强化学习(如 Q-learning):通过环境交互的奖励信号优化策略,适用于动态控制(如机器人导航);
大语言模型:大语言模型(LLM,Large Language Model),也称大型语言模型,是一种旨在理解和生成人类语言的人工智能模型。大语言模型(LLM)是一种基于 Transformer 架构的先进人工智能技术,通过大规模参数(GPT-3 1750亿个参数)与海量数据的结合,采用预训练与微调的方法,实现了卓越的语言理解与生成能力,能够完成文本生成、翻译、问答等多样化任务。然而,其在实践中仍面临诸多挑战,如潜在的偏见问题、计算成本高以及对复杂语义的理解深度有限。日常生活中代表性模型包括 OpenAI 的 GPT 系列、Google 的 BERT 与 PaLM,以及 Meta 的 LLaMA,深度求索的 DeepSeek 等。
Transformer:Transformer 是一种深度学习模型架构,最初用于自然语言处理任务。它的核心机制是“自注意力”(Self-Attention),可以让模型在处理序列时同时关注到所有位置的信息,因此非常适合处理语言、图像等顺序数据。相比传统的循环神经网络(RNN),Transformer 更易于并行计算,训练效率更高,目前广泛应用于机器翻译、文本生成、图像分析等领域。
Transformer 类型:Transformer 模型分为三类,各有适用场景,如下所示:
- Encoder-only:用于理解任务,如分类、问答(例:BERT);
- Decoder-only:用于生成任务,如写作、对话(例:GPT);
- Encoder-Decoder:用于输入输出不同的任务,如翻译、摘要(例:T5、BART);
Transformer 核心结构:Transformer 的核心结构由多个层组成,每层功能如下:
- 多头自注意力(Multi-Head Self-Attention):捕捉序列中各位置间的关系,提取上下文信息;
- 前馈网络(Feed-Forward Network):对每个位置独立处理,增加非线性表达能力;
- 残差连接 + LayerNorm:稳定训练,避免信息丢失;
- 位置编码(Positional Encoding):加入位置信息,让模型识别词序;
注意力机制:注意力机制的核心原理是通过动态计算输入元素间的相关性权重,实现选择性聚焦与上下文感知的信息整合。注意力机制打破传统序列模型的固定计算模式,显式建模任意距离的依赖关系,成为 Transformer 及大模型处理长上下文、多模态数据的核心基础。其核心概念包括:
Query-Key-Value(QKV)模型:将输入映射为查询(Query)、键(Key)和值(Value),Query与Key计算相似度(如点积),生成注意力权重后加权聚合Value;
- 软性注意力:通过Softmax归一化权重,实现可微分的动态聚焦(如关注句子中关键词语);
- 自注意力(Self-Attention):同一序列同时作为Q/K/V来源,捕获内部依赖关系(如Transformer中词与词的交互);
- 缩放机制:通过维度缩放避免点积分数过大导致梯度消失;
RDMA(远程直接内存访问)与 IB(InfiniBand):RDMA 是一种绕过CPU、直接通过网络访问内存的技术,而 IB 是支持 RDMA 的高性能网络协议。在LLM训练中,两者通过超低延迟(微秒级)和高带宽(如400Gbps)加速多GPU节点间的数据通信(如梯度同步AllReduce),避免传统TCP/IP的CPU瓶颈,显著提升分布式训练效率(如千卡集群训练GPT-3时,RDMA+IB可降低通信延迟50%以上);
NVIDIA:NVIDIA通过硬件与软件协同设计加速LLM训练,其GPU(如H100)搭载Tensor Core支持FP8/FP16混合精度计算,将矩阵运算速度提升10倍以上;NVLink/NVSwitch实现GPU间900GB/s超高速互联,消除多卡通信瓶颈;CUDA生态(如cuDNN、Megatron-LM)优化注意力机制等核心算法,结合HBM3显存(3TB/s带宽)高效加载百亿参数。8台DGX H100可通过NVLink全互联拓扑将175B模型训练速度较CPU集群提升10倍,核心原理是并行计算、通信优化、混合精度三位一体的加速架构;
训练数据集:大模型训练通常使用多样化的数据,包括网页文本(如Common Crawl)、书籍、学术论文、代码(如GitHub)、百科(如Wikipedia)、对话数据(如论坛、客服记录)和多模态数据(如图文配对数据)。数据需经过清洗(去重、去噪、过滤低质量内容)和标准化(统一格式、语言检测)以提高质量。
