国内开源大模型最新动态
从 2025 到 2026.01 这段时间,国内开源大模型蓬勃发展,日益繁荣,我们总结下近期(2025.11-2026.02)国内大模型发展最新动态,如下所示:
| 分类 | 模型名称 | 发布时间 | 下载量 | 模型参数量 | 模型架构 | 模型特性 | 模型链接 |
|---|---|---|---|---|---|---|---|
| LLM | DeepSeek V3.2、DS V3.2 EXP、DS V3.2 Special | 25.12.01 | 101.1k | 685B | MoE | 引入稀疏注意力(DSA)显著降低了计算复杂性,同时保持了模型性能,特别针对长上下文场景进行了优化。Thinking in Tool-Use128k上下文窗口 | DeepSeek-V3.2 |
| Qwen3-Max-Thinking | 26.1.26 | 闭源模型 | 1000B | MoE | 自适应工具调用能力,可在对话中自主按需调用内置的搜索引擎和代码解释器测试时扩展技术:在推理阶段分配额外计算资源以提升模型性能的技术。一种经验累积式、多轮迭代的测试时扩展策略。不同于简单增加并行推理路径数量 NN(这往往导致冗余推理),对并行轨迹数量进行限制并将节省的计算资源用于由“经验提取”机制引导的迭代式自我反思。该机制从过往推理轮次中提炼关键洞见,使模型避免重复推导已知结论,转而聚焦于未解决的不确定性。关键在于,相比直接引用原始推理轨迹,该机制实现了更高的上下文利用效率,在相同上下文窗口内能更充分地融合历史信息。 | qwen3-max-thinking | |
| Kimi- K2-thinking | 25.11.09 | 652.5k | 1000B-A32B | MoE | 原生 INT4 量化模型256k上下文窗口动态调用工具的思维代理 | Kimi-K2-Thinking | |
| GLM-4.7 | 26.12.23 | 50.2k | 358B-A32B | MoE | 核心编码能力提升氛围化编程(Vibe Coding):提升 UI 质量工具使用能力提升复杂推理能力提升:进一步增强了 交错思考(自 GLM-4.5 起引入的功能),并新增了 保留思考 和 轮次级思考。支持200K上下文长度 | GLM-4.7 | |
| GLM-4.7-Flash | 26.1.21 | 77.6k | 30B-A3B | MoE | 30B 级别中最强的模型, 为轻量级部署提供了在性能与效率之间取得平衡的新选择。 | GLM-4.7-Flash | |
| MiniMax-M2.1 | 26.1.23 | 44.9k | 229B-A10B | MoE | 专门针对编码、工具调用、指令遵循和长周期规划等关键能力进行了优化 | MiniMax-M2.1 | |
| 多模态 | GLM-4.6v | 25.12.8 | 3.7k | 106B | - | 上下文窗口扩展至 128k tokens首次集成了原生函数调用(Function Calling)能力 | GLM-4.6V |
| GLM-4.6v-Flash | 26.1.20 | 13.9k | 9B | - | 针对本地部署和低延迟应用优化的轻量级模型 | GLM-4.6V-Flash | |
| Step3-VL | 26.1.20 | 139.2k | 10B | - | 性能媲美甚至超越规模大10-20倍的开源模型,如GLM-4.6V、Qwen3-VL-235B以及闭源旗舰模型如Gemini 2.5 Pro、Seed-1.5-VL高质量多模态语料的统一预训练:在 1.2T token 的多模态语料上采用单阶段、完全非冻结的训练。联合优化感知编码器与 Qwen3-8B 解码器。规模化多模态强化学习与并行推理:两阶段监督微调(SFT)以及超过 1,400 轮次的强化学习(RL),结合可验证奖励(RLVR)和人类反馈(RLHF)。除顺序推理外,还采用了并行协同推理(PaCoRe),在推理时分配计算资源,聚合来自并行视觉探索的证据。 | Step3-VL-10B | |
| DeepSeek-OCR-2 | 26.1.27 | 4.2k | 3B | - | DeepEncoder V2初步验证了使用语言模型架构作为视觉编码器的潜力。这种架构天然继承了LLM社区在基础设施优化方面的成果,如混合专家(MoE)架构和高效注意力机制。**DeepSeek团队认为,这为迈向统一的全模态编码器提供了一条有希望的路径。**未来,单一编码器可能通过配置特定模态的可学习查询,在同一参数空间内实现对图像、音频和文本的特征提取与压缩。DeepSeek-OCR 2所展示的“两个级联的1D因果推理器”模式,通过将2D理解分解为“阅读逻辑推理”和“视觉任务推理”两个互补子任务,或许代表了实现真正2D推理的一种突破性架构方法。视觉因果流:传统视觉语言模型处理图像时,会以「左上到右下」的刚性光栅扫描顺序处理视觉token,忽略语义关联(如表格、公式的非线性布局);而DS-OCR2在 encoder里引入「因果查询 token(causal flow queries)」,让模型先在视觉侧学会「应该按什么顺序看」。 | DeepSeek-OCR-2 | |
| Kimi- K2.5 | 26.1.27 | 6.5k | 1000B-A32B | - | 原生多模态:在视觉-语言 token 上进行预训练,K2.5 在视觉知识、跨模态推理以及基于视觉输入的智能体工具使用方面表现卓越。结合视觉的编程能力:K2.5 能根据视觉规范(如 UI 设计、视频工作流)生成代码,并自主编排工具以处理视觉数据。智能体集群:K2.5 从单智能体扩展演进为一种自导向、协同式的类集群执行方案。它将复杂任务分解为多个并行子任务,由动态实例化的领域专用智能体分别执行。 | Kimi-K2.5 | |
| 造相- Z-Image-Turbo | 26.1.07 | 184.3k | 6B | - | 单流架构Scalable Single-Stream DiT(S3-DiT),许多模型把文字、图片 Token 分开处理,需要复杂的跨模态交互;Z-Image 则直接把文本 Token、视觉语义 Token、VAE Token 全部拼成一个序列**,让模型 “一条龙处理”**。 | ||
| Qwen-Image-2512 | 25.12.31 | 58.7k | - | Qwen-Image 文生图基础模型的 12 月更新版本,增强了人像真实感、自然细节和文字渲染能力 | Qwen-Image-2512 | ||
| Qwen-Image-Edit-2511 | 25.12.23 | 65.7k | - | 在 Qwen-Image-Edit-2509 基础上的增强版本,主要增强包括:减轻图像漂移、提升人物一致性、集成 LoRA 能力、增强工业设计生成能力,以及强化几何推理能力。 | Qwen-Image-Edit-2511 | ||
| 具身智能 | ALpamayo- R1 | 25.12 | 36k | 10B | Nvidia | VLA模型。将因果链推理与轨迹规划相结合,以提升在复杂自动驾驶场景中的决策能力 | Alpamayo-R1-10B |
| GR00T-N1.6 | 25.12 | 22.8k | 3B | Nvidia | 是一个用于通用类人机器人技能的开放视觉-语言-动作(VLA)模型。接受多模态输入,包括语言和图像,以在不同的环境中执行操作任务。 在多样化的机器人数据上进行训练,包括双臂、半类人形和广泛的类人形数据集,这些数据集由真实捕获的数据和使用 NVIDIA Isaac GR00T Blueprint 组件生成的合成数据组成。它可以通过后训练适应特定的实体、任务和环境。 | /GR00T-N1.6-3B | |
| pi0.5_base | 25.09 | 3.25k | / | Physical Intelligence | VLA模型,具备开放世界泛化能力。该模型在机器人演示数据和大规模多模态数据上联合训练,可在未见过的真实世界环境中执行长时程任务。 | pi05_base | |
| pi0.6 | 25.11 | - | / | Physical Intelligence | 该模型延续π0.5 的层次化设计架构,核心逻辑是将复杂任务拆解为高层次子任务规划与低层次连续动作生成两个分层决策过程,实现“感知 - 规划 - 执行”的高效协同。 | 暂未开源 |
注:以上数据来源于 ModelScope、Huggingface。
近期模型新披露的核心特性
注意力机制
注意力机制模仿了人类在处理信息时的选择性关注能力,允许模型在处理输入数据时动态地调整其注意力权重,允许模型在处理信息时专注于关键部分、忽略不相关信息,从而提高处理效率和准确性的机制。
注意力机制通过计算查询向量(Query)、键向量(Key)之间的相似度来确定注意力权重,然后对值向量(Value)进行加权求和,得到最终的输出。
在传统的序列处理模型中,如循环神经网络(RNN)与长短时记忆网络(LSTM),捕捉长距离依赖关系是一个难题。因为随着序列长度的增加,模型很容易丢失早期输入的信息。注意力机制允许模型在序列的不同位置之间建立直接联系,无论这些位置相距多远,都能够有效地捕捉到它们之间的依赖关系。
注意力机制迭代如下所示:
- Self-Attention:只使用一个注意力头来捕捉输入数据中的特征,对于一个输入序列中的某个词,都会与序列中的所有词计算相关性。
- MHA :将输入数据分解为多个子空间,各子空间通过一个独立的注意力头进行处理,从而能够捕捉到输入数据中不同子空间的特征,大幅提升了模型对复杂关系的建模能力;Self-Attention通过Q、K、V扑捉到了输入token长距离依赖关系,KV cache节省了KV的重复计算,但长上下文场景显存占用仍然很大,因此演变到MQA与GQA
- MQA (多请求注意力,Multi-Query Attention):核心旨在减少计算开销和显存占用,同时保持一定的模型性能。在MHA中每个注意力头都有独立QKV矩阵,这使得每个头可以独立学习输入中的不同特性,而MQA核心是让所有注意力头共享同一份KV矩阵,仅保留Query的多头性质。使得KV Cache 显著减少,适合长序列推理;计算和通信开销减少,推理速度提升 40-50%;但缺点是共享 K 和V 可能导致模型捕捉上下文的能力下降,任务效果略有损失;
- GQA(分组请求注意力,Group-Query Attention):GQA作为折衷方案,通过将Q分组,每组共享一组KV矩阵,旨在在计算效率和模型性能之间取得平衡。
- MLA(多潜头注意力,Multi-Head Latent Attention):核心是通过**低秩分解技术将KV投影到低维潜在空间****,在推理过程中仅缓存潜向量,而不缓存完整的KV****,**规避了GQA和MQA的查询的信息损失,从而在降低KV缓存显存占用的前提下获得更好的性能。
DeepSeek V3.2 稀疏注意力机制
标准的 Transformer Attention 在处理 128K 甚至更长 Context 时,KV Cache 的显存占用和计算量是线性的甚至是平方级的,现有的稀疏方案往往会牺牲精度。
DSA(DeepSeek Sparse Attention,稀疏注意力):基于MLA用一个小模型(Indexer)去指挥大模型该看哪里,将主模型的注意力复杂度从O(L^2)下降到O(Lk),极大地降低了长序列上的成本。
核心组件:DSA 主要由两部分组成:
- Lightning Indexer (闪电索引器):Indexer 是一个轻量级的 Head,通常使用 FP8 精度计算极快。它负责计算当前 Query与历史 Token 的索引分数。即引入一个轻量级的 Lightning Indexer,专门负责为每个 Query Token 动态地选取 Top-K 个最相关的 key-value tokens,极大地减少计算量。
- Fine-Grained Token Selection(细粒度选择):基于上一步计算出的索引分数为每个 Query Token 动态地选取 Top-K 个最相关的 key-value tokens,高效计算 attention 输出。
- 标准的多头注意力 MHA 的复杂度是,每个 Query Token 需要和历史的所有 Token 计算 Attention;而 DSA 意味着 Attention 层的计算不再是全量的,而是稀疏的,只需要与Indexr选择出来的Top-K个 key-value tokens计算Attention。
在训练阶段,DeepSeek 采用了 “Dense Warm-up” -> “Sparse Training” 的两阶段策略:
- Warm-up:冻结主模型,只训练 Indexer。利用 KL 散度损失,让 Indexer 的输出分布去逼近全量 Attention 的分布。
- Sparse Training:解冻主模型,利用 Indexer 选出的稀疏 KV 进行端到端训练 。
官方文档显示在 H800 GPU 集群上测试显示,无论是在 prefilling 还是 decoding 阶段,单位 token 成本都有大幅下降。在 128K 长上下文下,单位 token 成本最高下降达 60%~70%。
Qwen3-Next 混合注意力机制
核心亮点如下所示:
- 混合注意力架构(Hybrid Attention):3层线性注意力 + 1层传统注意力,长文本下训推成本大幅度降低。
- 超稀疏MOE:512专家仅激活11个,80B参数仅激活3B。(DS R1 258-8,专家激活比例1/32;Qwen3-next 512-11,专家激活比例1/46)。
- 引入 MTP 机制,通过并行生成,一次输出多个 tokens;再进行后验证,实现显著速度提升。
- 全新的归一化方式 Zero‑Centered RMSNorm。
传统的 Transformer 模型使用 Softmax 注意力机制,需要在生成每个 token 时扫描所有历史 token,这导致了 O(L²) 的计算复杂度。随着序列长度增加,计算成本急剧上升。
线性注意力的演进:从理论到 DeltaNet
- 线性注意力通过去除 Softmax 操作实现高效计算,降低了复杂度(O(L²d) → O(Ld²)),但存在根本性缺陷
- “有损压缩”问题:线性注意力本质上是对历史信息的压缩,无法精确保存所有细节
- 大海捞针能力缺失:在需要从长文本中精确检索特定信息时表现较差
- 级联影响:大海捞针能力 → In-Context Learning 能力→ 指令遵循能力→ 长思维链思考能力&工具调用能力
- DeltaNet 通过引入 Delta 规则(源自神经网络学习理论)部分,实现了数学基础优化、并行化算法创新、神经网络架构改进等方式缓解了这些问题
- Qwen3-Next 采用了混合注意力架构 Gated Attn = 3:1,这一设计基于深刻的理论洞察
- 关键能力保持:25% 的 Softmax 层足以维持”大海捞针”能力,也就保持了 In-Context Learning 能力和由此衍生出的长思维链思考、工具调用等各种高阶能力。
- 计算效率最大化:75% 的线性层大幅降低计算成本
- 实验验证:在多个基准测试中,3:1 比例展现最佳性价比

具身智能模型
什么是具身智能?
具身智能(Embodied Artificial Intelligence,简称EAI),通常指通过机器人等物理实体与环境交互,能进行环境感知、信息认知、自主决策和采取行动,并能够从经验反馈中实现智能增长和行动自适应的智能系统。具身智能的实现主要包括感知、决策、控制三个主要环节。
- “具身”是前提,即具有身体且能通过交互、感知、行动等能力来执行任务,具身本体的形态不必限制在外观上的“人形”,同时身体的形态也不能作为判断是否属于“具身智能”的依据。根据使用用途和场景的不同,具身智能可以有多种形态。例如,通用智能机器人,大型的工业设备加上 AI系统,自动驾驶等多种具象化形态都属于具身智能。
- “智能”是核心,GPT-4o、Sora 等 AI 技术的最新进展,实现了对文本、视觉、语音等多模态信息的理解和转换。将这些 AI 技术嵌入到物理实体如机器人上,可显著提升对环境的感知、交互和任务执行能力。先前的智能机器人,更侧重于执行特定的任务。而具身智能更强调在环境中交互能力,智能表现在物理实体能以“第一人称”主动进行感知、理解、推理、规划到移动和操作等任务。
具身智能、机器人、智能体 对比如下所示:
- 具身智能不等于“大模型+机器人”。大模型具备思维推理、计划决策、语言和视觉理解等能力,这仅能模拟大脑皮层部分功能分区的智力表现。脑、身体和环境的深度耦合是产生高级认知的基础。这需要构建新一代人工智能算法,结合了脑神经、运控控制等复杂理论,推动具身智能实现认知涌现。
- 具身智能不等于人形机器人,从载体看具身智能可以是搭载到任意形态的机器人。人形机器人只是具身智能的一种形态,也被广泛认为是最理想的应用形态。但除此之外,比如能在家庭中行驶并与人简单交互的宠物机器人、比如L4自动驾驶,本质上都同时具备具身和智能两种属性。
- 具身智能不等于智能体,两者各有交叉和侧重。智能体(Agent)是指能自主感知环境并在该环境中采取行动以实现特定目标的实体,更强调自主性和目标导向性。智能体既可以是虚拟世界中的计算机程序(软件智能体),如聊天机器人ChatGPT、虚拟助手苹果Siri等;也可以存在于物理世界的智能实体,如智能机器人。具身智能则强调智能体的具体形态和环境之间的交互作用,通过行动的物理交互能够感知和改变环境,通过行动反馈能不断学习和适应环境。具身智能的主要存在形式是物理世界中的各种物理实体。
具身智能的技术路线如下所示:
- 具身智能系统主要包含大脑、小脑和身体三个部分。
- 大脑负责感知、理解和规划,主要通过大语言模型、视觉语言模型来驱动;
- 小脑负责运动控制和动作生成,主要通过运动控制算法、反馈控制系统来实现;
- 身体负责动作执行,由机器人本体(包含机械结构、传感器、执行器等)来支持。
- 算法方案
- 分层决策模型: 将任务分解成不同层级,以多个神经网络训练,再以流程管线的方式组合。例如Figure和OpenAI合作的Figure 01机器人,顶层接入OpenAl的多模态大模型,提供视觉推理和语言理解;中间层神经网络策略作为小脑进行运动控制并生成动作指令;底层机器人本体接受神经网络策略的动作指令,进行控制执行。分层决策模型的缺点是: 不同步骤间的对齐和一致性需解决。
- 端到端模型: 以Google RT-2为代表,通过一个神经网络完成从任务目标输入到行为指令输出的全过程。首先在大规模互联网数据预训练视觉语言模型然后在机器人任务上微调,结合机器人动作数据,推出视觉语言动作模型。RT-2不仅负责最上层的感知与规划,还参与中下层的控制与执行打通了端到端的链路。端到端模型的缺点是:训练数据海量、消耗资源巨大、机器人执行实时性差。
- 训练方法
- 模仿学习: 智能体通过观察和模仿专家 (经验丰富的人类操作者或具有高级性能的系统) 的行为来学习任务。
- 优势:可以快速学习专家策略,无需复杂的探索过程;
- 劣势:学习到的行为策略受限于专家数据,对于未见过的情况泛化能力较差。
- 强化学习: 智能体通过与环境的交互来学习最佳行为策略,以最大化某种累积奖励。
