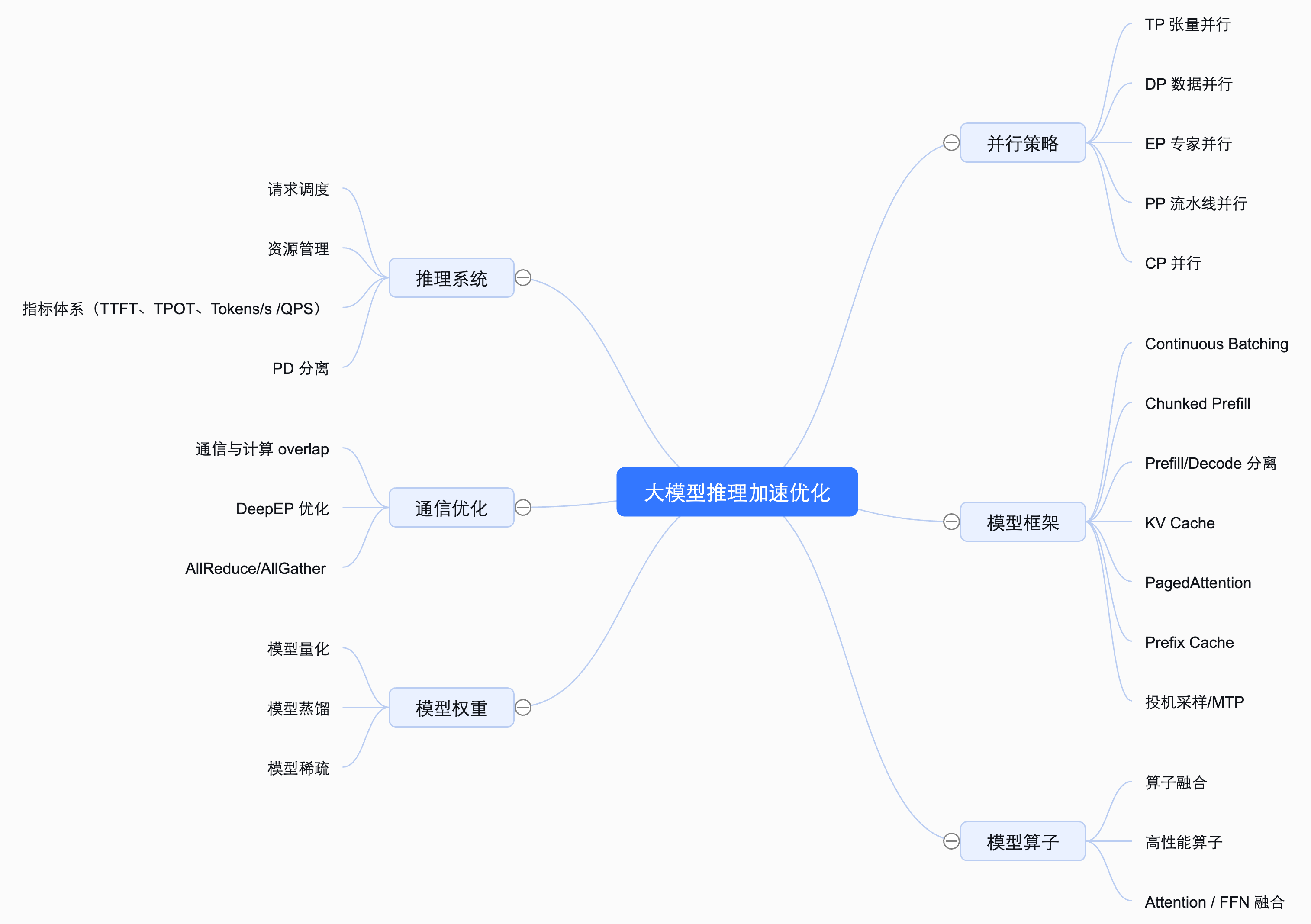
推理常见加速手段
大模型推理的常见加速手段,本质上围绕 “少算、快算、少等、少搬” 四个方向展开:
- 一方面通过算法与模型层优化,如 KV Cache、FlashAttention、Speculative Decoding、量化与裁剪,减少不必要的计算或降低计算精度成本;
- 另一方面在系统与工程层面,借助算子融合、并行化(Tensor / Pipeline / Expert Parallelism)、高效调度与批处理,提升硬件利用率;
- 同时通过内存与数据路径优化,如 KV Cache 复用与 Offload、Paged Attention、NUMA 感知和高速互联(NVLink / RDMA),减少访存和数据搬运开销;
- 最终在部署与服务层,结合请求合并、动态批处理、异构算力协同,实现端到端时延与吞吐的综合最优。
整体如下所示: