导读
本文尝试以一种偏“杂谈”的方式,围绕大模型推理部署中的几个关键技术节点,梳理其演进脉络与核心动机。

最早的大模型部署,基本沿用了传统深度学习时代的思路:通过对不同请求进行 padding,再采用 Static Batching 的方式进行推理。这种方式实现简单,但在请求长度不一致、并发复杂的场景下,资源利用率较低。
随后,优化开始从模型计算本身切入,以 Flash Attention 为代表的一系列技术被提出,通过对 Attention 计算进行 tile-based 重排,大幅降低了显存访问和计算开销,成为推理性能提升的重要里程碑。
在此基础上,系统层面的优化逐渐成为重点,Continuous Batching 引入了更细粒度的调度机制,PagedAttention 实现了更精细的 KV Cache 显存管理,而 Chunked Prefill 则有效缓解了 Prefill 阶段对 Decode 流水线的阻塞问题。
随着这些能力逐步成熟,PD(Prefill / Decode)分离 的推理架构开始成型,并逐渐成为主流方案。
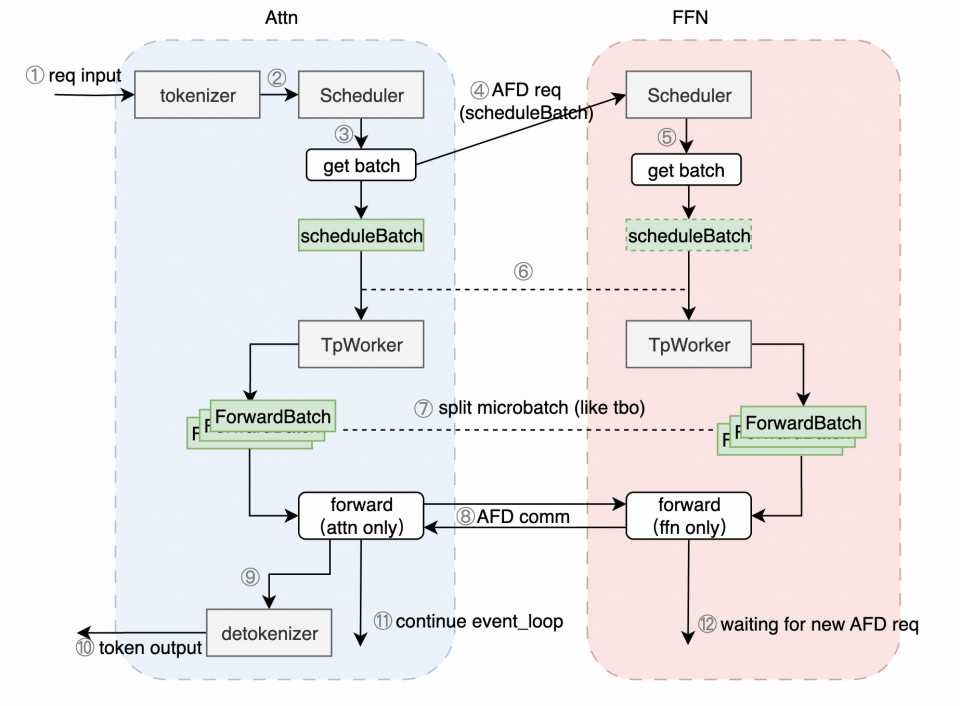
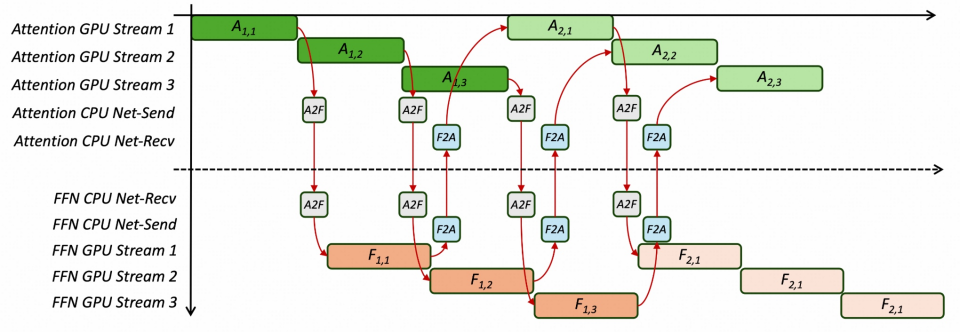
进入近一年,为了进一步挖掘模型不同阶段、不同算子的计算特性,提升整体系统效率,AF(Attention / FFN)分离 开始成为新的演进方向。通过更细粒度地解耦模型计算路径,系统能够在调度、并行和资源分配层面获得更高的灵活性。
总体来看,大模型推理部署技术的演进,本质上是一条软硬件协同设计的路径:通过不断拆分问题、细化调度、重构架构,持续优化分布式系统在大模型推理场景下的综合性能。
背景
Transformer 模型的推理并非单一形态的计算负载,而是明显分为 Prefill 与 Decode 两个阶段。
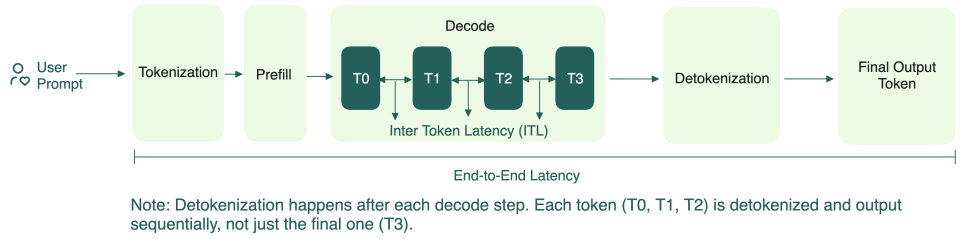