- 优势:能够通过探索环境学习未知的策略,且可以处理高度不确定和动态变化的环境;
- 劣势:需要大量的探索和试错,学习过程缓慢,且对于复杂任务,设计合适的奖励函数难度较高。
- 模仿学习: 智能体通过观察和模仿专家 (经验丰富的人类操作者或具有高级性能的系统) 的行为来学习任务。
- 数据采集
基于仿真环境的数据采集: Sim2Real(Simulation to Reality)在仿真环境中学习技能和策略,并迁移到现实世界中。
- 优势:数据可大规模获取,成本低;
- 劣势:对仿真器要求高,仿真环境与真实世界存在差异,迁移过程中存在性能下降。
基于真实世界的数据采集:直接从现实世界数据中学习,包括本体采集、遥操作、动态捕捉、视频学习等方式。
- 优势:数据更真实可靠;
- 劣势:数据少、泛化性差,通过机器本体和人采集,成本高、难度大、效率低。
具身智能模型
具身智能中最常用的“算法能力栈”从下往上串起来:
- 底层是工程工具与几何/标定/控制这类决定系统能否稳定运行的基础;
- 中层是视觉与多模态表征(2D/3D/4D、prompting、affordance),它们把复杂世界压缩成可泛化、可对齐、可被策略利用的中间表示;
- 上层则是学习与决策(RL/IL、VLA、LLM+Planner、快慢系统),把感知与任务目标转成可执行动作,并逐步走向更长程、更通用、更可部署的系统形态。
Vision Foundation Models 视觉基础模型
- 作用:成为具身智能系统的重要感知支柱。并不直接输出动作,但通过提供高质量、具有语义一致性的视觉表征,显著降低了下游任务(检测、分割、跟踪、位姿估计、操作规划)的难度。
- 核心价值:不在于“替代控制”,而在于将复杂世界压缩成结构化、可泛化的感知表示。
- 典型模型:DINO
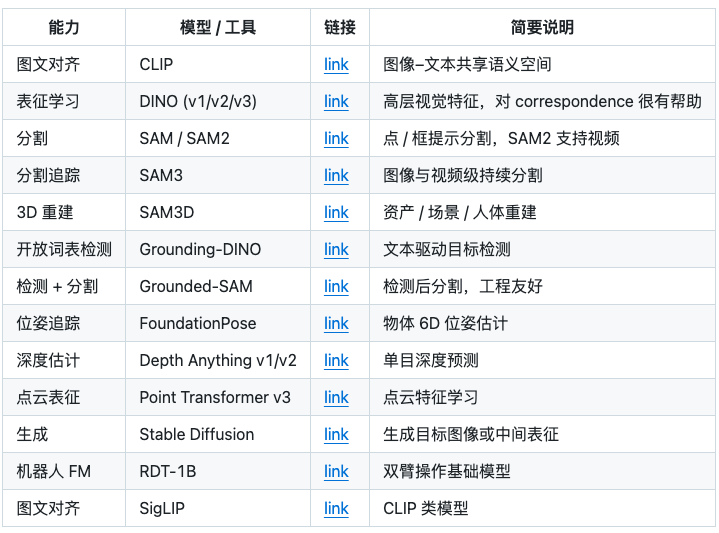
LLM For Robotic 大语言模型在机器人中的应用
- 作用:体现在高层语义理解与任务组织。把自然语言指令转成结构化计划,或者与传统规划器、3D 感知模块协作形成“可执行”的中间表示。需要强调的是在多数可落地系统中,LLM 并不直接输出低层控制量,而是充当高层策略/规划器或工具调用与代码生成器。如果更关心“离落地更近”的通用策略(而不是纯 LLM 规划),通常会与 VLA / 通用控制模型一起看:
- 核心价值:LLM 在机器人里的定位通常是高层理解 + 规划 + 工具调用,与传统规划/约束或 VLA 低层执行配合,系统更可控、更可复现。
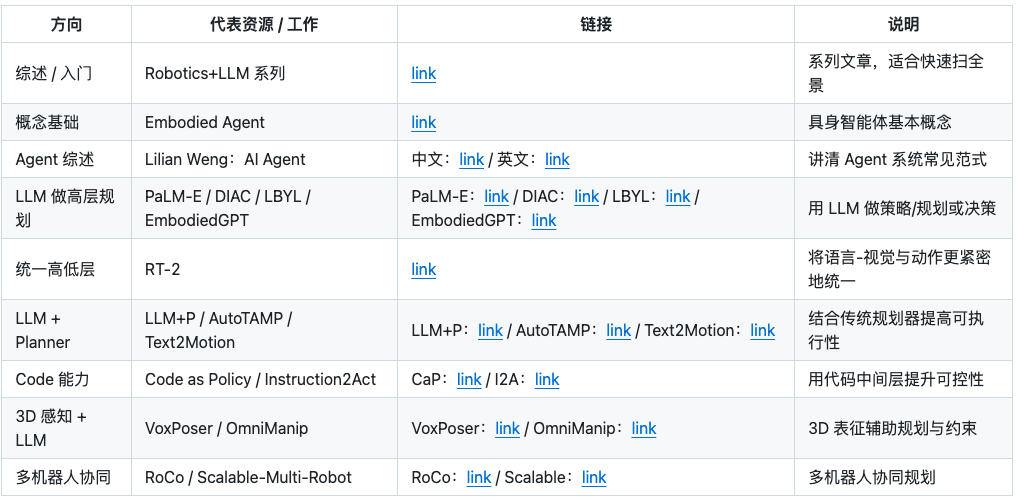
Vision - Language-Action Models VLA 模型在机器人领域的应用
VLA(Vision-Language-Action):可以理解为“把视觉-语言模型的能力直接延伸到动作空间”。与“VLM 做 planning”不同,VLA 的目标是更端到端:输入视觉与语言,输出可执行动作(或动作序列)。实现上通常涉及一个关键步骤:**动作表示(Action Representation)**把连续控制量或轨迹转成模型可学习的 token/latent,并设计动作头(autoregressive、diffusion、flow 等)完成生成。
从实践角度看,VLA 的差异往往来自三件事:
动作如何表示与量化(例如 tokenizer / FAST / latent action)
训练数据与对齐方式(真实/仿真/合成,多机型/多任务)
系统形态(单模型端到端 vs 分层双系统,是否引入 planner、world model 等)
近一年非常强的范式是“分层双系统”:
- System 2(慢系统)负责理解与规划(通常是 VLM/LLM),输出语言/符号/latent 的中间表示;
- System 1(快系统)负责高频、稳定的低层控制(VLA / policy),将中间表示转成连续动作;
- 它的直观优势是:在长任务与复杂场景中,把“推理/规划”与“高频控制”解耦,既提升可解释性,也更易做工程约束与安全策略;
VLA 的研究正在从“把动作 token 化”走向“更可控、更可部署、更长程”的系统形态:分层架构、world model、3D 表征与安全对齐都在加速融合。
Computer Vision 计算机视觉模型
具身智能几乎所有下游能力(抓取、操作、导航、交互)都建立在视觉之上。和纯 CV 不同,具身更关心的是:在变化的光照、遮挡、视角、运动模糊与跨域条件下,视觉表征是否稳定,以及它是否能与几何(深度/点云)和语言(指令/目标)对齐。
- 对具身而言,CV 不只是分类/检测,而是提供可用于交互与决策的稳定表征:2D 打底,3D 提供几何约束,4D 提供跨时间一致性,视觉输出变成“可执行”的中间表示。
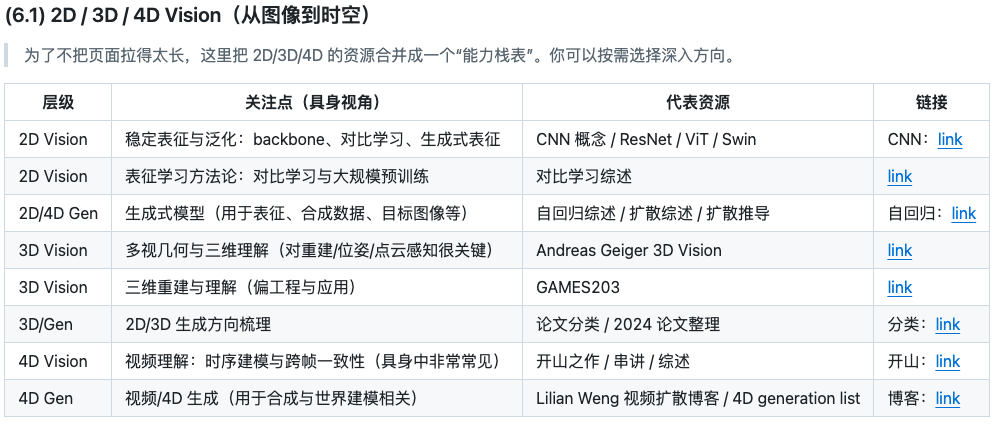
Computer Graphics 计算机图形学(方针、重建与可渲染的入口)
- 图形学在具身中的价值通常体现在三类事情:
- 仿真与渲染:低成本生成交互数据;
- 重建:把现实转成可学习的资产;
- 新型表示:如 NeRF / 3DGS 带来的可微与高效渲染,正在影响数据合成与世界建模。
图形学更像“具身的数据与世界接口”:它决定了你能否把场景/资产做成可复现、可扩展、可规模化的训练资源。
Multimodel 多模态模型(视觉、语言、时序的统一表征)
- 具身系统中常见的输入是视觉(RGB/Depth/点云)与语言(目标与约束),并且往往伴随强烈的时序依赖。多模态模型的核心作用是:把这些信息压缩成一个统一表征空间,使得系统能够在“看懂 + 听懂 + 记住”的前提下做决策与控制。
- 多模态并不是“把模态拼起来”,而是解决对齐与一致性:对齐让语言可控,一致性让跨时间的决策更稳定。

World Model 世界模型
- 世界模型是用于理解现实世界动态 (包括物理属性和空间属性) 的神经网络。它们可以使用文本、图像、视频和运动等输入数据来生成模拟实际物理环境的视频。 物理AI开发者可以使用世界模型来生成自定义合成数据或下游 AI 模型,用于训练机器人和智能汽车。
- 核心目标:是让AI系统能够像人类一样,在内部构建一个对外部物理环境的模拟和理解 。通过这种方式,AI可以在“脑海”中模拟和预测不同行为可能导致的后果,从而进行有效的规划和决策。例如,一个具备世界模型的自动驾驶系统,可以在遇到湿滑路面时,预判到如果车速过快可能会导致刹车距离延长,从而提前减速,避免危险。这种能力源于AI内部对物理规律(如摩擦力、惯性)的模拟,而不是简单地记忆“湿滑路面要减速”这条规则。
- 预测模型 (Prediction Models): 这些模型能够基于文本提示、输入视频,或通过对两张图像进行插值来预测世界场景的生成,并合成连续的运动。它们能够生成逼真且在时间维度上连贯的场景,对于视频合成、动画和机器人运动规划等应用非常重要。
- 风格迁移模型 (Style Transfer Models): 这些模型使用 ControlNet 根据特定输入来引导输出结果,ControlNet 是一种模型网络,基于结构化指导 (如分割图、激光雷达扫描、深度图或边缘检测) 来调节模型的生成。通过直观地镜像输入指令,这些模型可以控制布局和运动,同时根据文本提示生成多样化的逼真结果。这使得它们在需要 结构化图像或视频合成的应用中起到重要价值,例如数字孪生仿真和环境重建。
- 推理模型 (Reasoning Models): 这些模型采用多模态输入,并随时间和空间进行分析。他们使用基于强化学习的思维链推理来了解正在发生的情况并决定最佳行动。这些模型有助于 AI 处理复杂的任务,例如区分真实数据和合成数据、为机器人或游戏选择有用的训练数据、预测机器人动作以及优化自主系统物流。
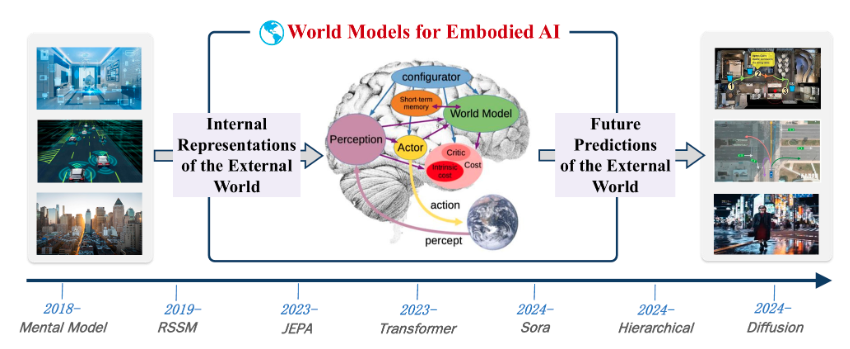
- SORA 、MovieGen 、Wan2.1 这样的大规模生成式视频模型,在其他条件(如文本或动作)下也可被视为世界模型
DSV4 or Model1 未来会做什么?