token 分词:分词是将文本切分为最小语义单元(token)的过程,常见技术包括基于规则的分词(按空格/标点切分,简单但灵活性差)和子词分词(平衡词汇表与未登录词问题),后者主流方法有 BPE(统计高频字符对合并,如 GPT)、WordPiece(概率合并子词,如 BERT)、Unigram LM(逆向优化词表,如 T5),以及支持多语言的 BBPE(字节级 BPE)和 SentencePiece(无预分词,可定制算法)。核心目标是通过子词拆分(如"running"→"run"+“ing”)在有限词表内高效表示多样文本,同时解决多语言、生僻词和语义保留问题。
浮点精度:在深度学习和高性能计算中,浮点精度(Floating-Point Precision)直接影响模型的训练/推理速度、内存占用和数值稳定性。精度越低,计算效率越高,但数值误差风险越大,需结合硬件支持(如 Tensor Core)、算法优化(混合精度、梯度缩放)和任务需求选择。常见精度包括:
- FP32(单精度浮点):32 位存储(1 符号位 + 8 指数位 + 23 尾数位),数值范围广(~1e-38 到 ~1e38),计算稳定,但内存和计算开销较大,传统训练默认精度。
- FP16(半精度浮点):16 位存储(1+5+10),内存和计算量减半,但数值范围窄(~6e-5 到 ~6e4),易出现梯度下溢/溢出,需配合混合精度训练动态缩放梯度。
- FP8(8 位浮点):新兴格式(如 E5M2 / E4M3),显存占用仅为 FP32 的 1/4,专为 AI 加速设计(如 NVIDIA H100),但量化误差显著,需硬件支持,多用于推理或特定训练场景。
- 其他变体:BF16(Brain Float):16 位(1+8+7),指数位同 FP32,牺牲尾数精度换取范围,适合训练(如 TPU/A100)。TF32(TensorFloat):19 位(1+8+10),兼顾 FP32 范围和 FP16 速度,NVIDIA Ampere 架构专用。
混合精度:混合精度(Mixed Precision)是一种通过同时使用FP16(半精度)和 FP32(单精度)来加速深度学习训练的技术:在正向传播和反向传播时使用 FP16 减少计算和内存开销,而在存储权重、梯度累加等关键步骤保留FP32以保证数值稳定性,并通过动态梯度缩放(Grad Scaling)防止 FP16 下的梯度下溢。该技术可显著提升训练速度(如 NVIDIA GPU 利用 Tensor Core 加速)且基本不影响模型精度,被广泛应用于现代大模型训练(如 PyTorch AMP 模式)。
混合精度(FP8) 是指以 8位浮点(FP8) 为核心,结合更高精度(如FP16/FP32)进行计算的优化技术。计算阶段使用FP8(如E4M3或E5M2格式)加速矩阵运算,降低显存占用和计算开销(相比FP16,吞吐量翻倍);关键步骤(如权重更新、梯度累加)仍保留FP16/FP32,避免因FP8数值范围过小(~1e-6到~1e4)导致的精度损失或溢出;动态量化(如NVIDIA H100的Transformer Engine)自动调整FP8缩放因子,平衡效率和数值稳定性。
FP8的E4M3和E5M2:FP8的E4M3和E5M2格式 是两种8位浮点数的二进制编码标准,通过调整指数位(Exponent)和尾数位(Mantissa)的分配来平衡数值范围和精度。E4M3 牺牲范围换精度,减少累积误差;E5M2 牺牲精度换范围,避免溢出。
损失函数(Loss Function) 是衡量模型预测结果与真实值差异的数学指标,用于指导模型优化(如梯度下降)。核心作用:量化模型误差,驱动参数更新,不同任务需针对性选择(如分类任务优先交叉熵,回归任务常用MSE)。主要分类及场景包括:
- 回归任务:均方误差(MSE,预测连续值,如房价)、平均绝对误差(MAE,抗离群点);
- 分类任务:交叉熵损失(Cross-Entropy,二分类用BCE,多分类用CE,如图像分类)、合页损失(Hinge Loss,支持向量机);
- 复杂场景:对抗训练:生成对抗网络(GAN)中的判别器损失;多任务学习:多个损失的加权组合(如目标检测同时优化分类和定位损失);
大模型训练常见损失函数:在大模型训练中,常见的损失函数主要包括:交叉熵损失(用于自回归生成和掩码语言建模,如GPT、BERT)、对比损失(如InfoNCE,用于CLIP等对比学习任务)、对齐损失(如RLHF中的PPO损失,优化人类偏好)、多模态联合损失(如图文匹配损失),以及蒸馏损失(模型压缩时用KL散度模仿教师模型)。这些损失函数通常针对不同任务设计,但实际训练中常组合使用(如预训练同时用MLM损失和对比损失),核心目标是优化模型输出分布与期望目标的匹配程度。
分布式训练:分布式训练是通过多台设备(如GPU/TPU)并行计算来加速大模型训练的技术,核心思想是将数据、模型或计算流程拆分到不同设备上协同工作。