Prefill 阶段主要处理输入 Prompt,计算形态以矩阵–矩阵乘法(GEMM)为主,算术强度高,能够充分利用 GPU 的 Tensor Core,整体表现为 Compute-bound。
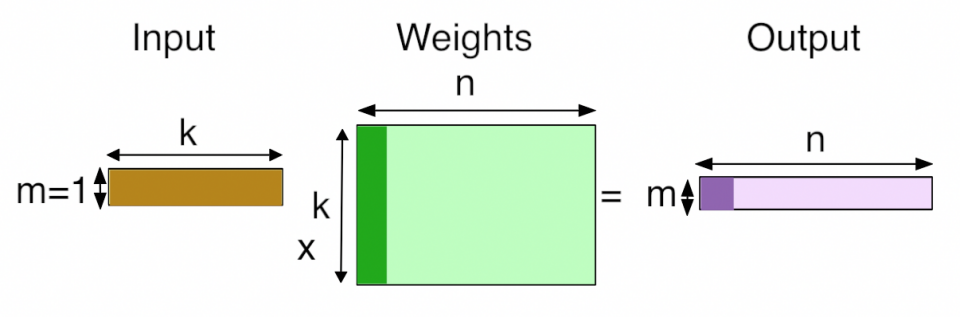
进入 Decode 阶段后,模型转为自回归生成。每生成一个 Token,都需要访问历史 Token 对应的 KV Cache,计算模式退化为矩阵–向量乘法(GEMV),算力需求较低但对显存带宽高度敏感,典型属于 Memory-bound 场景。
随着生成序列增长,KV Cache 体积线性膨胀。以 70B 模型、128K 上下文为例,KV Cache 可达数 GB 甚至数十 GB。此时,每生成一个 Token 都需要在显存中搬运大量数据,而实际计算量却很小,带宽成为主要瓶颈。
从模型结构角度看,计算可进一步拆分为 Attention 与 FFN(MLP / MoE) 两部分。Attention 负责建模 Token 间依赖,是 KV Cache 的主要驻留位置,也是长上下文推理中的显存与带宽瓶颈;其计算复杂度从早期的 N 二次方,演进到 Flash Attention 之后的近线性。
FFN 部分则承载了模型的大部分参数量:在标准 Transformer 中通常超过 2/3,在 MoE 模型中甚至可达 90% 以上。它是模型“知识密度”最高的部分,也是参数规模膨胀的主要来源。
最后,在多用户推理场景下,为了提升 GPU 利用率与系统吞吐,Batching 是不可或缺的基础能力,也是后续一系列调度与架构优化的前提。
Flash Attention
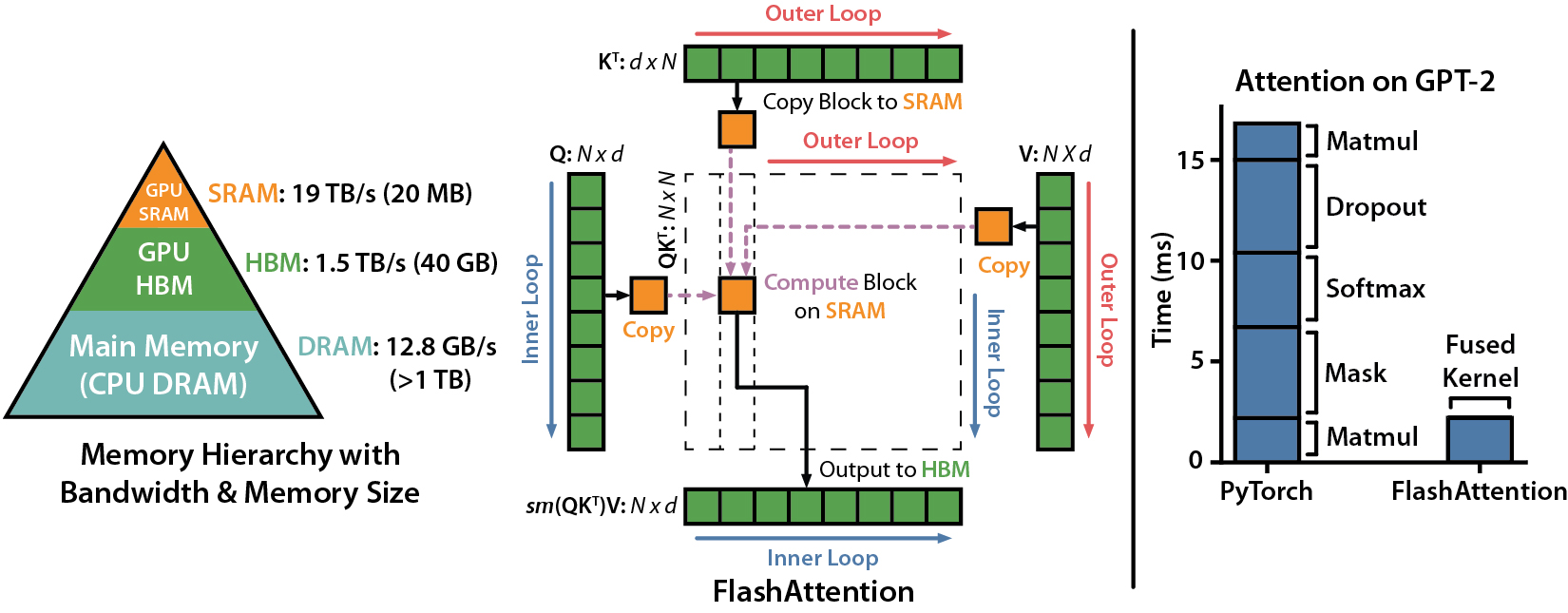
在讨论系统级调度之前,必须先回到一个基础性技术——Flash Attention(FA)。它并非简单的性能优化手段,而是大模型推理得以规模化部署的关键前提。从本质上看,Flash Attention 在保持与原始 Attention 计算等价的前提下,通过 tile-based 的 Softmax 计算,彻底重构了 Attention 的数据访问模式。