engram paper
- engram:神经科学的术语,在大脑中存储记忆的物理结构,意在要给大模型装上“记忆”。
- 背景:在传统的 Transformer 架构中,模型并不具备显式的知识查找机制。对于一些常识性知识,模型需要通过 FFN 或者 MoE 模块计算来“模拟”一次检索过程,这种方式计算效率低下(理解case:模型看到Diana,Princess of wales时,模型内部发生的变化如下。即DS认为大模型浪费了大量的网络深度去做一些重复性的背书工作,浪费了算力)。为了解决这一问题,DeepSeek-AI 在 Transformer 架构中引入了** Engram 模块,用于注入固定知识,从而减少不必要的计算**负担。
- Engram核心实现路径:“查表”。模型看到Alexander the Great三个词连在一起的时候,就类似看到了字典的索引词,从而用哈希定位到字典里对应的那一页,把预先存好的信息拿出来用,整个过程不需要思考,只需要翻页。为了避免同一个词在不同的语境会有不同的含义,engram会进一步查看上下文,看是否有关联关系,符合则使用,不符合则忽略该“查表”结果。即对每个输入的 token,将以当前 token 为结尾的 2-gram、3-gram 做 embedding 后拼接。然后将结果融合进 transformer 数据流,就能一定程度上避免模型“计算出常识”这样的问题。
- MoE和Engram如何分配?总参数量固定的情况下,应该把多少参数分给MoE,多少参数分给Engram记忆,结果是损失呈现U型能力。即纯Moe都是思考能力,并不是最优的,分配20%-25%给到Engram效果最好,分配过多给到engram效果也会下降——记忆和思考是互补的,通过记忆释放出算力进行更有价值的更深度的推理。
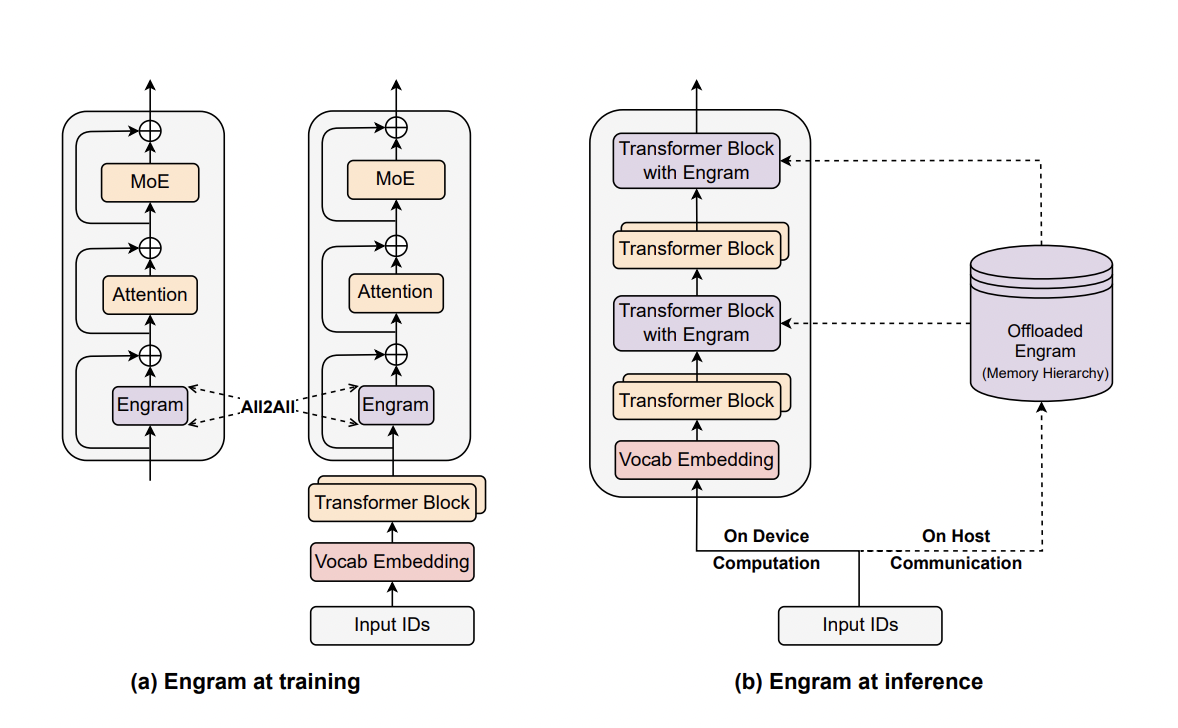

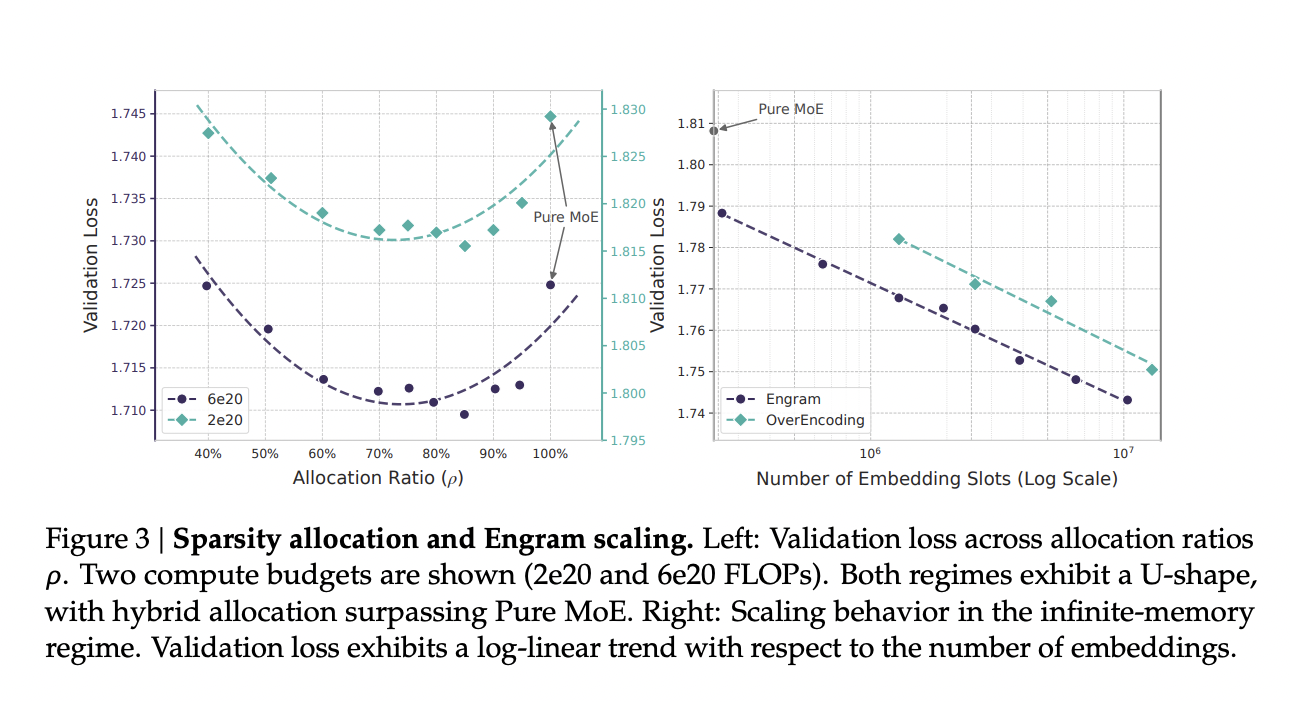
目标:增强模型的长上下文处理能力。与上文Attention 机制的差异?