分布式训练并行策略:分布式并行训练通过拆分计算/数据,解决单卡内存不足和计算效率问题。分布式训练的常见并行策略如下所示:
- 数据并行(如PyTorch的DistributedDataParallel):多卡同时处理不同数据批次,通过AllReduce同步梯度(如单机8卡训练ResNet,每卡计算1/8数据的梯度后聚合);
- 模型并行:
- 张量并行:将矩阵运算按列/行拆分到多卡(如GPT-3的Attention层权重分到4卡计算);
- 层并行:模型不同层分配到不同设备(如将Transformer的24层分到3台机器,每台负责8层);
- 流水线并行(如GPipe):模型按层分阶段,微批次流水执行(如 BERT的12层分到4卡,每卡处理3层,类似工厂流水线);
- 混合并行(如DeepSpeed):结合上述策略(如训练175B参数的GPT-3时,同时使用数据+张量+流水线并行);
监督微调(Supervised Fine-Tuning, SFT):监督微调是在预训练大模型(如 LLM、CV模型)的基础上,使用标注数据对模型进行有监督训练,使其适应特定任务(如文本生成、分类等)。
- 输入:预训练模型(如GPT-3、BERT) + 任务标注数据(如问答对、分类标签);
- 训练:通过标准损失函数(如交叉熵)微调模型参数;
- 输出:任务适配的模型(如客服对话模型、医学文本分类器);
监督微调(SFT)分类:从通用预训练模型出发,通过标注数据定向优化,平衡任务性能、领域适应性与计算成本。主要分为以下五类:
- 任务适配型:针对单一任务(如文本分类)微调,例如用情感分析数据微调BERT;
- 指令微调:训练模型遵循指令(如对话生成),典型如Alpaca数据集微调LLaMA;
- 领域适配型:垂直领域强化(如医疗、法律),例如用医学文献微调BioBERT;
- 多任务型:联合优化多个任务(如翻译+摘要),如T5的统一微调框架;
- 高效参数型:低资源微调(如LoRA、Adapter),冻结大部分参数,仅训练少量新增模块;
上下文窗口扩展:实现上下文窗口扩展需结合位置编码改进(如RoPE插值)、注意力优化(如滑动窗口)、渐进训练和工程技巧(如分块计算)。单纯扩展窗口可能牺牲局部细节,需平衡长度与语义一致性。当前主流方案如下所示:
- 小规模扩展(4K→32K):直接外推或插值(如NTK-RoPE);
- 超长上下文(100K+):需稀疏注意力+分块训练(如YaRN);
旋转位置编码(RoPE, Rotary Position Embedding):RoPE 是一种通过旋转矩阵将位置信息融入注意力机制的方法,其核心思想是将词嵌入向量在复数空间中按位置角度旋转,使模型能够显式捕捉 token 之间的相对位置关系。具体实现中,RoPE 通过构造旋转矩阵对Query和Key向量进行位置相关的变换(如θ_i = i/10000^(2d/D),其中i为位置索引,d为维度),从而在计算注意力分数时自动保留相对位置信息。相比传统绝对位置编码(如BERT的固定位置嵌入),RoPE具有更好的长度外推性和对称性(如相对距离不变性),被广泛应用于 LLaMA、GPT-Neo 等大模型,并成为长上下文扩展技术(如YaRN、NTK插值)的基础。
YaRN:YaRN(Yet another RoPE-based method for context window Extension) 是一种基于旋转位置编码(RoPE)的上下文窗口扩展技术,通过动态调整 RoPE 的波长(频率)和渐进式训练策略,显著提升模型对长序列的处理能力。YaRN以低成本和高效性成为当前长上下文扩展的主流方案之一,被DeepSeek、Mistral等模型采用。其核心创新包括:
- 波长插值:将RoPE的基频(base frequency)按序列长度动态缩放,避免外推时的位置编码失真;
- 温度缩放:引入温度系数平衡高频(局部)和低频(全局)位置信息的权重;
- 渐进训练:分阶段增加序列长度(如从4K→128K),稳定模型对长上下文的适应;
ALiBi:ALiBi(Attention with Linear Biases) 是一种用于 Transformer 语言模型的位置编码方法,旨在改进模型对长序列的处理能力,特别是在推理时外推(extrapolate)比训练时更长的序列。它由 Ofir Press 等人在 ICLR 2022 上提出,并因其简单高效而受到广泛关注。传统 Transformer 使用绝对位置嵌入(如 Sinusoidal)或相对位置编码(如 RoPE),而 ALiBi 采用线性偏置(Linear Biases) 来隐式编码位置信息。它不依赖显式的位置嵌入,而是通过在注意力计算时添加一个固定的线性偏置矩阵来模拟位置关系。
强化学习(Reinforcement Learning, RL):强化学习是一种通过与环境交互学习最优策略的机器学习方法,其核心是智能体(Agent)在环境(Environment)中采取动作(Action)并获得奖励(Reward),以最大化长期累积收益(如折扣回报)。核心原理基于马尔可夫决策过程(MDP),包括状态(State)、动作空间、奖励函数和状态转移概率;主要分类包括:
- 基于价值(Value-Based):学习状态或动作的价值函数(如Q-Learning、DQN),通过贪心策略选择动作;
- 基于策略(Policy-Based):直接优化策略函数(如 REINFORCE、PPO),适用于连续动作空间;
- Actor-Critic:结合价值函数和策略梯度(如A3C、SAC),平衡偏差与方差;
- 模型-Based(Model-Based):学习环境动力学模型(如MuZero),辅助规划;
PPO(Proximal Policy Optimization,近端策略优化):PPO 近端策略优化是一种基于策略梯度的强化学习算法,其核心思想是通过限制策略更新的幅度来平衡训练稳定性与效率。PPO采用裁剪(Clipping)机制,强制新旧策略的差异比率(Probability Ratio)保持在预设范围内(如[0.8, 1.2]),避免因过度更新导致的策略崩溃;同时结合优势函数(Advantage Function)(如GAE)来减少方差,提升样本利用率。PPO的优势在于易于实现、适应性强(支持离散/连续动作空间),成为强化学习微调大模型(如RLHF中的ChatGPT)的主流方法,典型变体包括PPO-Clip(默认)和PPO-Penalty(基于KL散度约束);
PPO(近端策略优化)与DPO(直接偏好优化):PPO 和 DPO 都是策略优化方法,但实现原理和适用场景不同:PPO是通用强化学习算法,通过环境交互获得奖励信号,采用策略裁剪和优势函数来稳定训练,适合需要动态交互的任务(如游戏控制);而DPO则专为人类偏好对齐设计,直接利用偏好数据(如A/B选择对)构建损失函数,省去显式奖励建模,更高效地优化模型输出(如对话微调)。两者核心差异在于PPO依赖在线强化学习流程,而DPO通过概率建模实现离线优化,适合不同的任务需求。
Inference-time scaling:Inference-time scaling(推理时缩放)指在大型语言模型(LLM)推理阶段(生成文本时)通过调整参数或策略来控制模型输出的行为,而无需重新训练模型。其核心目的是在推理阶段动态优化生成结果的质量、多样性或计算效率。
大模型评估(LLM Evaluation):大模型评估是系统化衡量模型在能力、安全性、鲁棒性等方面的表现,确保其符合实际应用需求。评估贯穿模型研发全流程(预训练→微调→部署),核心目标是模型是否足够智能、可靠、无害;
大模型评估体系:大模型评估体系是通过多维指标和动态测试系统化衡量模型性能、安全性与可用性的框架,核心包含三类方法:
- 自动化基准测试(如MMLU、HELM)量化语言理解、推理等能力,结合指标(BLEU、ROUGE)评估生成质量;
- 人类对齐评估(如人工标注、Red Teaming)检测有害输出与价值观偏差;
- 交互式压力测试(如Chatbot Arena对抗对话)验证实际场景鲁棒性。创新方法包括基于LLM的裁判(GPT-4打分)、实时安全过滤(SafeDecoding),形成“数据+人工+对抗”的全链路评估闭环,确保模型可靠落地;
大模型评估分类与发展趋势:大模型评估主要分为能力评估(如MMLU综合知识、HumanEval衡量代码生成)、安全评估(如ToxiGen检测有害内容、对抗性提示测试)和效率评估(如推理延迟、显存占用测算)。当前面临评估维度复杂(如伦理边界模糊)、动态场景覆盖不足等挑战;未来趋势聚焦多模态评估(文本+图像/视频)、轻量化工具链(如OpenCompass)和在线持续监控体系,以支撑模型规模化落地中的性能-安全-成本平衡需求;
大模型核心应用:大模型核心应用覆盖生成、交互与决策三大方向,具体方向如下所示:
- 智能对话(如ChatGPT)提供拟人化问答与客服支持;
- 内容生成(如GPT-4文本创作、Stable Diffusion图像生成)赋能创意生产;
- 多模态任务(如Gemini图文理解、Video-LLaMA视频摘要)实现跨模态分析;
- 智能代理(如AutoGPT)通过工具调用自主完成复杂任务(数据分析、流程自动化);
- 垂直领域优化(如医疗BioGPT、金融FinBERT)推动专业场景落地;
大模型核心应用框架:应用框架以 Transformer 为基础,通过输入层(多模态数据编码)、推理层(自注意力机制)和输出层(生成/决策)实现端到端任务处理;