在讨论系统级调度之前,必须先回到一个基础性技术——Flash Attention(FA)。它并非简单的性能优化手段,而是大模型推理得以规模化部署的关键前提。从本质上看,Flash Attention 在保持与原始 Attention 计算等价的前提下,通过 tile-based 的 Softmax 计算,彻底重构了 Attention 的数据访问模式。
在 2022 年之前,Transformer 注意力机制 O(N²) 级别的显存占用与访存开销,严重限制了上下文长度的扩展,8K 甚至 32K 上下文在工程上都极具挑战。Flash Attention 通过将 Attention 计算拆分为可复用的 tile,使得中间结果尽量驻留在 SRAM 中,从根本上缓解了显存带宽瓶颈,成为长上下文推理的“解锁器”。
Flash Attention 的持续演进,本质上是对 NVIDIA GPU 架构特性的深度适配过程:
- FA1:通过 Tiling 与重计算策略,将原本 O(N²) 的 HBM 访问转化为片上 SRAM 操作,首次显著降低带宽压力;
- FA2:面向 Ampere 架构,引入 Sequence 维度并行,并将任务划分至 Warp 级粒度,减少 Thread Block 同步开销,提升整体 Occupancy;
- FA3:针对 Hopper 架构,利用 TMA 实现异步数据搬运,结合 WGMMA 指令,在 Warp Group 层面实现 GEMM 与 Softmax 的深度流水线重叠,进一步压榨硬件效率。
总体来看,Flash Attention 并不是“锦上添花”,而是通过软硬件协同设计,重新定义了 Attention 的可实现方式,为后续一切系统级调度与架构优化奠定了基础。
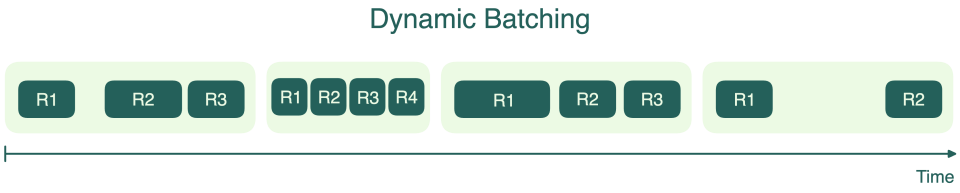
Static batching
为应对早期大模型推理的计算负载,在 2021–2022 年 的生产环境中,部署 GPT-3、BLOOM 等模型的主流方案,通常采用 NVIDIA Triton 推理服务器 + FasterTransformer 引擎 的组合(这里的 Triton 指 NVIDIA Triton Server,与 OpenAI Triton 语言无关)。
在该架构中,Triton Server 作为前端维护请求队列:系统会等待请求数量达到预设的 Batch Size,或等待超时(如 50ms),然后将这一批请求打包成一个大的 Tensor,统一送入 GPU 推理。这种设计本质上沿袭了深度学习训练阶段的 Static Batching 思路。
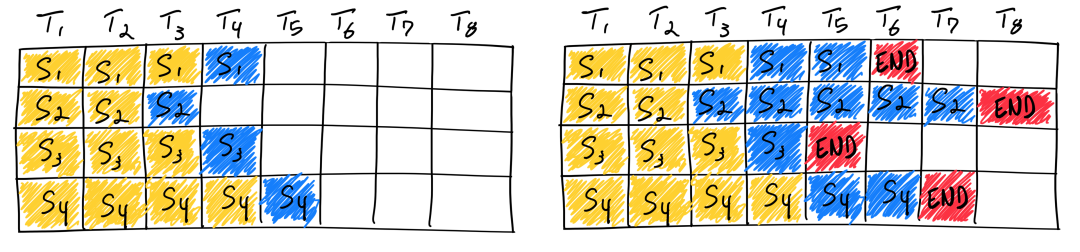
然而,随着 LLM 推理逐渐成为主流,这种方案的局限性迅速暴露。与训练不同,LLM 推理具有强烈的“变长”特征:不同请求的 Prompt 长度差异巨大,生成长度更是不可预测。
在静态批处理框架下,为了利用 GPU 并行性,系统必须以 Batch 中的最长序列为基准,对所有请求进行 Padding。结果是大量 dummy token 被引入,不仅浪费了宝贵的显存容量,也使 GPU 的算力被消耗在无效的“零计算”上。
更严重的问题在于 请求间的相互阻塞。整个 Batch 的端到端延迟完全由生成长度最长的请求决定:即便某个请求只需生成 10 个 Token,也必须在显存中“陪跑”,直到那个需要生成 1000 个 Token 的请求结束。
最终,这种粗粒度的调度方式导致显存碎片化严重、吞吐被锁死在低位,单位 Token 的生成成本居高不下,已无法满足大规模、多用户 LLM 推理的需求。
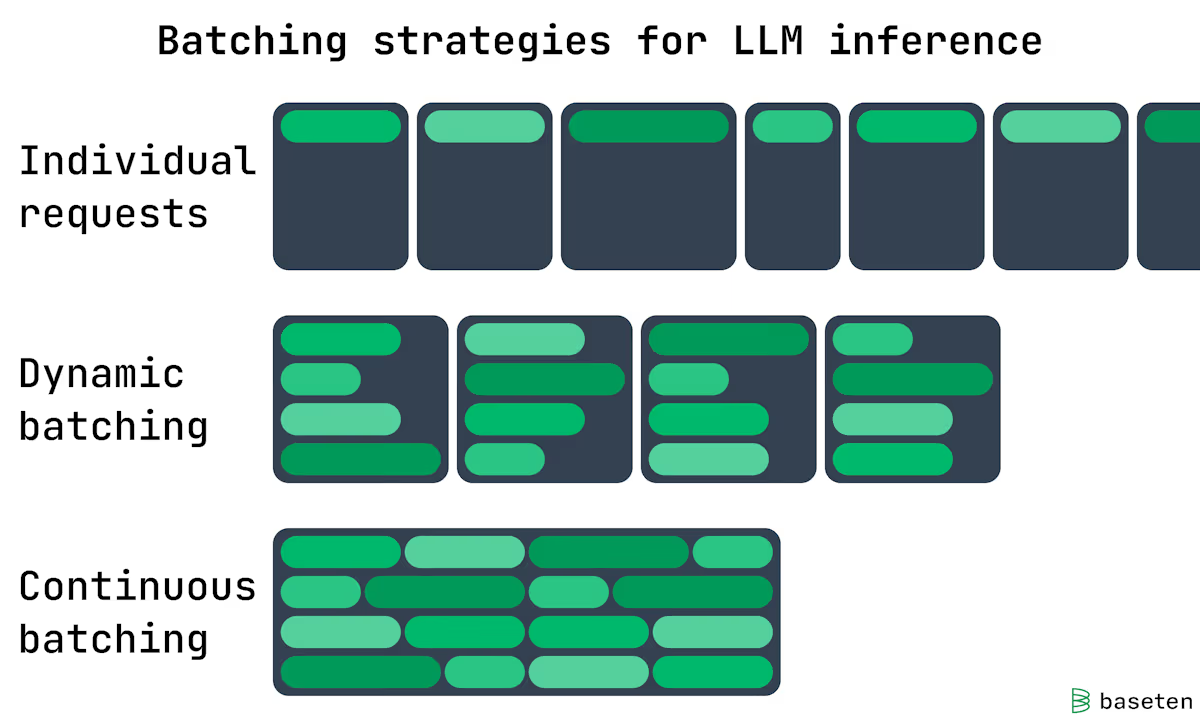
Continuous Batching
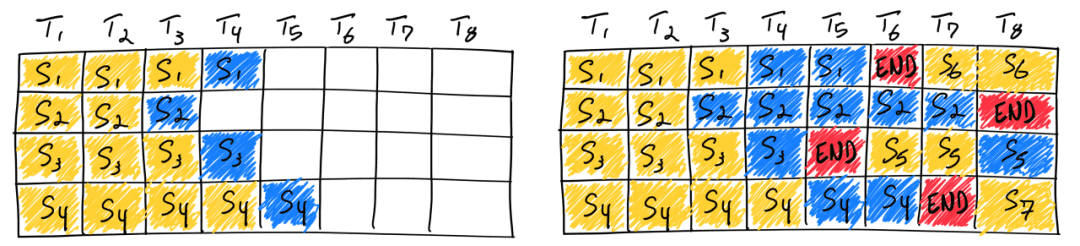
Static batching 这种低效的静态批处理并未持续太久,Continuous Batching 很快成为主流方案。