- Attention:query 会与历史上所有 key 计算注意力分数。例如在股票交易中,当前时刻的交易决策可能会参考过去所有时刻(如上市十年间的全部数据)的股价信息。
- Engram:可看作一种长短时特征学习机制。仍以股票交易为例,短期内的标志性事件(如当日曝出企业财务造假新闻)所产生的影响是可预测的——在新闻发布前后,存在一段可被观测的隐藏短期时序模式。Engram 正是对这种短时序特征进行建模的方法,
总结:Engram所捕捉的短时序特征,即 Conditional Memory,并非通常直观理解中的长程记忆处理方式。Attention 本身可通过注意力权重的分布自然体现长短时偏好,而 Engram则在此基础上,显式地引入了一种短时序建模机制。Engram并非用于取代 Attention,Engram对标的模块应当是类似 MoE(FFN) 一类的特征学习,引入记忆学习 则可以看成是一种参数 Scaling 或增加模型容量的手段。
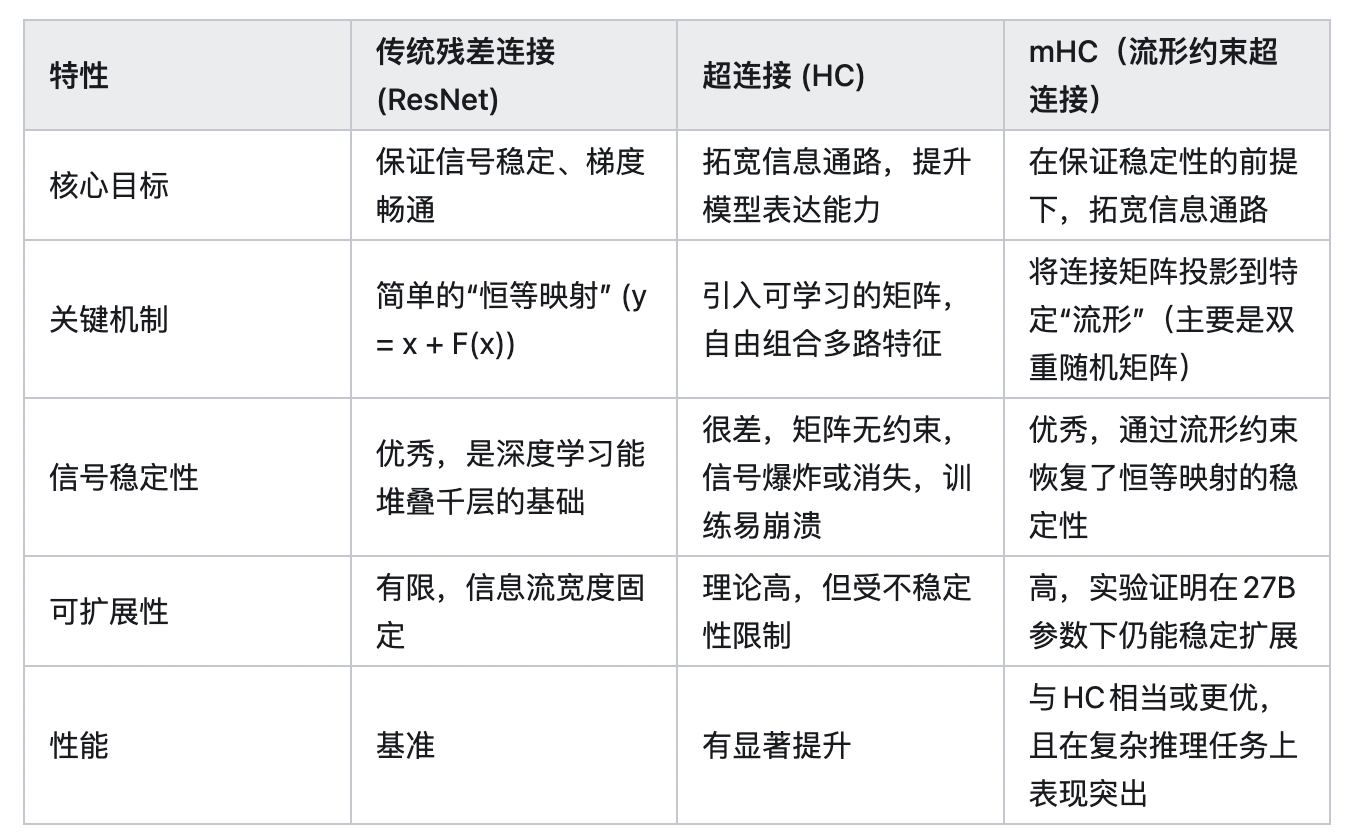
mHC: Manifold-Constrained Hyper-Connections
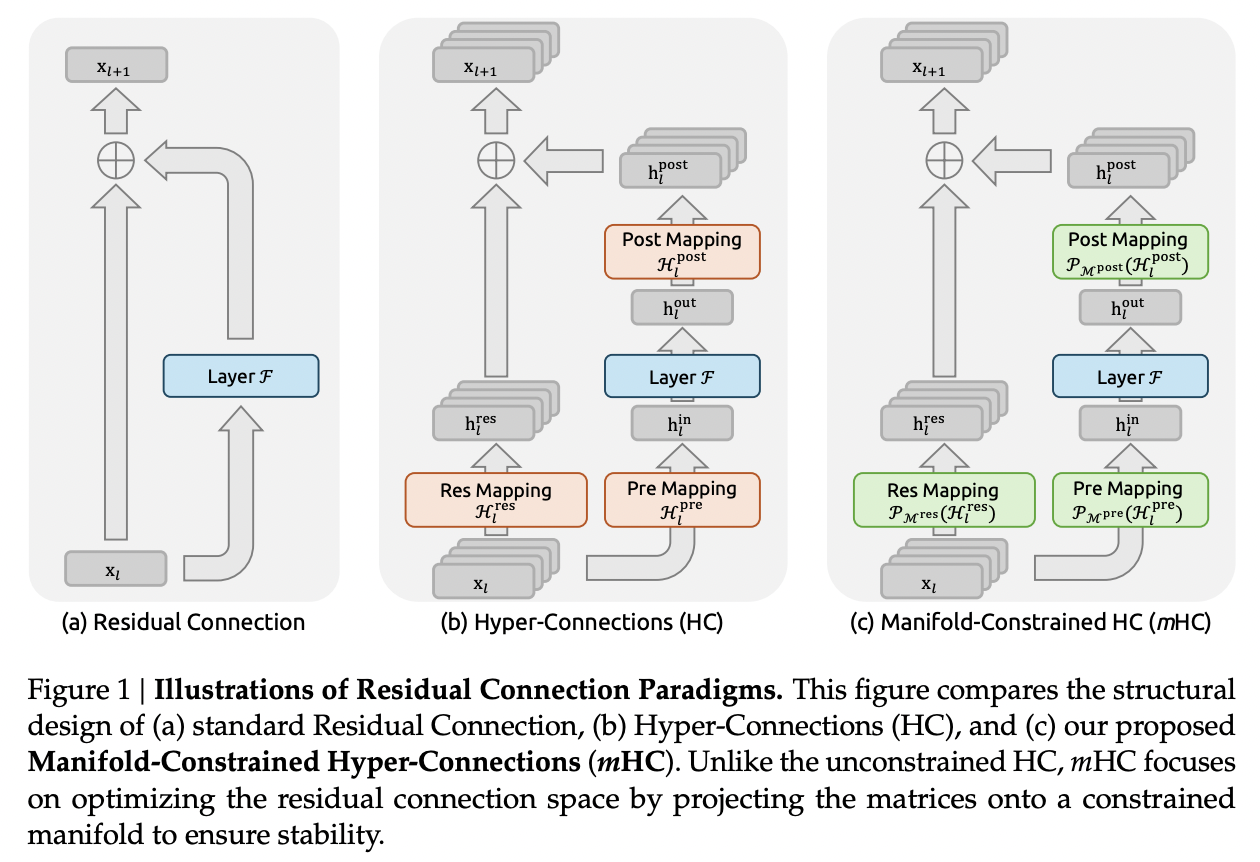
- 背景:ResNet 引入残差链接方式,解决深层神经网络中的梯度消失/爆炸和网络退化问题,使得训练极深的网络成为可能,即每一层的输出等于这一层学到的内容加上最开始的输入。从2015至今GPT、Gemini等均使用残差链接,25年9月字节抛出了HC(Hyper Connection),让模型自己学习最优的链接方式。HC的方式大幅提升了训练的收敛速度,但是会出现训练不稳定的情况。