其核心思想是:调度不再以 Batch 为单位,而是以 Token 为单位推进。在每一次 Token 生成迭代后,调度器都会检查是否有请求完成;一旦某个请求结束,立即释放其占用的显存槽位,并从等待队列中拉取新的请求补位,使 GPU 的有效 Batch Size 始终维持在硬件允许的上限,最大化流水线利用率。支撑这一调度模式的关键底层技术是 PagedAttention。
在传统 PyTorch 实现中,KV Cache 通常要求在显存中 连续分配,这在动态加入和释放请求时极易造成严重的显存碎片。而 PagedAttention 借鉴了操作系统 虚拟内存分页 的思想,将 KV Cache 切分为固定大小的 Block(例如每块存放 16 个 Token)。逻辑上连续的 KV Cache,在物理显存中可以是非连续的,通过维护一张 Block Table 记录逻辑块到物理块的映射关系。
这种设计使得请求可以被灵活插入与回收,为 Continuous Batching 提供了必要的显存管理基础。
这一阶段的代表性系统是 Orca 与 vLLM,它们共同奠定了现代大模型推理调度的基本范式。
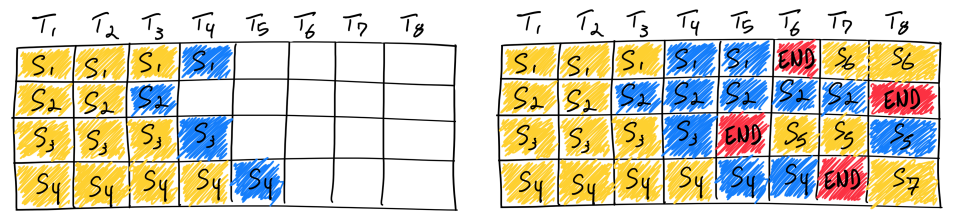
Chunked Prefill

随着应用场景向长文档分析演进,Context Length 快速增长,新的系统瓶颈随之出现。如前所述,大模型推理分为 Prefill 与 Decode 两个阶段。在早期部署中,这两个阶段通常在 同一张 GPU 上执行。当一个长上下文请求(如 32K)进入 Prefill 阶段时,会在短时间内占满 GPU 计算资源,导致其他正在进行 Decode 的请求被迫暂停。用户侧的直观感受,就是原本流畅的逐 Token 输出出现明显卡顿。
为缓解这一问题,Chunked Prefill(分块预填充) 被提出。该方法不再一次性完成整个长 Prompt 的 Prefill,而是将其拆分为多个较小的 Chunk,并与 Decode 阶段交错执行。
在每个调度周期中,GPU 同时处理 一个 Prefill Chunk + 多个 Decode 请求,将原本集中的 Prefill 计算开销摊分到多个 Decode 迭代中,从而显著平滑系统的整体延迟,改善用户的交互体验。
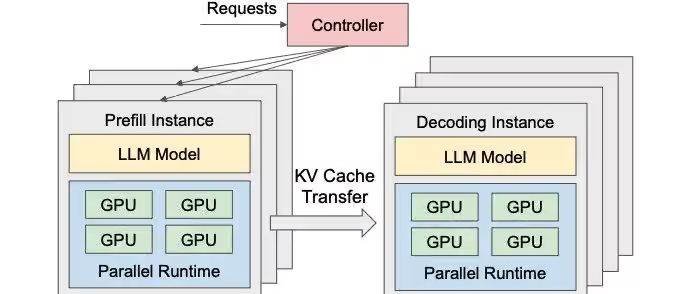
PD 分离
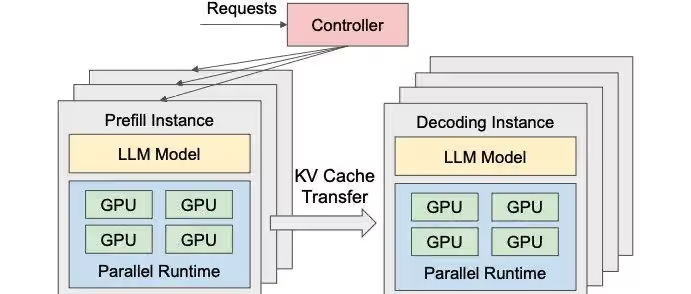
随着模型规模持续扩大,将 Prefill 与 Decode 两个阶段部署在同一节点上的矛盾日益突出。两者截然不同的计算特性,对物理硬件提出了相互冲突的需求:Prefill 偏 Compute-bound,而 Decode 偏 Memory-bound。强行共置,往往导致 Tensor Core 或显存带宽二选一被浪费。
在这一背景下,PD 分离(Prefill / Decode Disaggregation) 逐渐成为主流架构。需要强调的是,这里的 PD 分离并非算法层面的阶段划分,而是部署与资源层面的物理解耦。
在 DistServe 等系统的推动下,推理集群被拆分为两个独立的资源池:
- Prefill Instances 专注于高吞吐地处理 Prompt 并生成 KV Cache;
- Decode Instances 仅负责接收 KV Cache,进行自回归 Token 生成。
这种架构允许对硬件进行差异化配置:Prefill 节点可选用算力强的 GPU(如 H800)以最大化计算吞吐;Decode 节点则可选用显存带宽更高或成本更优的 GPU,专注于高效生成 Token。Prefill 完成后,KV Cache 通过 RDMA 等高速通道传输至 Decode 节点。
物理解耦显著提升了系统吞吐与资源利用率,但新的瓶颈也随之出现:KV Cache 传输带宽。在大 Batch、长 Context 场景下,KV Cache 规模极其庞大(例如 70B 模型、128K Context 时可达数 GB),对网络与内存系统形成巨大压力。这一阶段,并行策略成为重要的探索方向:如在 Prefill 阶段采用 Pipeline Parallelism 扩展上下文长度,在 Decode 阶段采用 Tensor Parallelism 降低生成延迟。