- 痛点:“跷跷板”困境,即增强模型的表达能力,往往意味着牺牲训练的稳定性。Hyper-Connections(HC)技术就是一个典型,通过拓宽神经网络内部的“信息高速公路”,显著提升了模型性能,却也因信号在千层网络中的失控放大(高达3000倍) 而变得难以驯服,因为一个向量,如果经过了许多矩阵乘(线性变换),它的大小就会变得不稳定,可能会过大(如果这些矩阵“过大”),也可能会过小(如果这些矩阵“过小”),成为大规模训练的“隐形炸弹”。这就让 Residual 所解决的梯度爆炸、梯度消失的问题又重新成为了一大隐患;
- DS的mHC:DeepSeek最新提出的mHC(流形约束超连接)架构,是一项旨在解决大模型深层训练中稳定性难题的底层创新。它的核心思路是,在不牺牲性能提升的前提下,通过数学上的“流形约束”,让复杂的超连接网络重回稳定。
- 具体实现:对这些矩阵进行限制,在这种限制下,这些矩阵对向量的作用,即使经过了许多层,也能保持其元素数值的稳定。mHC 采用的限制就是让这些矩阵是 doubly stochastic 的,即所有元素都是非负的,并且每行元素的和、每列元素的和都是 1。doubly stochastic 矩阵相乘还是 doubly stochastic 的,这就使得向量在多轮变换之后,模不会变得很大或很小。同时 doubly stochastic 矩阵也能充分地混合 n 维的信息,使其仍具有 HC 中的作用。另外,如果取 n=1,那么这个 doubly stochastic 矩阵(1 x 1)一定是 1,从而退化到 Residual 的场景。
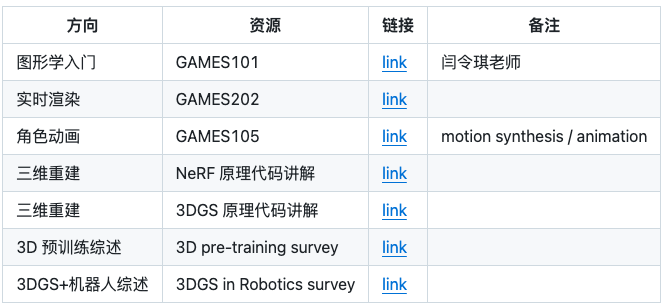
更多详情信息如下所示:
- 论文:https://github.com/deepseek-ai/Engram/blob/main/Engram_paper.pdf
- 论文:https://arxiv.org/abs/2512.24880