值得一提的是,面对 PD 分离带来的带宽挑战,Mooncake(Kimi 背后的架构) 提出了一种 以 KV Cache 为中心的部署范式。该系统利用 GPU 集群中闲置的 CPU DRAM 乃至本地 NVMe SSD,构建全局分布式 KV Cache 池,并通过 RDMA 与 GPUDirect 实现 GPU 显存、CPU 内存之间的高速数据搬运。
在这一设计中,热数据驻留在 HBM,温数据位于 CPU DRAM,冷数据落盘至 SSD,KV Cache 被像数据库一样进行分级管理,为大规模推理提供了新的系统解法。
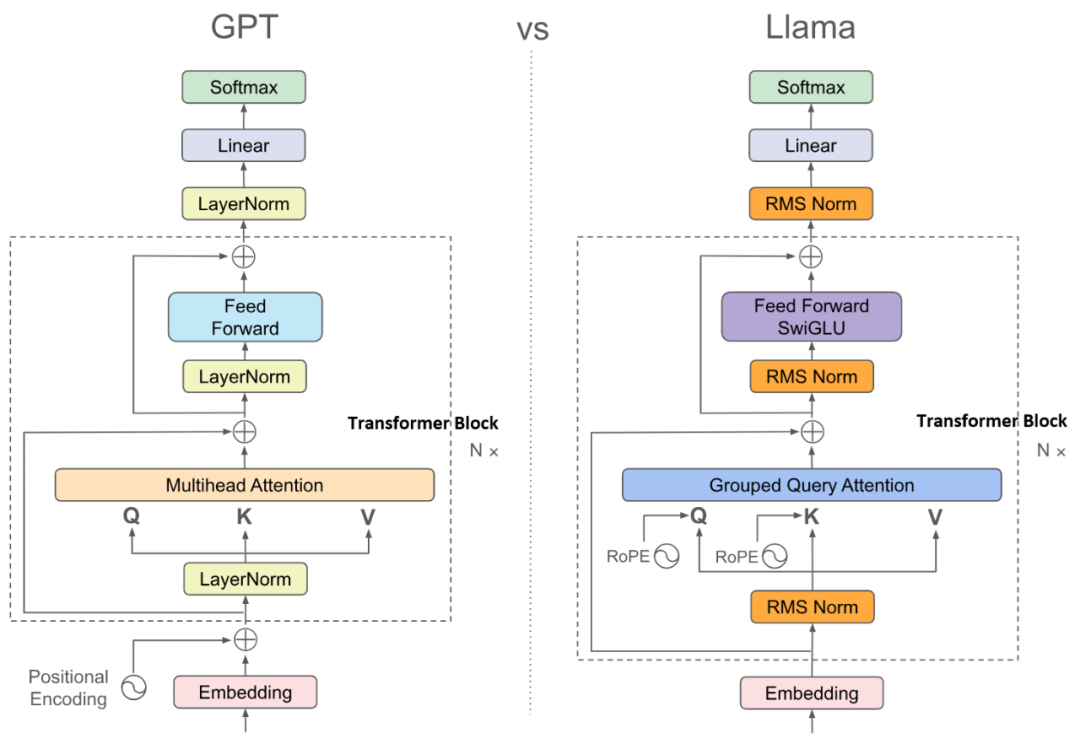
AF 分离
随着 MoE(Mixture of Experts) 架构逐渐成为主流,大模型推理再次遭遇新的系统级挑战。MoE 的核心特征在于:FFN / MLP 部分拥有极其庞大的专家权重,但单次推理仅激活其中一小部分专家。从计算视角看,专家本质上是由若干全连接层构成的子模块,其激活粒度是 per-token 的。在大 Batch 场景下,由于统计效应,绝大多数专家都会被不同 Token 激活。
在传统部署中,Attention 与 Expert 通常共置于同一 GPU:Attention 需要大量显存存放 KV Cache,而 Expert 则消耗显存以承载海量专家权重。两者对显存的竞争,使资源利用效率迅速下降。
需要区分的是:PD 分离 关注的是模型在不同推理阶段(Prefill / Decode)的计算差异;而 AF 分离(Attention / FFN Disaggregation) 则进一步深入到模型内部,针对 Attention 与 FFN 计算与存储特性的根本差异,进行更细粒度的资源解耦。本质上,AF 分离是建立在 PD 分离之上的一次系统级深化。
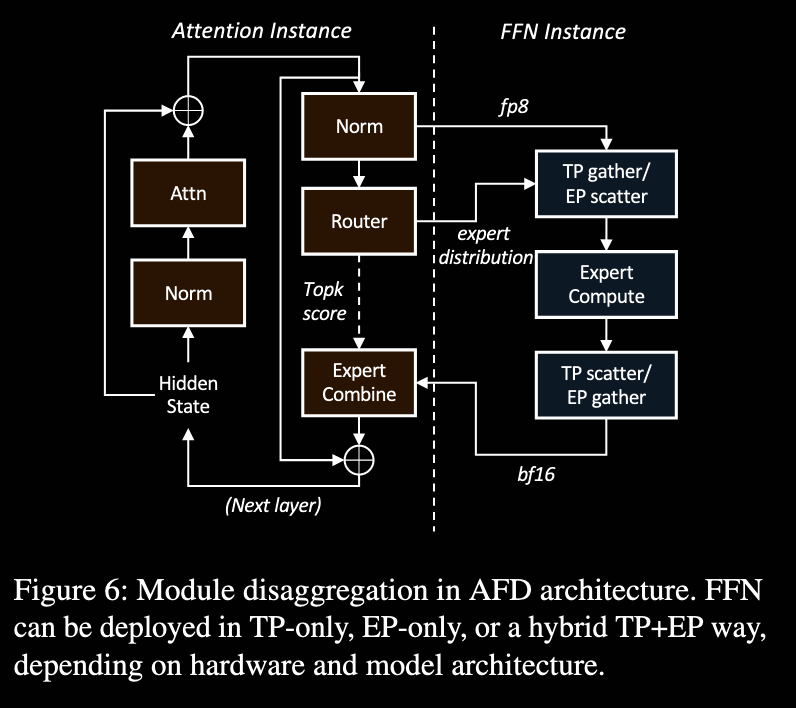
在 AF 分离架构中,Attention 层与 Expert 层被物理拆分,部署在不同的 GPU 集群:
- Attention Cluster 专注于 KV Cache 管理与 Attention 计算;
- Expert Cluster 专注于存储专家权重并执行 FFN 计算。
这种拆分显著提升了系统的灵活性:系统可以根据负载特征独立扩缩两类资源。例如,长上下文任务可增加 Attention 节点以容纳更多 KV Cache;复杂推理任务(激活更多专家)则可增加 Expert 节点以增强 FFN 计算能力。
代价同样明显。AF 分离引入了高频、跨节点的细粒度通信:每一层的 Attention 输出需要发送至 Expert 集群,Expert 计算完成后再回传结果。这是一种 M-to-N、小包高频 的通信模式,迅速成为新的性能瓶颈。
代表性工作 Janus 针对这一问题提出了 Adaptive Two-Phase Communication:首先在 Attention 节点内部,利用 NVLink 将发往同一 Expert 节点的 Token 聚合为大包;再通过 InfiniBand 发送至目标 Expert。借助 Attention / Expert 的物理解耦,调度器还可在 Expert 集群中动态选择负载最低的副本,实现 微秒级负载均衡。
性能指标
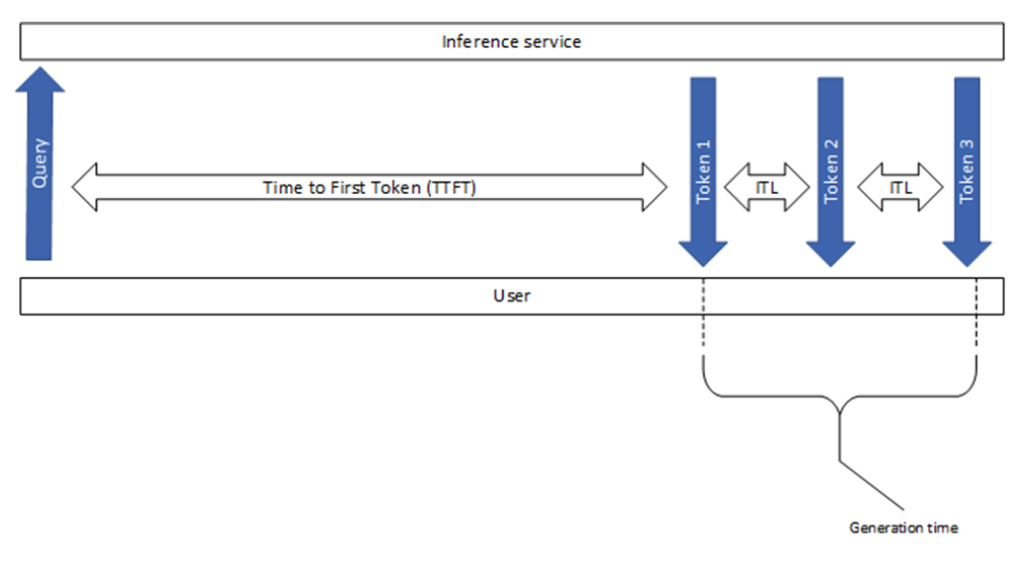
- TTFT(Time To First Token):指从用户发出请求到模型生成第一个 token 所花费的时间,用于衡量 prefill 阶段的性能。
- TBT(Time Between Tokens):指连续生成两个 token 之间所花费的时间,反映每个 token 的生成速度。
- TPOT(Time Per Output Token):指所有输出 token 的平均生成时间,有时也称为 ITL(Inter-Token Latency),反映整体生成效率。
整体响应延迟可用以下公式计算:
总结
大模型推理架构经历了从静态批处理,到 Continuous Batching、PD 分离,再到 AF 分离的演进,本质是围绕 KV Cache 与算力特性进行的软硬件协同优化。